 BainanXia
commented
2 years ago
BainanXia
commented
2 years ago I like it! Thanks for the exploration with detailed explanation. A few comments from the design perspective which may or may not simplify the graph traversal logic due to complicated return structure:
- I'm wondering whether it will help if we build the tree exactly according to the one from Wikipedia's page, i.e. each blocks is compressed into one node with information stored in attributes. Then for block nodes, demand != 0 and for articulation points, capacity != 0. Here is an example of doing so, demonstrated by assuming all demand for block nodes are 1 and all branch capacities are 1.
class TreeNode: def __init__(self, name, demand, capacity): self.name = name self.demand = demand self.capacity = capacity self.children = []
def build_tree():
adj = {'b1': ['c1'],
'c1': ['b2', 'b3'],
'b2': [],
'b3': ['c2'],
'c2': ['b4'],
'b4': ['c3', 'c4'],
'c3': ['b5'],
'c4': ['b6', 'b7']
}
root = TreeNode('b1', 1, 0)
queue = [root]
for q in queue:
if q.name in adj and adj[q.name]:
for ch in adj[q.name]:
if 'b' in ch:
node = TreeNode(ch, 1, 0)
q.children.append(node)
queue.append(node)
else:
node = TreeNode(ch, 0, len(adj[ch]))
q.children.append(node)
queue.append(node)
return root
root = build_tree()
def dfs(root): sub_tree_demand = root.demand for c in root.children: sub_tree_demand += dfs(c) if 'c' in root.name: root.demand = sub_tree_demand return sub_tree_demand
The code snippet above will give us following results:
```python
def helper(root):
print(root.name, root.demand, root.capacity)
for c in root.children:
helper(c)
>>>helper(root)
b1 1 0
c1 6 2
b2 1 0
b3 1 0
c2 4 1
b4 1 0
c3 1 1
b5 1 0
c4 2 2
b6 1 0
b7 1 0Finally, we can simply go through all articulation points (node name with 'c' in it in the example above) to see whether node.demand > node.capacity, i.e. the bottleneck. Not sure whether this is what we want here.
- I think we should add a test for
find_descendantas well for the spirit of unit tests, which could potentially better demonstrates the logic flow.
 danielolsen
danielolsen
Pull Request doc
Purpose
Add a helper function which can identify where local transmission capacity is insufficient to meet local power needs. This was designed around seeing whether local (radial or semi-radial) transmission capacity was sufficient to import enough power from the bulk (meshed) grid, but could easily be extended to ensure that local transmission capacity is sufficient to export power to the bulk grid.
What the code is doing
The user-facing function is
identify_bottlenecks. It uses a branch dataframe to build a graph representing the transmission network, construct a block-cut tree of the biconnected components (see https://en.wikipedia.org/wiki/Biconnected_component#Block-cut_tree), and identify the largest biconnected component. These data structures are then passed tofind_descendants, and the return is filtered to output all potential bottlenecks (the"all"key of the output dict), plus bottlenecks where demand is greater than capacity (the"constrained"key of the output dict).find_descendantsis a recursive function which starts from aparentnode of a block-cut tree, optionally takes agrandparentnode which indicates which direction is 'upstream', and calculates for each edge of the block-cut tree (between an articulation point and a block) whether the total branch capacity between the articulation point and the block is sufficient to meet all downstream demand.identify_bottleneckspasses the largest biconnected component as the root, and thenfind_descendantscalculates the total demand downstream of each articulation point, by first calculating the total demand of the downstream block, etc. until it reaches the leaf nodes of the tree where there's nothing downstream, at which point the summation can start going back up the chain. Along the way back up, the set of all downstream nodes is built, and the local capacity between each articulation point and block.Testing
A unit test is added, based around an example from Wikipedia's page on biconnected components, plus some arbitrary demands and capacities.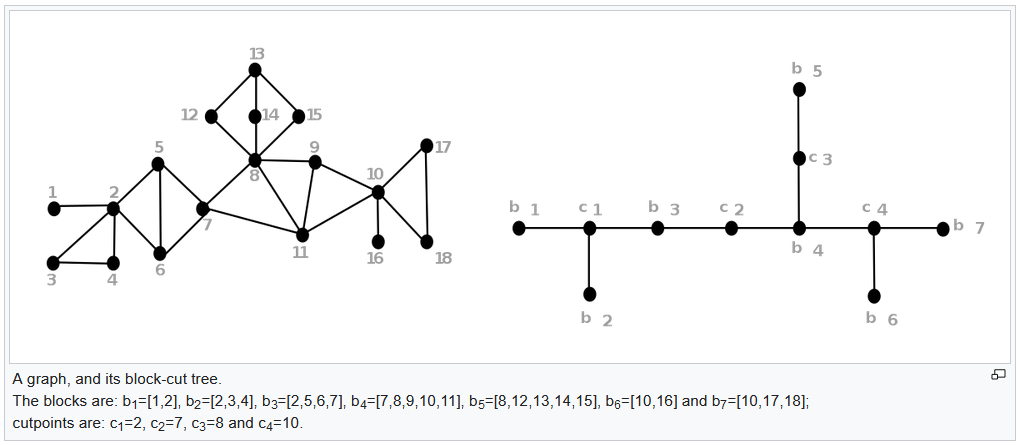
Usage Example/Visuals
Time estimate
Figuring out the graph traversal logic was a pretty big headache, if I were coming at this fresh I would expect to take more than an hour to understand it. Maybe some of you have more of an intuitive feel for graph traversal algorithms though.
I'm leaving this as a draft PR for now, since this logic is ready for review but we will probably want some higher-level logic that uses the results of the
identify_bottlenecksto aid in grid-building, besides just throwing warnings. That would require that we have demand profiles during grid-building though, which we currently don't have, so maybe we'll want to merge this now and wait for a follow-up later. I'm open to suggestions.