Listen to Look into the Future: Audio-Visual Egocentric Gaze Anticipation
ECCV 2024
Project Page | Paper
Contents
TODO:
- [x] Codes
- [x] Checkpoints
- [x] Data Split
- [x] Update README
- [ ] Update code of Aria dataset preprocessing
- [ ] Upload the list of Ego4D video ids for quick download
- [ ] Add codes for gaze estimation
- [ ] Visualization codes
We also have another work for egocentric gaze estimation. You can find more details here if you are interested.
Problem Definition
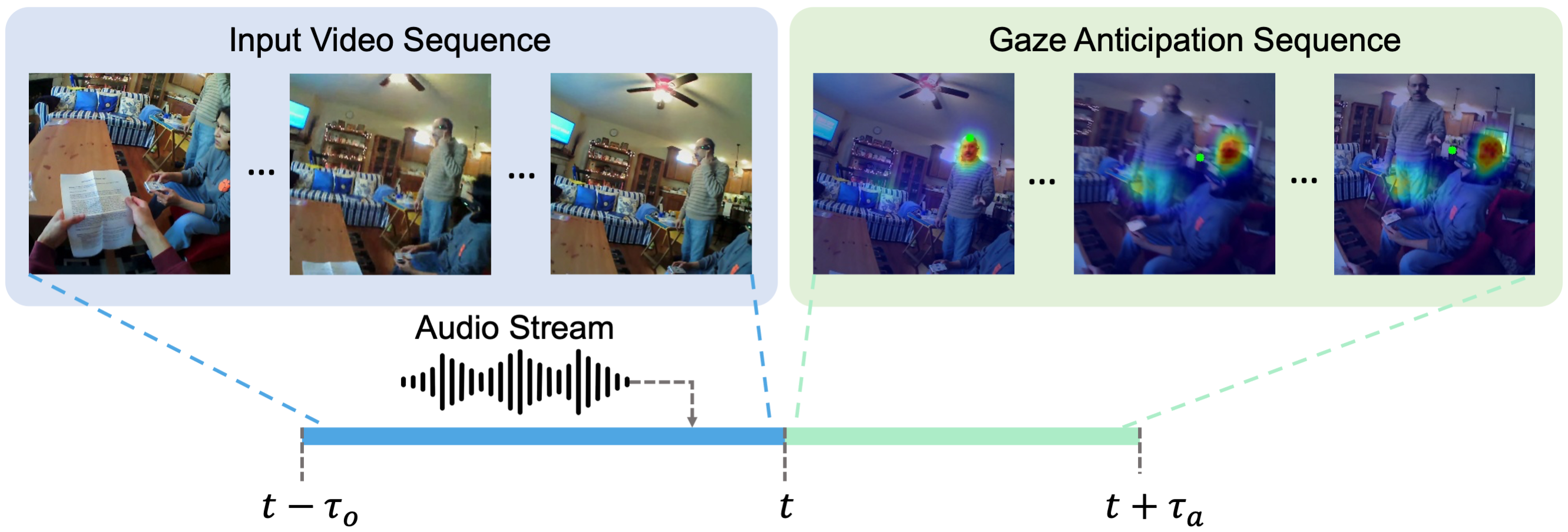
Approach
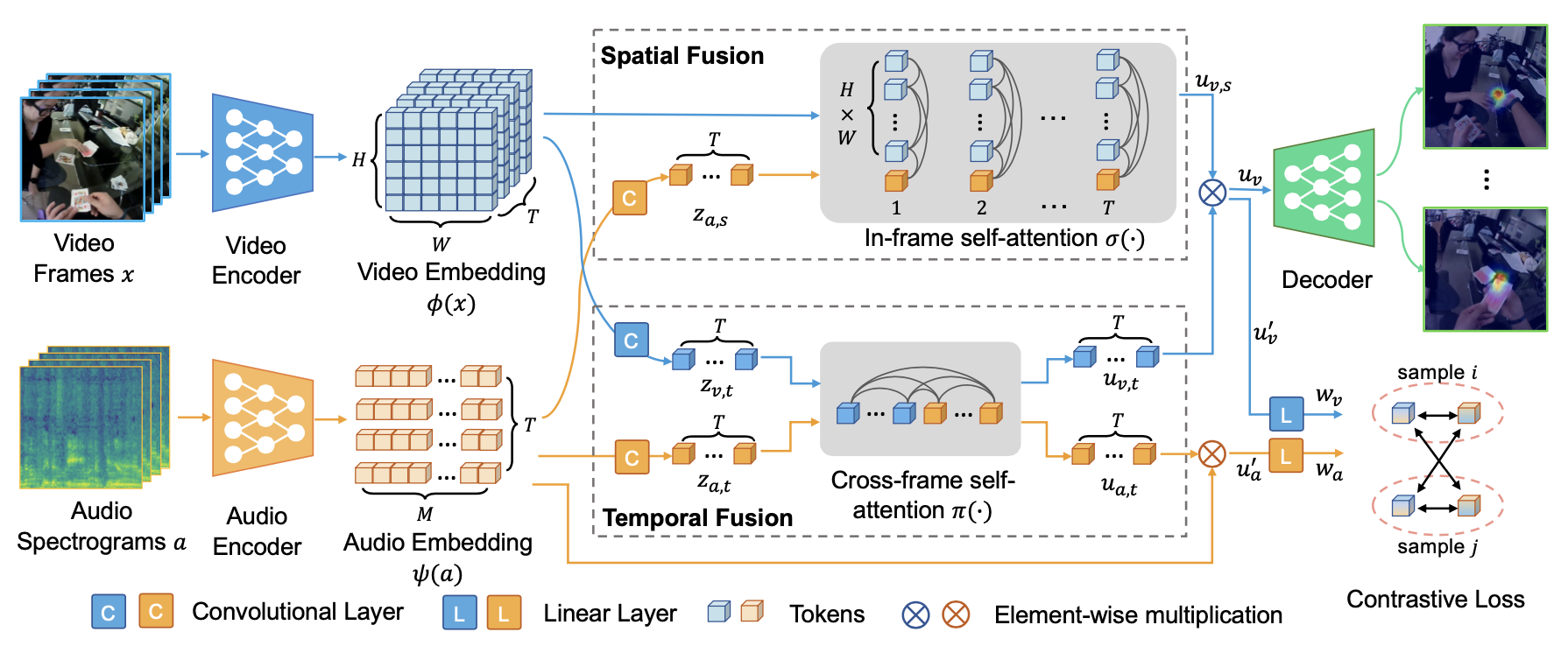
Setup
Set up the virtual environment using following commands.
conda env create -f virtual_env.yaml
conda activate csts
python setup.py build developDataset
We train our model using a subset of Ego4D and Aria Everyday Activities. The data split is released in data/*.csv.
Ego4D
We use the same split in our prior work which is also recommended by the official website. Please follow the steps below to prepare the dataset.
-
Read the agreement and apply for Ego4D access on the website (It may take a few days to get approved). Follow the instructions in "Download The CLI" and this guidance to set up the CLI tool.
-
We only need to download the subset of Ego4D that has gaze data. You can download all the gaze data using the CLI tool on this page.
-
