Statistics | Deep Learning | Neural Architecture Search
[简体中文](README_zh_CN.md) • [Installation](https://hyperts.readthedocs.io/en/latest/contents/0200_installation.html) • [Documentation](https://hyperts.readthedocs.io/en/latest/) • [Examples](https://github.com/DataCanvasIO/HyperTS/tree/main/examples)
[](https://pypi.org/project/hyperts)
[](https://pypi.python.org/pypi/hyperts)
[](https://anaconda.org/conda-forge/HyperTS)
[](https://pypi.org/project/hyperts)
[](https://github.com/DataCanvasIO/hyperts/blob/master/LICENSE)
:dizzy: Easy-to-use, powerful, and unified full pipeline automated time series toolkit. Supports forecasting, classification, regression, and anomaly detection.
## We Are Hiring!
Dear folks, we are offering challenging opportunities located in Beijing for both professionals and students who are keen on AutoML/NAS. Come be a part of DataCanvas! Please send your CV to yangjian@zetyun.com. (Application deadline: TBD.)
## Overview
HyperTS is a Python package that provides an end-to-end time series (TS) analysis toolkit. It covers complete and flexible AutoML workflows for TS, including data clearning, preprocessing, feature engineering, model selection, hyperparamter optimization, result evaluation, and visualization.
Multi-mode drive, light-heavy combination is the highlighted features of HyperTS. Therefore, statistical models (STATS), deep learning (DL), and neural architecture search (NAS) can be switched arbitrarily to get a powerful TS estimator.
As an easy-to-use and lower-threshold API, users can get a model after simply running the experiment, and then execute ```.predict()```, ```.predict_proba()```, ```.evalute()```, ```.plot()``` for various time series analysis.
## Installation
Note:
- Prophet is required by HyperTS, install it from ``conda`` before installing HyperTS using ``pip``.
- Tensorflow is an optional dependency for HyperTS, install it if using DL and NAS mode.
HyperTS is available on Pypi and can be installed with ``pip``:
```bash
pip install hyperts
```
You can also install HyperTS from ``conda`` via the ``conda-forge`` channel:
```bash
conda install -c conda-forge hyperts
```
If you would like the most up-to-date version, you can instead install direclty from ``github``:
```bash
git clone git@github.com:DataCanvasIO/HyperTS.git
cd HyperTS
pip install -e .
pip install tensorflow #optional, recommended version: >=2.0.0,<=2.10.0
````
For more installation tips, see [installation](https://hyperts.readthedocs.io/en/latest/contents/0200_installation.html).
## Tutorial
|[English Docs](https://hyperts.readthedocs.io/en/latest/) / [Chinese Docs](https://hyperts.readthedocs.io/zh_CN/latest)| Discription |
| --------------------------------- | --------------------------------- |
[Expected Data Format](https://hyperts.readthedocs.io/en/latest/contents/0300_dataformat.html)|What data formats do HyperTS expect?|
|[Quick Start](https://hyperts.readthedocs.io/en/latest/contents/0400_quick_start.html)| How to get started quickly with HyperTS?|
|[Advanced Ladder](https://hyperts.readthedocs.io/en/latest/contents/0500_advanced_config.html)|How to realize the potential of HyperTS?|
|[Custom Functions](https://hyperts.readthedocs.io/en/latest/contents/0600_custom_functions.html)|How to customize the functions of HyperTS?|
## Examples
Time Series Forecasting
Users can quickly create and ```run()``` an experiment with ```make_experiment()```, where ```train_data```, and ```task``` are required input parameters. In the following forecast example, we define the experiment as a multivariate-forecast ```task```, and use the statistical model (stat ```mode```) . Besides, the mandatory arguments ```timestamp``` and ```covariates``` (if have) should also be defined in the experiment.
```python
from hyperts import make_experiment
from hyperts.datasets import load_network_traffic
from sklearn.model_selection import train_test_split
data = load_network_traffic()
train_data, test_data = train_test_split(data, test_size=0.2, shuffle=False)
model = make_experiment(train_data.copy(),
task='multivariate-forecast',
mode='stats',
timestamp='TimeStamp',
covariates=['HourSin', 'WeekCos', 'CBWD']).run()
X_test, y_test = model.split_X_y(test_data.copy())
y_pred = model.predict(X_test)
scores = model.evaluate(y_test, y_pred)
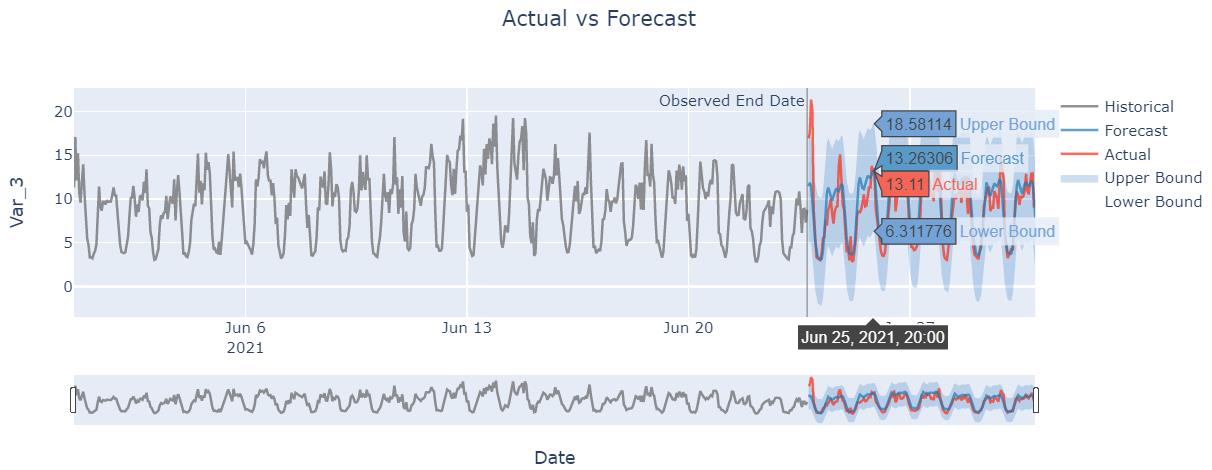
model.plot(forecast=y_pred, actual=test_data)
```