A framework for the real-time IP flow data analysis built on Apache Spark Streaming, a modern distributed stream processing system.
This project is no longer maintained
⚠ Project Stream4Flow is no longer maintained as the used frameworks are constantly evolving, and it is not in our capacity to continually update the installation scripts. If you're interested in other network data processing tools and our current research, check out CSIRT-MU repositories.
About Stream4Flow
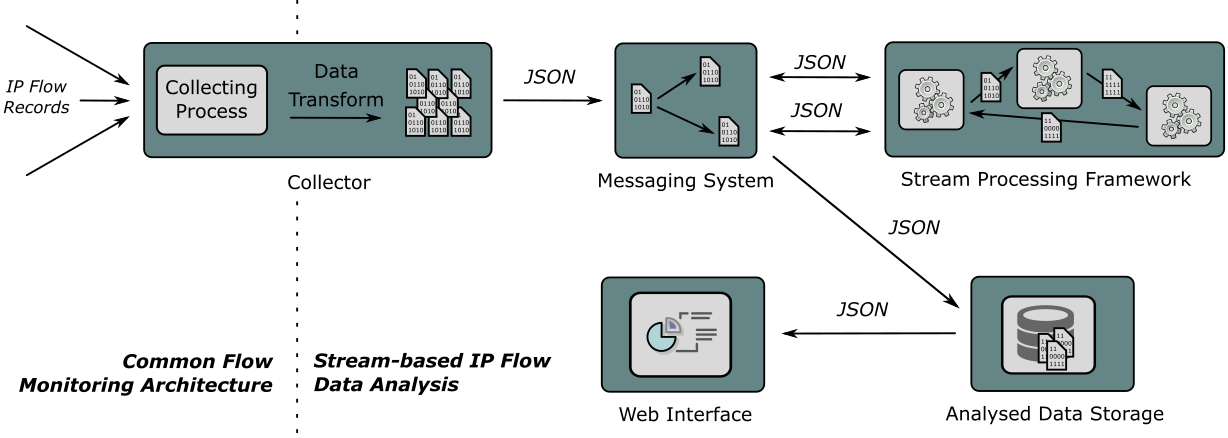
The basis of the Stream4Flow framework is formed by the IPFIXCol collector, Kafka messaging system, Apache Spark, and Elastic Stack. IPFIXCol is able to receive IP flows from a majority of network Netflow/IPFIX probes (e.g., Flowmon Probe, softflowd, etc.). IPFIXCol enables incoming IP flow records to be transformed into the JSON format provided to the Kafka messaging system. The selection of Kafka was based on its scalability and partitioning possibilities, which provide sufficient data throughput. Apache Spark was selected as the data stream processing framework for its quick IP flow data throughput, available programming languages (Scala, Java, or Python) and MapReduce programming model. The analysis results are stored in Elastic Stack containing Logstash, Elasticsearch, and Kibana, which enable storage, querying, and visualizing the results. The Stream4Flow framework also contains the additional web interface to make administration easier and visualize complex results of the analysis.
Framework Features
- Full Stack Solution: The framework provides full stack solution for IP flow analysis prototyping. It is possible to connect to the majority of IP flow network probes. The framework integrates tools for data collection, data processing, manipulation, storage, and presentation. It is compatible with common network probes for IP flow monitoring and export.
- Easy Deployment: The deployment of the framework is fully automated for cloud deployment using cutting-edge technologies for software orchestration. The deployment comes with example prototype applications and initial tests to further ease the prototype development.
- High Performance: Thanks to the scalability of the framework, it is fitted for processing network traffic in a wide range of networks from small company network to large-scale, high-speed networks of ISPs. Its distributed nature enables computationally intensive analyses.
- Real-time Analysis: The stream-based approach provides results of IP flow analysis prototype with only a few seconds delay. The results can be explored in various ways in a user interface in real time. IP analysis prototype can be immediately improved according to provided results.
Use-cases
- Stream-Based Network Monitoring: The framework enables to run analyses in data streams. It is suitable for various data pre-processing, continuous queries.
- Real-time Attack Detection: The stream-based approach enables to detect attacks with only a few seconds delay. An instant attack detection provides time to set up a defense and lowers harms caused by an attack. Sample detections are provided, and you can easily create custom detection method.
- Host Profiling: Apart from monitoring of the whole network, the monitoring can be focused on individual hosts. No host agents are needed, and the monitoring is transparent. You can get a long-term profile for each host connected to your network and explore its behavior.
