Introduction générale au Data Mining
My Digital School Rennes

- Introduction générale au Data Mining
- Projet de cours
- Le data mining pour tous
- Définition
- Enjeux
- La pyramide DIKW
- Les applications du data mining
- Data mining & finance
- Banques & finances
- Vente, Distribution, Marketing
- Assurances
- Les méthodes de data mining
- Deux familles de techniques
- Types d'applications
- Methodologies de travail
- KDD / EDC
- SEMMA : Sample, Explore, Modify, Model, Assess
- CRISP - DM
- ⚠️ Les données dans le monde réél !
- Credits
Projet de cours
Date de dernière mise à jour : 14/04/2020
Agenda
Journée 1
9H - 12H30 - Introduction générale
- Le Data mining pour tous
- Présentation des outils & workflow de travail
14H - 17H
- Création de groupes de travail
- Premier push a 16H30 sur le répertoire https://github.com/CashStory/training-datamining-mds
Journée 2
9H - 12H30
-
Les techniques de data mining / collection
-
présentation du projet opensource worldsituationroom.com mené par CashStory
14H - 17H
- Mini projet en peer programming (à 2) : collecter et traiter la données sur les organismes internationaux sur les sujet : démographiques, environnementaux à l'échelle mondiale
Journée 3
9H - 12H30
- Mini projet en peer programming (à 2) : collecter et traiter la données sur les organismes internationaux sur les sujet : démographiques, environnementaux à l'échelle mondiale.
14H - 17H
- Mini projet : collecter et traiter la données sur les organismes internationaux sur les sujet : démographiques, environnementaux à l'échelle mondiale.
Journée 4
9H - 12H30
- Documenter son code: un outil de communication et de promotion de son travail
- Revue de travaux du mini projet
14H - 17H
-
Votes sur les meilleurs scripts (par tous)
-
Intégration des scripts selectionnés dans le répertoire opensource du projet http://worldsituationroom.com/
Outils
- Campus online : https://mycampus.eduservices.org/
- Teams
- Emails :
- Naas
- Google colab console
Le data mining pour tous
Définition
Le Data Mining c’est l’ensemble des algorithmes, méthodes et technologies inspirés de plusieurs autres disciplines, propres ou non au DM pouvant servir à remplacer ou à aider l’expert humain ou le décideur dans un domaine spécifique dans le cadre de prise de décision, et ce en fouillant dans des bases de données décisionnelles des corrélations, des associations, des comportements homogènes, des formules de lien entre indicateurs, des spécification par rapport à une thématique bien déterminée.
Enjeux
- Simplifier la production de données en informations structurées et porteuses de sens
- Créer du sens et des connaissances à partir de données non enrichies et non structurées
- Analyser des tendances sur la durée
- Permettre la création de modèles sur des historiques de données