Gaze annotations are organized in a bunch of csv files. Each file corresponds to a video. Unfortunately, Ego4D hasn't provided a command to download all of these videos yet. You need to download videos via the video ids (i.e. the name of each csv file) using the CLI tool and --video_uids following instructions.
-
Two videos in Ego4D subset don't have audio streams. We provide the missing audio files here.
-
Please reorganize the video clips and annotations in this structure:
Ego4D |- full_scale.gaze | |- 0d271871-c8ba-4249-9434-d39ce0060e58.mp4 | |- 1e83c2d1-ff03-4181-9ab5-a3e396f54a93.mp4 | |- 2bb31b69-fcda-4f54-8338-f590944df999.mp4 | |- ... | |- gaze | |- 0d271871-c8ba-4249-9434-d39ce0060e58.csv | |- 1e83c2d1-ff03-4181-9ab5-a3e396f54a93.csv | |- 2bb31b69-fcda-4f54-8338-f590944df999.csv | |- ... | |- missing_audio |- 0d271871-c8ba-4249-9434-d39ce0060e58.wav |- 7d8b9b9f-7781-4357-a695-c88f7c7f7591.wav -
Uncomment the Ego4D code block in
data/preprocess.py: main()and update the variablepath_to_ego4dto your local path of Ego4D dataset. Then run the command.python preprocess.pyThe data after preprocessing is saved in the following directories.
clips.gaze: The video clips of 5s duration.gaze_frame_label: The gaze target location in each video frame.clips.audio_24kHz: The audio streams resampled in 24kHz.clips.audio_24kHz_stft: The audio streams after STFT.
