RegNetY
![]()
TensorFlow 2.x implementation of RegNet-Y from the paper "Designing Network Design Spaces".
Announcement
RegNets are now available in tf.keras.applications! Check them out here. This repository is no longer maintained.
About this repository
This implementation of RegNet-Y is my project for Google Summer of Code 2021 with TensorFlow[1].
Salient features:
- Four variants of RegNet-Y implemented - 200MF, 400MF, 600MF, 800MF.
- TPU compatible: All models are trainable on TPUs out-of-the box.
- Inference speed: All models boast blazing fast inference speeds.
- Fine-tuning: Models can be fine-tuned using gradual unfreezing and offer more granularity by using the released checkpoints.
- Modular and reusable: Every part of the architecture is implemented by subclassing
tf.keras.Model. This makes the individual parts of the models highly reusable. - Trained on ImageNet-1k: Models in this repository are trained on ImageNet-1k and can be used for inference out-of-the box. These pretrained models are available on TFHub and thus can be easily used with
hub.KerasLayerandhub.load. - Raw checkpoints and tflite models are available in the dev branch.
Table of contents
Introduction to RegNets
About the paper
The paper "Designing Network Design Spaces" aims to systematically deduce the best model population starting from a model space that has no constraints. The paper also aims to find a best model population, as opposed to finding a singular best model as in works like NASNet.
The outcome of this experiment is a family of networks which comprises of models with various computational costs. The user can choose a particular architecture based upon the need.
About the models
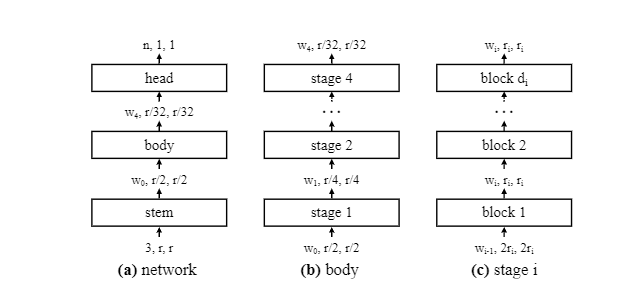
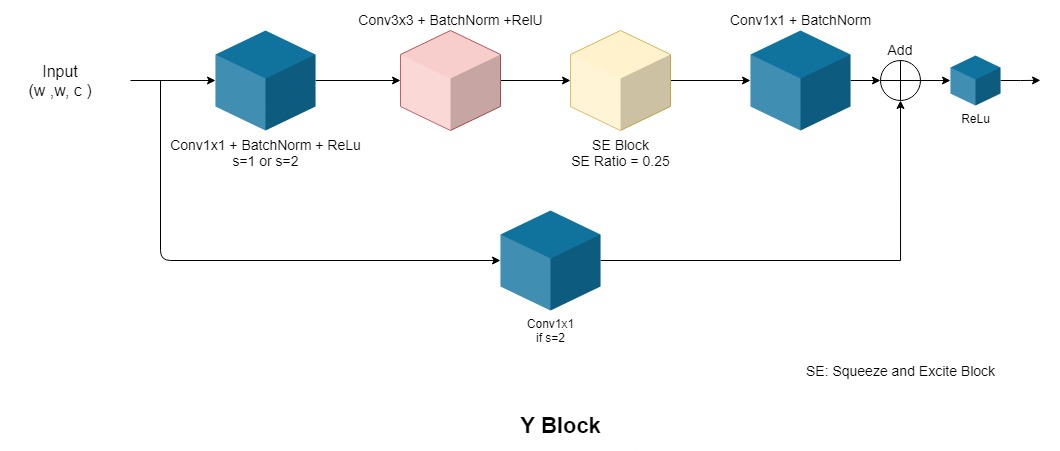
Every model of the RegNet family consists of four Stages. Each Stage consists of numerous Blocks. The architecture of this Block is fixed, and three major variants of this Block are available: X Block, Y Block, Z Block[2]. Other variants can be seen in the paper, and the authors state that the model deduction method is robust and RegNets generalize well to these block types.