- Analyse prédictive
La pyramide DIKW

Les applications du data mining
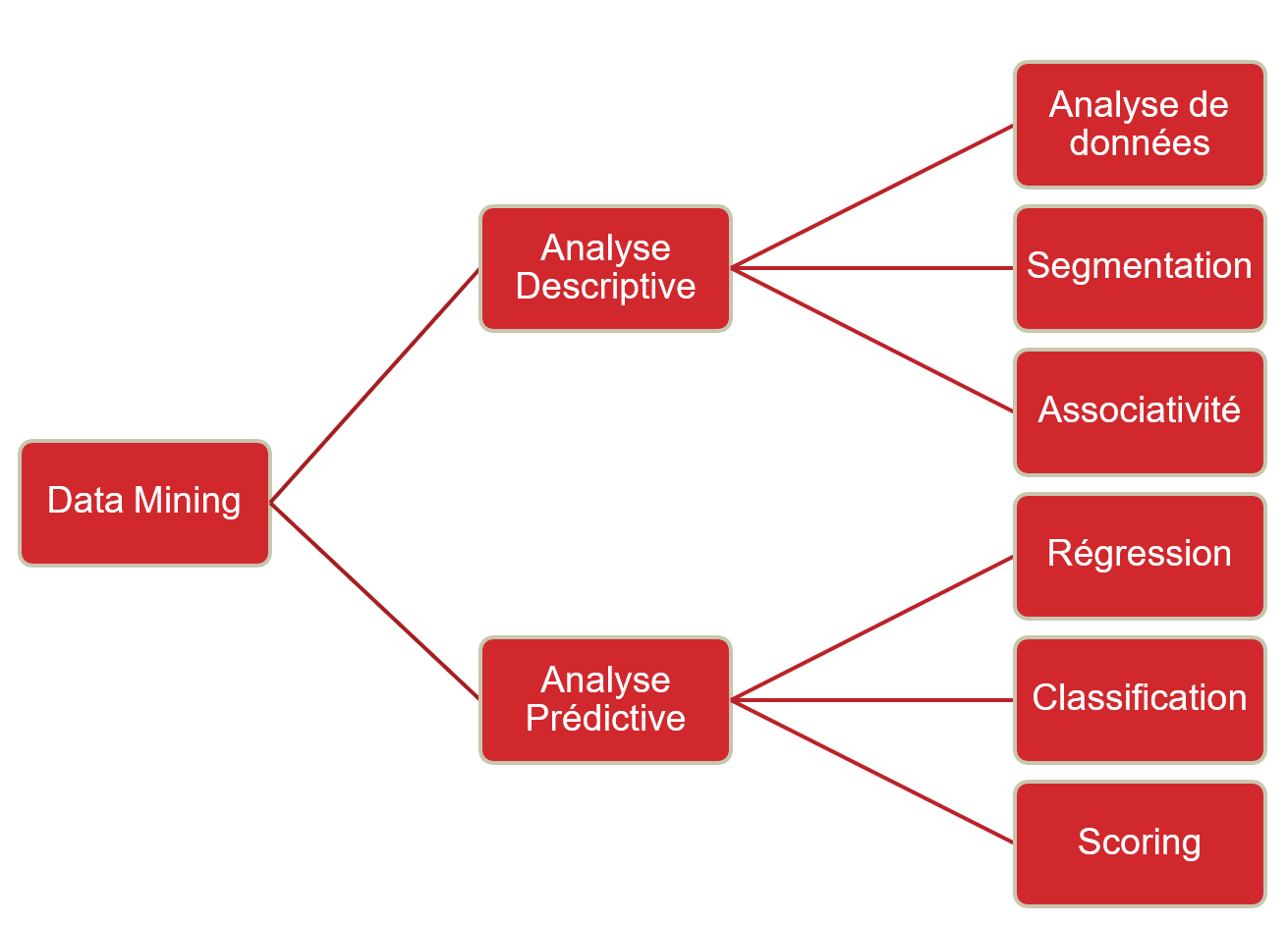
-
Analyse de données : Résumer et visualiser l’activité de l’entreprise à travers
des indicateurs pertinents
-
Segmentation :
- Aucune variable décisionnelle, information quantitative
- Les variables d’entrées servent à créer des groupes homogènes
- Les individus de chaque groupe se ressemblent le plus
- Les groupes d’appartenances obtenus se distinguent le plus
- Trouver les variables métiers influençant la répartition en groupes
- Affecter les individus à leurs nouveaux groupes d’appartenance
- Plusieurs méthodes et techniques pour segmenter :
- Partionnement : k-means
- Hiérarchique : CAH
- Trouver les comportements typiques des clients.
-
Associativité :
- Analyse du chariot : recherche des articles les plus/moins associés
- Médecine : les symptomes associés
-
Classification :
- La variable décisionnelle est qualitative
- Un dossier de crédit peut être classifié : BON ou MAUVAIS
- Un patient peut présenter un fort risque de maladie cardiaque
- Un client peut présenter un comportement atypique
- La Classification a pour objectifs :
- Détecter les variables possédant un lien fort avec la variable décisionnelle
- Construire un modèle de classification liant ces variables à la décision
- Plusieurs méthodes et techniques pour classifier :
- Arbre de décision
- Forêts Aléatoires
- K-NN k-nearest neighbors
- Séparateur à vaste Marge SVM
- Régression Logistique
-
Scoring :
- Evaluation de campagne terrain : déterminer l'efficacité de la communication avec les clients.
- Marketing ciblé : optimiser les chances d'obtenir des réponses (positives) de la part des clients à une offre particulière par un ciblage plus précis, mettant en évidence les clients avec une forte probabilité de réponse.
- Data mining & CRM : le datamining a beaucoup d'applications qui peuvent apporter un soutien considérable au marketing et à la gestion de la relation client (faire correspondre des profils des clients avec des offres produits afin d’augmenter le taux de conversion : cross selling)
-
Régression Linéaire :
- La variable décisionnelle est quantitative
- Prédire les tendances salariales la prochaine année
- Prédire le meilleur pourcentage de réduction de coûts
- Construire un modèle générique pour l’estimation de la consommation de carburant
- La régression a pour objectifs :
- Détecter les variables possédant un lien fort avec la variable cible
- Construire un modèle prédictif avec l’ensemble des variables pertinentes afin de prédire la variable d’intérêt
- Détecter les individus atypiques ou les aberrances
- Régression Linéaire
- Méthode des moindres carrés
- Meilleurs prédicteurs
- Applications :
- Pricing : Déterminer le prix "optimal"convenable pour un produit.