- Situational Awareness: Data from network monitoring, attack detection, and host profiling can be gathered together to provide complex situational awareness over your network. The advanced analysis of the collected data can reveal information important both from security and business perspective.
More on stream-based IP flow analysis is described in our paper titled Toward Stream-Based IP Flow Analysis.
Getting started
We have it all prepared for you. Everything is preconfigured. You have to only choose the deployment variant.
Deployment
Default machine configuration
- Producer - a machine for receiving data from network and probes, and providing data for Spark Cluster via Apache Kafka.
- producer default IP address - 192.168.0.2
- Consumer - a machine receives results from Spark Cluster, stores the results, and runs the web server with framework frontend.
- consumer default IP address - 192.168.0.3
- Spark Cluster- cluster of machines for data stream processing. Spark Master machine manages the Spark Cluster and provides a control interface for the cluster. Spark Slaves serves mainly for data processing. The number of Spark Slaves can be changed in configuration files.
- Spark Master default IP address - 192.168.0.100
- Spark Slave default IP address - 192.168.0.101
Default login credentials
- user: spark
- login: Stream4Flow
Requirements
We support two types of deployment:
- Standalone deployment: Stream4Flow will be deployed into virtual machines on your physical machine using Vagrant
- Cluster deployment: you can deploy Stream4Flow on your cluster using Ansible
- requirement: Debian-based OS
Standalone deployment
Note: The minimum hardware requirement is 12GB of RAM
- download repository
- go to folder provisioning/
- (optional) update guests configuration in configuration.yml
- run vagrant provisioning:
vagrant upor start guests separatelyvagrant up <guest-name> - upload your SSH key to guests or allow password based SSH login (use
vagrant ssh <guest-name>)
See provision/README.md for additional information about provisioning and Vagrant usage.
Cluster deployment
Note: machines in the cluster must run Debian OS with systemd
- download repository
- go to folder provisioning/ansible
- supply your inventory file with you cluster deployment according to file inventory.ini.example
- run ansible
ansible-playbook -i <your inventory file> site.yml --user <username> --ask-pass(consult ansible docs for further information)
Usage
| Usage | Description | Usage information |
|---|---|---|
| Input data | Input point for network monitoring data in IPFIX/Netflow format |
|
| Stream4Flow Web Interface | Web interface for application for viewing data |
|
| Spark Web Interface | Apache Spark streaming interface for application control |
|
| Kibana Web Interface | Elastic Kibana web interface for Elasticsearch data |
|
Run an example application protocols_statistics
- login to Spark Master machine via ssh
ssh spark@192.168.0.100 - go to application directory
cd /home/spark/applications/ - run example application
./run-application.sh ./statistics/protocols_statistics/spark/protocols_statistics.py -iz producer:2181 -it ipfix.entry -oz producer:9092 -ot results.output
Send data to Stream4Flow
Stream4Flow is compatible with any Netflow v5/9 or IPFIX network probe. To measure your first data for Stream4Flow, you can use either commercial solution such as Flowmon Probe or an open-source alternative softflowd
-
Install softflowd
sudo apt-get install softflowd -
Start data export
- Standalone deployment
softflowd -i <your interface> -D -n 192.168.0.2:4739 - Cluster deployment
softflowd -i <your interface> -D -n <IP address of producer>:4739 - for more softflowd options see man pages
- Standalone deployment
How to reference
Bibtex
@ARTICLE{jirsik-2017-toward,
author={Jirsik, Tomas and Cermak, Milan and Tovarnak, Daniel and Celeda, Pavel},
journal={IEEE Communications Magazine},
title={Toward Stream-Based IP Flow Analysis},
year={2017},
volume={55},
number={7},
pages={70-76},
doi={10.1109/MCOM.2017.1600972},
ISSN={0163-6804},
}Plain text
T. Jirsik, M. Cermak, D. Tovarnak and P. Celeda, "Toward Stream-Based IP Flow Analysis," in IEEE Communications Magazine, vol. 55, no. 7, pp. 70-76, 2017.
doi: 10.1109/MCOM.2017.1600972Related Publications
- Toward Stream-Based IP Flow Analysis
- A Performance Benchmark for NetFlow Data Analysis on Distributed Stream Processing Systems
- Real-time analysis of NetFlow data for generating network traffic statistics using Apache Spark
Acknowledgement
The SecurityCloud project is supported by the Technology Agency of the Czech Republic under No. TA04010062 Technology for processing and analysis of network data in big data concept.