![]()
![]()
![]()
TakeTwo Solution Starter - Data Science
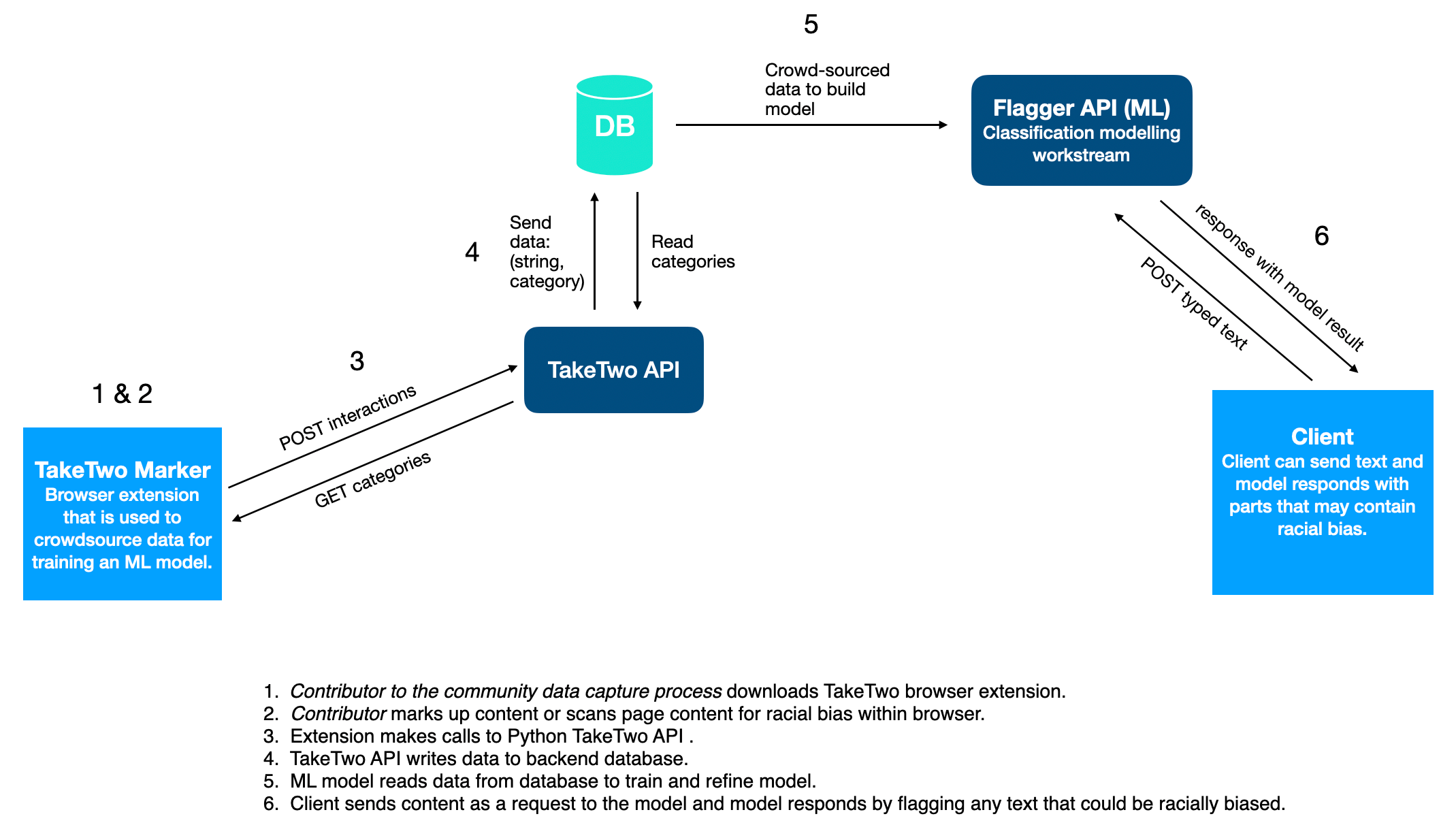
The Call for Code for Racial Justice TakeTwo machine learning and datascience component uses data crowdsourced by a Chrome extension and sent to a backend database.
Technology Used
The machine learning model code is written in Python and runs in a Jupyter notebook.
Description of TakeTwo Data Science
This repo contains the code for building a machine learning model to predict whether a word or phrase contains racial bias and, if so, predict the category of racial bias.
Data
The model uses data from a backend database, populated by crowdsourcing.
Initially the backend database is empty and the open-source community is welcome to take on ownership and stewardship of the data.
The fields used by the model are:
"flagged_string": The word or phrase that has been crowdsourced."category": The category that has been selected for the type of racial bias present in the highlighted word or phrase."url": The url from where the word or phrase was highlighted.
Data Science Evolution
The vision is for the module to contain an evolving set of versions, with various degrees of sophistication, for the DS/ML component of the solution. Currently, the repository contains DS-MVP-0 and some work towards DS-MVP-1.

The overall goal of the DS/ML component is to use machine learning on text data to detect racially biased expressions and usage in context.
It will use input labeled data collected through crowdsourcing, enabled by the MVP1 browser extension ("Marker"), and train an ML model to classify text. This data will be used by the MVP2 plug-in on a content editor ("Flagger") to flag racially biased text input to the editor.
Below are a possible series of capabilities (refered to here as DS-MVPs) that may be developed and included in this component:
-
DS-MVP-0 (this module does not involve "data science/machine learning" models, and may be placed in a different repo - e.g. taketwo-webapi). A module that can detect racially biased terms based on a dictionary look-up, where the look-up may be done via calls to a database table containing a pre-identified set of racially biased terms.
-
DS-MVP-1 (implemented in this repository) A machine learning module that can learn to detect racially biased terms and expressions in broad context based on input labeled data. Versions of MVP-1, using bag-of-words representation and Naive Bayes and Support Vector Machine classifiers have been implemented in the repository. Here, the labeled data consists of <expression, classification> pairs.
-
DS-MVP-2 (to be documented) An extended machine learning module that can learn to detect racially biased expressions in sequential context based on input labeled data. It would be natural to implement this version utilizing recurrent deep neural networks such as the LSTM architecture. Here, the labeled data consists of <context, expression, classification> triples.
-
DS-MVP-3 (to be documented) An extended machine learning model that can learn to detect racially biased expressions in context based on input lableled data, without having to specify the "expression" and "context" separately in the input text. Here, the labeled data consists of <text, classification> pairs and the trained model is to output <expression(s), classification> on a new test text, where expression(s) are sub-expression(s) of the input text that are identified to be biased expressions in context of the rest of the text.
-
DS-MVP-4 (to be documented) An advanced machine learning module that can learn to detect racially biased expressions, assess the credibility of each marker based on input labeled data, and make use of the estimated credibility in computing the judgement for any given input text. A concrete method for this version is documented in this repository. Here, the labeled data consists of <expression, classification, marker-ID> triples.
-
DS-MVP-5 (to be documented) An advanced online active learning module that can learn to detect racially biased expressions and to actively solicit labeled data from selected markers (based on the estimated credibility of the markers). Here, the labeled data consists of <expression, classification, marker-ID> triples.
Related Links
There are a number of other components related to this project:
- TakeTwo WebAPI - Code for the TakeTwo backend database.
- TakeTwo Marker Chrome Extenstion - Code for the Chrome extension used to crowdsource data for training the ML model.
License
This solution starter is made available under the Apache 2 License.