- Analyse Coûts-bénéfices : Identifier les produits et les campagnes les plus rentables
Data mining & finance
Banques & finances
- Gestion de risque - évaluer un risque de défaut. Au delà des techniques classiques de scoring, d'autre techniques de modélisation issues de l'intelligence artificielle permettent d'augmenter la maitrise de ces risques.
- Crédit scoring - évaluer le risque de non remboursement (technique data mining la plus déployée)
- Détection de fraudes - identifier plus facilement et plus rapidement les éventuelles transactions frauduleuses
- Segmentation - améliorer la connaissance de vos clients par la découverte de groupes homogènes et par une caractérisation selon leur profil
- Prédiction - prévoir quels clients seront intéressés par une offre
Vente, Distribution, Marketing
- Détection d'associations de comportements d'achat
- Découverte de caractéristiques de clientèle.
- Prédiction de probabilité de réponse aux campagnes de mailing.
Assurances
- Découverte d'associations des demandes de remboursements
- Identification de clients potentiels de nouvelles polices d'assurances.
- Détection d'association de comportements pour la découverte de clients à risque.
- Détection de comportement frauduleux.
- Prendre un client à un concurrent.
- Faire monter en gamme un client que l’on détient déjà.
Prise de Décision, Prédiction, Exploitation de données, etc.
Les méthodes de data mining
Deux familles de techniques
1- Apprentissage automatique (Analyse descriptive)
- S’appliquent seulement sur les données quantitatives.
- Fournissent directement des résultats : à interpréter et à utiliser !
- Visent à mettre en évidence des connaissances présentes mais cachées par le volume des données
- Réduisent, résument, synthétisent les masses de données
- pas de variable « cible »
2- Apprentissage supervisées (Analyse prédictive)
- Fournissent un modèle (et non pas des résultats), créé à partir d’un entrepôt d’apprentissage, testé et validé sur un entrepôt de test, et utilisé dans les problèmes de prise de décision sur des entrepôts de travail
- visent à découvrir de nouvelles informations à partir des informations présentes : connaissances, décisions
- expliquent mieux les données
- Une(des) variable(s) « cible(s)»
Types d'applications
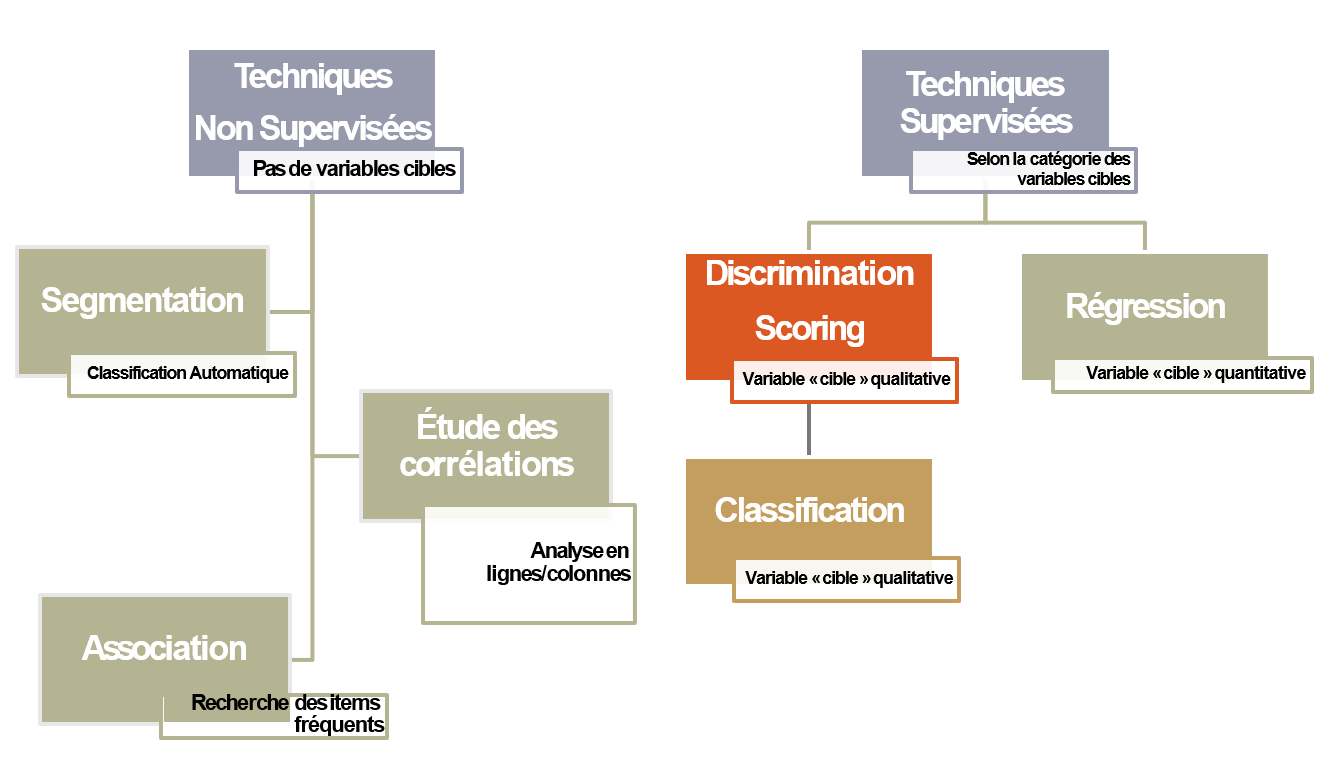
2 familles de techniques :
- Méthodes Non Supervisées
- Analyse en Composantes Principales ACP
- Apprentissage Automatique
- Méthode descriptive
- Données purement quantitatives
- Obtention de Corrélations
- Relations :
- (Ii, Ij),
- (Ii, Xk),
- (Xk,Xp)
- Méthodes de Segmentation (Classification Automatique)
- Apprentissage Automatique
- Méthode descriptive
- Obtention d’une nouvelle affection/appartenance
- Groupes d’individus possédant des caractéristiques semblables : meilleure classification
- Mise à jour de l’entrepôt en Input : ajouter la nouvelle caractéristique des individus
- Classification Ascendante Hiérarchique CAH
- Règles Associatives Apriori
- Apprentissage Automatique
- Méthode descriptive