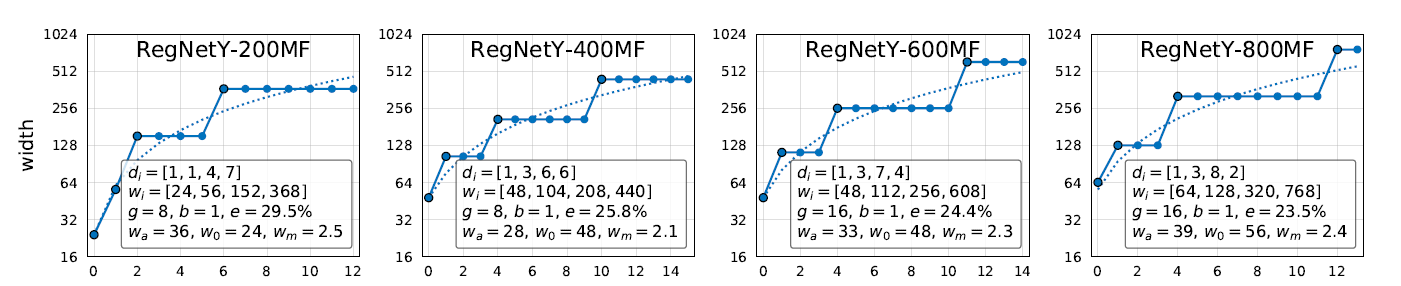
The number of Blocks and their channel width in each Stage is determined by a simple quantization rule put forth in the paper. More on that in this blog.
RegNets have been the network of choice for self supervised methods like SEER due to their remarkable scaling abilities.
RegNet architecture:
Y Block:
Model statistics
| Model Name | Accuracy (Ours/ Paper) | Inference speed (images per second) | FLOPs (Number of parameters) | Link | |
| K80 | V100 | ||||
| RegNetY 200MF | 67.54% / 70.3% | 656.626 | 591.734 | 200MF (3.23 million) | Classifier, Feature Extractor |
| RegNetY 400MF | 70.19% / 74.1% | 433.874 | 703.797 | 400MF (4.05 million) | Classifier, Feature Extractor |
| RegNetY 600MF | 73.18% / 75.5% | 359.797 | 921.56 | 600MF (6.21 million) | Classifier, Feature Extractor |
| RegNetY 800MF | 73.94% / 76.3% | 306.27 | 907.439 | 800MF (6.5 million) | Classifier, Feature Extractor |
MF signifies million floating point operations. Reported accuracies are measured on ImageNet-1k validation dataset.
Usage
![]()
1. Using TFHub
This is the preferred way to use the models developed in this repository. Pretrained models are uploaded to [TFHub](). See the colab for detailed explaination and demo. Basic usage:
model = tf.keras.Sequential([
hub.KerasLayer("https://tfhub.dev/adityakane2001/regnety200mf_feature_extractor/1", training=True), # Can be False
tf.keras.layers.GlobalAveragePooling(),
tf.keras.layers.Dense(num_classes)
])
model.compile(...)
model.fit(...)2. Reloading checkpoints from training
One can easily load checkpoints for fine-grained control. Here's an example:
!pip install -q git+https://github.com/AdityaKane2001/regnety@main
from regnety.models import RegNetY
# One function call and it's done!
model = RegNetY(flops="200mf", load_checkpoint=True) #Loads pretrained checkpoint
model.compile(...)
model.fit(...)Known caveats
- The models achieve lower accuracies than mentioned in the paper. After substantial scrutiny we conclude that this is due to the difference in internal working of TensorFlow and PyTorch. We are still trying to increase the accuracy of these models using different training methods.
- These models cannot be trained on a CPU. One can run inference on the models by strictly using batch_size=1. The models function as expected on GPUs and TPUs. This is because grouped convolutions are not supported for training by TensorFlow (as of 2.6.0).
What's next?
If you have any suggestions, feel free to open an issue or start a PR. Following is the list of things to be done in near future.
- [x] Improve accuracy of the models.
- [x] Convert existing models to TFLite.
- [x] Implement and train more variants of RegNetY.
- [ ] Training models using noisy student method.
- [x] Implement and train RegNet-{X, Y}
Acknowledgement
This repository is my project for Google Summer of Code 2021 at TensorFlow. Project report is available here.
Mentors:
- Sayak Paul (@sayakpaul)
- Morgan Roff (@MorganR)
I thank Google Summer of Code and TensorFlow for granting me this opportunity. I am grateful to my mentors Sayak Paul and Morgan Roff for their continuous guidance and encouragement. Without them this project would not have been possible. I also thank TPU Research Cloud (TRC) for providing high performance TPUs for model training. Lastly, I thank TensorFlow Hub for making the models widely available.
References
[1] Project report here.
[2] Z Block is proposed in the paper "Fast and Accurate Model Scaling".