Aria
TODO
(The Aria dataset is in a very different format than it was when we started our work. We need more time to update our codes. Thank you for your patience.)
Model Weights
Model Weights for Ego4D: download
Model Weights for Aria: download
Training
We use MViT as our backbone. The Kinetics-400 pre-trained model is released here (i.e., Kinetics/MVIT_B_16x4_CONV). We find this checkpoint is no longer available on that page. We thus provide the pretrained weights via this link.
Train on Ego4D dataset.
CUDA_VISIBLE_DEVICES=0,1 python tools/run_net.py \
--init_method tcp://localhost:9880 \
--cfg configs/Ego4D/CSTS_Ego4D_Gaze_Forecast.yaml \
TRAIN.BATCH_SIZE 8 \
TEST.ENABLE False \
NUM_GPUS 2 \
DATA.PATH_PREFIX /path/to/Ego4D/clips.gaze \
TRAIN.CHECKPOINT_FILE_PATH /path/to/pretrained/K400_MVIT_B_16x4_CONV.pyth \
OUTPUT_DIR out/csts_ego4d \
MODEL.LOSS_FUNC kldiv+egonce \
MODEL.LOSS_ALPHA 0.05 \
RNG_SEED 21Train on Aria dataset.
CUDA_VISIBLE_DEVICES=0,1 python tools/run_net.py \
--init_method tcp://localhost:9880 \
--cfg configs/Aria/CSTS_Aria_Gaze_Forecast.yaml \
TRAIN.BATCH_SIZE 8 \
TEST.ENABLE False \
NUM_GPUS 2 \
DATA.PATH_PREFIX /path/to/Aria/clips \
TRAIN.CHECKPOINT_FILE_PATH /path/to/pretrained/K400_MVIT_B_16x4_CONV.pyth \
OUTPUT_DIR out/csts_aria \
MODEL.LOSS_FUNC kldiv+egonce \
MODEL.LOSS_ALPHA 0.05 \
RNG_SEED 21Note: You need to replace DATA.PATH_PREFIX with your local path to video clips, and replace TRAIN.CHECKPOINT_FILE_PATH with your local path to pretrained MViT checkpoint. You can also fix DATA.PATH_PREFIX in configuration files to shorten the command. The checkpoints after each epoch will be saved in ./out directory.
Evaluation
Run evaluation on Ego4D dataset.
CUDA_VISIBLE_DEVICES=0 python tools/run_net.py \
--cfg configs/Ego4D/CSTS_Ego4D_Gaze_Forecast.yaml \
TRAIN.ENABLE False \
TEST.BATCH_SIZE 24 \
NUM_GPUS 1 \
DATA.PATH_PREFIX /path/to/Ego4D/clips.gaze \
TEST.CHECKPOINT_FILE_PATH out/csts_ego4d/checkpoints/checkpoint_epoch_00005.pyth \
OUTPUT_DIR out/csts_ego4d/testRun evaluation on Aria dataset.
CUDA_VISIBLE_DEVICES=0 python tools/run_net.py \
--cfg configs/Aria/CSTS_Aria_Gaze_Forecast.yaml \
TRAIN.ENABLE False \
TEST.BATCH_SIZE 24 \
NUM_GPUS 1 \
DATA.PATH_PREFIX /path/to/Aria/clips \
TEST.CHECKPOINT_FILE_PATH out/csts_aria/checkpoints/checkpoint_epoch_00005.pyth \
OUTPUT_DIR out/csts_aria/testNote: You need to replace DATA.PATH_PREFIX with your local path to video clips, replace TEST.CHECKPOINT_FILE_PATH with the path of the checkpoint that you want to evaluate, and replace OUTPUT_DIR with the path of saving evaluation logs.
You may find it's hard to fully reproduce the results if you train the model again, even though the seed is already fixed. We also observed this issue but failed to fix it. It may be an internal bug in the slowfast codebase, which we build our own model on. However, the difference should be small, and you are still able to get the same number as reported in the paper by running inference with our released weights.
BibTeX
@inproceedings{lai2024listen,
title={Listen to look into the future: Audio-visual egocentric gaze anticipation},
author={Lai, Bolin and Ryan, Fiona and Jia, Wenqi and Liu, Miao and Rehg, James M},
booktitle={European Conference on Computer Vision},
pages={192--210},
year={2024},
organization={Springer}
}Acknowledgement
We develop our model based on SlowFast. We appreciate the contributors of that excellent codebase.