- Données Transactionnelles
- Obtention d’un ensemble de règles expliquant l’associativité/correspondance entre les items/produits/profils
- Trier les règles selon des indicateurs de performances
- Méthodes Supervisées
- Arbres de Décisions
- Analyse Linéaire Discriminante
- Régression
- Plus Proche voisin kNN
- Réseaux de Neurones
- Séparateur à Vaste Marge SVM
Methodologies de travail
KDD / EDC
(Knowledge Data Discovery / Extraction de connaissances à partir de données)
Définition : Knowledge Discovery in Databases
- proposé par Ossama Fayyad en 1996
- un processus pour la fouille de données qui a bien répondu aux besoins d’entreprises, et qui est devenu rapidement très populaire.
- KDD a comme but l’extraction des connaissances,
- des motifs valides, utiles et exploitables à partir des grandes quantités de données
- par des méthodes automatiques ou semi-automatiques.
- Le processus de KDD est itératif et interactif.
- Le processus est itératif : il peut être nécessaire de refaire les pas précédents.
- Le problème de ce processus, comme pour les autres présentés dans la section suivante, est le manque de guidage de l’utilisateur, qui ne choisit pas à chaque étape la meilleure solution adaptée pour ses données.
Phases principales
-
Développer et comprendre le domaine de l’application
- C’est le pas initial de ce processus. Il prépare la scène pour comprendre et développer les buts de l’application.
-
Sélection des données
- La sélection et la création d’un ensemble de données sur lequel va être appliqué le processus d’exploration.=> "Données ciblées"
-
Le prétraitement et le nettoyage des données
- Cette étape inclut des opérations comme l’enlèvement du bruit et des valeurs aberrantes -si nécessaire, des décisions sur les stratégies qui vont être utilisées pour traiter les valeurs manquantes... => "Données prétraitées"
-
La transformation des données
- Cette étape est très importante pour la réussite du projet et doit être adaptée en fonction de chaque base de données et des objectifs du projet.
Dans cette étape nous cherchons les méthodes correctes pour représenter les données. Ces méthodes incluent la réduction des dimensions et la transformation des attributs.=> "Données transformées"
- Note : une fois que toutes ces étapes seront terminées, les étapes suivantes seront liées à la partie de Data mining, avec une orientation sur l’aspect algorithmique.
- Cette étape est très importante pour la réussite du projet et doit être adaptée en fonction de chaque base de données et des objectifs du projet.
Dans cette étape nous cherchons les méthodes correctes pour représenter les données. Ces méthodes incluent la réduction des dimensions et la transformation des attributs.=> "Données transformées"
-
Choisir la meilleure tâche pour Datamining
- Nous devons choisir quel type de Datamining sera utilisé, en décidant le but du modèle.
- Par exemple : classification, régression, regroupement...
- Nous devons choisir quel type de Datamining sera utilisé, en décidant le but du modèle.
-
Choisir l’algorithme de Datamining
- Dans cette étape nous devons choisir la méthode spécifique pour faire la recherche des motifs, en décidant quels modèles et paramétrés sont appropriés.=> "Création de modèles"
-
Implémenter l’algorithme de Datamining
- Dans cette étape nous implémentons les algorithmes de Datamining choisis dans l’étape antérieure.
- Peut être il sera nécessaire d’appliquer l’algorithme plusieurs fois pour avoir le résultat attendu.
-
Evaluation
- Evaluation et interprétation des motifs découverts. Cette étape donne la possibilité de:
- Retourner à une des étapes précédentes
- Avoir une représentation visuelle des motifs, enlever les motifs redondants ou non-représentatifs et les transformer dans des termes compréhensibles pour l’utilisateur.
- Evaluation et interprétation des motifs découverts. Cette étape donne la possibilité de:
-
Utiliser les connaissances découvertes
- Incorporation de ces connaissances dans des autres systèmes pour d’autres actions.
- Nous devons aussi mesurer l’effet de ces connaissances sur le système, vérifier et résoudre les conflits possibles avec les connaissances antérieures.

Le KDD est devenu lui-même un modèle pour les nouveaux modèles.
Le modèle a été utilisé dans plusieurs domaines différentes : ingénierie, médicine, e-business, production, développement du logiciel, etc.
SEMMA : Sample, Explore, Modify, Model, Assess
Mise en contexte
L’Institut SAS définit le data mining comme le processus utilisé pour révéler des informations précieuses et des relations complexes qui existent dans de grandes quantités de données (BIG DATA, OPEN DATA).
SAS divise la fouille de données en cinq étapes représentées par l’acronyme SEMMA.
Définition
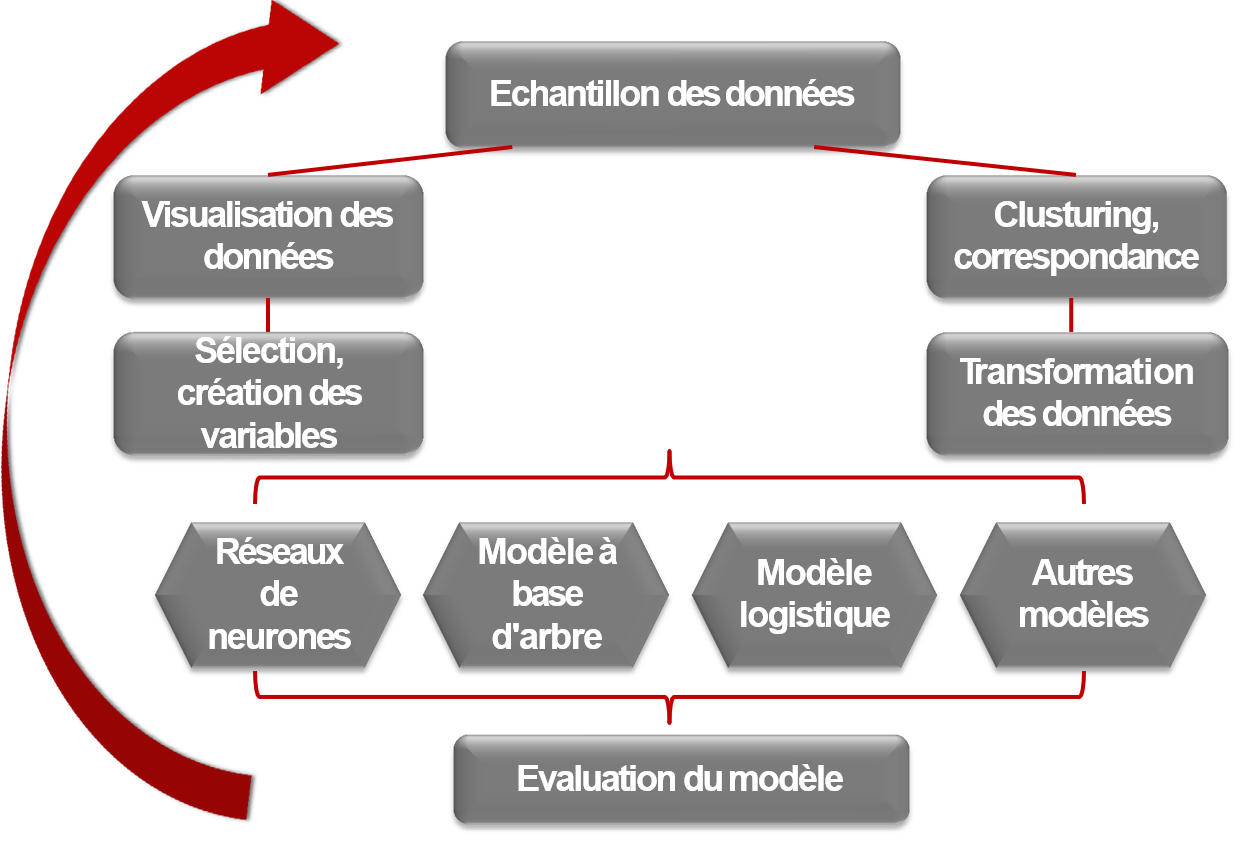
Phases principales
1- Sample: Echantillon des données
Extrait des échantillons d’un vaste ensemble de données, en nombre suffisamment grand pour contenir l’information importante.
2 - Explore: Exploitation des données
Cette étape consiste dans l’exploration des données en recherchant les tendances et les anomalies imprévues afin de mieux comprendre les données.
3 - Modify: Modifier les données
Dans cette étape on modifie les données en créant, en sélectionnant et en transformant les variables afin de s’axer sur le processus de sélection de modèles.
4 - Model: Modélisation des données
-
Modélisation des données en permettant au logiciel de rechercher automatiquement une combinaison des données qui prédit de façon fiable le résultat souhaité.
-
Il y a plusieurs techniques de modélisation: les réseaux de neurones, arbres de décision, modèles statistiques - l’analyse en composantes principales, l’analyse de séries temporelles...
5 - Assess: Evaluer le résultat
-
Cette étape consiste à l’évaluation de l’utilité et la fiabilité des résultats du processus de DataMining et estime comment il va s’exécuter.
-
En évaluant les résultats obtenus à chaque étape du processus de SEMMA, nous pouvons déterminer la façon de modéliser les nouveaux problèmes déterminés par les résultats
précédents, et donc de refaire la phase d’exploration supplémentaire pour le raffinement des données.
L'Application SAS
-
SAS est définie par SEMMA comme l’organisation logique d’outil SAS Entreprise Miner pour la réalisation des tâches de DataMining.
-
Enterprise Miner peut être utilisé comme une partie de n’importe quelle méthodologie itérative de DataMining adoptée par le client.
-
Une des différences entre KDD et SEMMA est que SEMMA est intégré dans l’outil Enterprise Miner et ils n’utilisent pas d’autres méthodologies, tandis que le KDD est un processus ouvert qui peut être appliqué dans plusieurs environnements.
CRISP - DM
Définition
Cross-Industry Standard Process for Data Mining
Une méthode mise à l'épreuve sur le terrain permettant d'orienter les travaux de Data mining
Processus de data mining qui décrit une approche communément utilisée par les experts pour résoudre les problèmes qui se posent à eux.
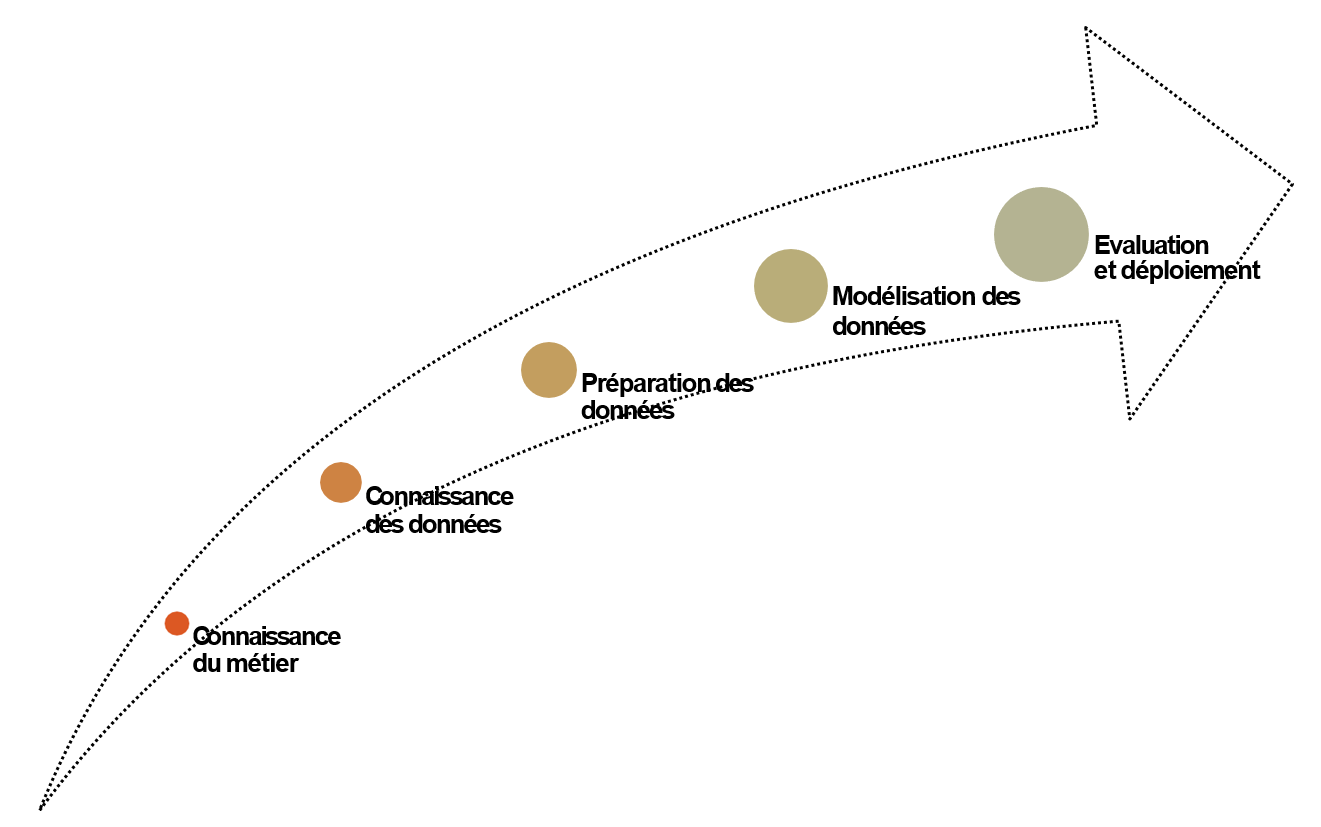
Méthodologie
- comprend des descriptions des phases typiques d'un projet et des tâches comprises dans chaque phase, et une explication des relations entre ces tâches.
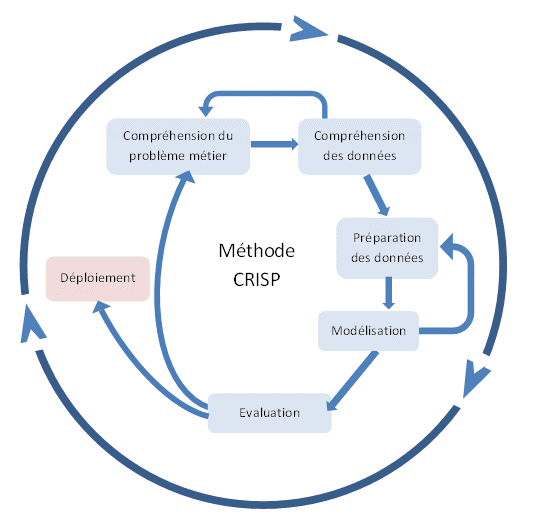
Phases principales
1- Compréhension métier
- Déterminer les objectifs business
- Résoudre un problème spécifique
- Evaluer la situation actuelle
- Convertir en un problème de data mining
- Quels types de clients sont intéressés par chacun de nos produits?
- Quels sont les profils typiques de nos clients?
- Élaborer un plan de projet
2 - Compréhension des données
- Collecte de données initiale
- Description des données
- Exploration des données
- Vérification de la qualité des données
- Sélection des données
- Les données connexes peuvent provenir de nombreuses sources :
- Interne (ERP, CRM, Data Warehouse…)
- Externe (données commerciales, données du gouvernement…)
- Créées (recherche)
Les enjeux de la selection des données
- Mettre en place une description concise et claire du problème
- Identifier les comportements de dépenses des femmes qui achètent des vêtements saisonniers
- Identifier les modèles de la faillite de détenteurs de cartes de crédit
- Identifier les données pertinentes pour la description du problème
- Données démographiques, données financières…
- Les variables sélectionnées pour les données pertinentes doivent être indépendantes les unes des autres.
3 - Préparation des données
-
Nettoyer les données sélectionnées pour une meilleure qualité
- Remplissez les valeurs manquantes
- Identifier ou supprimer les valeurs aberrantes
- Résoudre la redondance causée par l'intégration des données
- Les données incohérentes correctes
-
Transformer les données
- Convertir des mesures différentes de données dans un échelle numérique unifié en utilisant des formulations mathématiques simples
Les enjeux de la transformation des données
- Transformez le numérique à des échelles numériques
- Les échelles salariales de « 100 TND » à « 1000 TND » à un certain nombre de [0.0, 1.0]
- Le système métrique (par exemple, le mètre, kilomètre) au système anglais (par exemple, des pieds et miles)
- Recoder les données catégoriques à des échelles numériques
- "1" = "oui" et "0" = "No"
- Gestion des dates
- Nommage des labels à analyser
4 - Modélisation
-
Traitement des données
- Ensemble d'apprentissage
- Ensemble de test…
-
Les techniques de data mining
- Association
- Classification
- Clustering
- Prédictions
- Les motifs séquentiels
5 - Evaluation
- Est-ce que le modèle répond aux objectifs métier?
- Des objectifs métier importants non résolus? Est-ce que le modèle est logique?
- Est-ce que le modèle est actionnable?
- Il devrait être possible de prendre des décisions après cette étape.
- Tous les objectifs importants doivent être atteints.
6 - Déploiement et implémentation
- En cours de suivi et d'entretien
- Évaluer la performance par rapport aux critères de réussite
- La réaction du marché et les changements des concurrents
Exemple CRISP: les factures de téléphone
Séquence de période de facturation:
- Utilisez 2 mois, recevoir la facture, le paiement du mois de facturation, débrancher si la facture n'est pas réglée pendant une période déterminée
| Phases | Description |
|---|---|
| 1/ COMPRÉHENSION MÉTIER |
Prédire quels clients seraient insolvables à temps pour l'entreprise pour prendre des mesures préventives (et d'éviter de perdre de bons clients) Hypothèse: Clients insolvables vont changer les habitudes d'appel et l'usage du téléphone pendant une période critique avant et immédiatement après la fin de la période de facturation. |
| 2/ COMPRÉHENSION DES DONNÉES |
Les informations statiques des clients sont disponibles dans des fichiers (Factures, paiements, utilisation…) Un entrepôt de données est utilisé pour recueillir et organiser les données (Un codage pour protéger la vie privée des clients) |
| CRÉATION DE L'ENSEMBLE DES DONNÉES CIBLES | - Les fichiers des client (Informations sur les clients, Déconnexion, Reconnexions) - Données dépendantes du temps (Factures, paiements, Utilisation) 100, 000 clients sur une période de 17 mois L'échantillonnage pour assurer à tous les groupes une représentation appropriée |
| 3/ PRÉPARATION DES DONNÉES |
Filtrer les données incomplètes Les appels en promotion supprimés - Le volume des données réduit d'environ 50% Faible nombre des cas de fraude Vérification croisée avec les déconnexions du téléphone Les données retardées sont nécessairement synchronisées |
| 4/ MODÉLISATION |
Analyse discriminante: modèle linéaire Les arbres de décision: Classificateur à base de règles Réseaux de Neurones : Le modèle non linéaire |
| 5/ EVALUATION |
Le premier objectif est de maximiser la précision de la prédiction des clients insolvables - Arbre de décision un classificateur meilleur Deuxième objectif est de minimiser le taux d'erreur pour les clients de solvants - Le modèle Réseau de Neurones proche de l’arbre de décision Utilisé tous les 3 sur la base de cas par cas. |
| 6/ IMPLÉMENTATION |
Chaque client a été examiné avec les 3 algorithmes - Si tous les 3 sont convenables, utiliser une classification - En cas de désaccord, catégorisé comme non classé Correcte sur les données d'essai avec 0.898 - Seulement 1 client solvant aurait été débranché |
⚠️ Les données dans le monde réél !
-
Incomplètes: manque de valeurs d'attributs, manque de certains attributs d'intérêt ou ne contenant que des agrégats des attributs d’intérêt ou contenant uniquement des données agrégées
- l'occupation = ""
-
Bruyantes: contenant des erreurs ou des valeurs aberrantes
- Salaire = "- 1000"
-
Incompatibles: contenant des écarts dans les codes ou les noms
-
Age = "42" et anniversaire = "03/07/1993"
-
note =« 1,2,3 » ensuite «A, B, C »
-
Les principales causes
Les données incomplètes peuvent provenir de:
- La valeur de données lors de la collecte «Sans objet»
- Des considérations différentes entre le moment où les données ont été collectées et lorsqu‘elles sont analysées.
- Problèmes humains / matériels / logiciels
Les données bruyantes (valeurs incorrectes) peuvent provenir de:
- Les instruments de collecte de données sont erronés
- L'erreur humaine ou informatique à la saisie de données
- Les erreurs de transmission de données
Les données incohérentes peuvent provenir de:
- Différentes sources de données
- La violation de la dépendance fonctionnelle (par exemple, de modifier certaines données liées)
Credits
-
Mohamed Heny Selmi, Le data mining ou "la fouille de données" (ESPRIT)
-
DIKW, la pyramide qui inspire le futur des moteurs de recherche
-
Why using CRISP-DM will make you a better Data Scientist
-
Data mining Bioinfo