Created by Fareed Khan. You can Follow me on GitHUB or Medium
This Project Repository: create stable diffusion from scratch
Other Projects:
Models checkpoints are available in models_checkpoints folder. You can download them and use them for inference.
models_checkpoints/
|-- ckpt.pth # U-net Architecture with Concatenation
|-- ckpt_res.pth # U-net Architecture with Addition
|-- ckpt_transformer.pth # U-net Architecture with Spatial TransformerBuilding Stable Diffusion from Scratch Using Python
you can read this blog on Medium
Building a Stable Diffusion from scratch is possible, which you will see in this blog, but achieving the current quality found in the market, similar to how Stability AI has built it, is challenging due to the substantial amount of data and computation required. Just as today you can construct a million-parameter LLM, as demonstrated in one of my blogs, scaling it to a billion parameters, as done by companies like Mistral or Meta, demands the same powerful computation and extensive data resources.
In this blog, I will try to create a small-scale stable diffusion like model from scratch. Small-scale here means that we will be working with a small dataset MNIST, which you may have heard of. The reason for choosing this dataset is that the training process should not take too much time, allowing us to quickly check whether our results are getting better or not. Throughout this blog, all the code you see is available in my GitHub repository.
Table of Contents
- Building Stable Diffusion from Scratch Using Python
- Table of Contents
- Prerequisites
- How Stable Diffusion Works?
- Architecture of Stable Diffusion
- Understanding Our Dataset
- Setting the Stage
- Creating basic forward diffusion
- Creating basic reverse diffusion
- Learning Score Function
- Time Embedding for Neural Network
- Coding the U-Net Architecture with Concatenation
- Coding the U-Net Architecture with Addition
- Forward Diffusion Process with Exponential Noise
- Coding the Loss Function
- Coding the Sampler
- Training U-Net Concatenation Architecture
- Training U-Net Addition Architecture
- Building Attention Layers
- Coding the U-Net Architecture with Spatial Transformer
- Updating U-Net Loss with Denoising Condition
- Training U-Net Architecture With Attention Layers
- Generating Images
- What’s Next
Prerequisites
To achieve fast training, it is essential to use a GPU. Ensure you have a basic understanding of object-oriented programming (OOP) and neural networks (NN). Familiarity with PyTorch will also be helpful in coding. If a GPU is not available, you can modify the device value to 'cpu' wherever it appears in the code.
| Topic | Video Link |
|---|---|
| OOP | OOP Video |
| Neural Network | Neural Network Video |
| Pytorch | Pytorch Video |
| Linear Algebra | Linear Algebra Video |
How Stable Diffusion Works?
Stable Diffusion operates differently compared to many other image generation models as a diffusion model. In simple terms, diffusion models use fuzzy noise to encode an image. They then use a noise predictor along with a reverse diffusion process to put the image back together.
Beyond the technical differences of a diffusion model, Stable Diffusion stands out by not using the pixel space of the image. Instead, it uses a simplified latent space.
This choice is driven by the fact that a color image with 512x512 resolution has a huge number of potential values. In comparison, Stable Diffusion uses a compressed image that is 48 times smaller, containing fewer values. This significant reduction in processing requirements allows the use of Stable Diffusion on a desktop computer with an NVIDIA GPU featuring 8 GB of RAM. The effectiveness of the smaller latent space is based on the idea that natural images follow patterns rather than randomness. Stable Diffusion uses variational autoencoder (VAE) files in the decoder to capture intricate details such as eyes.
Stable Diffusion V1 underwent training using three datasets compiled by LAION from the Common Crawl. This includes the LAION-Aesthetics v2.6 dataset, which has images with an aesthetic rating of 6 or higher.
Architecture of Stable Diffusion
Stable Diffusion uses several main architectural components, and in this exploration, we will be building these components:
1. Variational Autoencoder:
-
Consists of an encoder and decoder.
-
Encoder compresses a 512x512 pixel image into a smaller 64x64 model in latent space.
-
Decoder restores the model from latent space into a full-size 512x512 pixel image.
2. Forward Diffusion:
-
Adds Gaussian noise to an image progressively until only random noise remains.
-
Used during training but not for other tasks, except image-to-image conversion.
3. Reverse Diffusion:
-
Iteratively undoes forward diffusion.
-
Trained on billions of images using prompts to create unique images.
4. Noise Predictor (U-Net):
-
Utilizes a U-Net model for denoising images.
-
U-Net models are convolutional neural networks, with Stable Diffusion using the Residual Neural Network (ResNet) model.
5. Text Conditioning:
-
Text prompts are a common form of conditioning.
-
A CLIP tokenizer analyzes each word in a textual prompt and embeds the data into a 768-value vector.
-
Up to 75 tokens can be used in a prompt.
-
Text prompts are fed from the text encoder to the U-Net noise predictor using a text transformer.
-
Setting the seed to a random number generator generates different images in the latent space.
These components work together to make Stable Diffusion capable of creating and manipulating images in a unique and controlled way.
Understanding Our Dataset
We’ll use the MNIST dataset from the torchvision module, which has small 28x28 images of handwritten digits 0–9. As mentioned, we want a small dataset so training doesn’t take too long. Let’s take a peek at what our dataset looks like.
# Import the required libraries
import torch
import torchvision
from torchvision import transforms
import matplotlib.pyplot as plt
# Define a transform to normalize the data
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))])
# Download and load the training dataset
train_dataset = torchvision.datasets.MNIST(root='./data', train=True, transform=transform, download=True)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=64, shuffle=True)
# Extract a batch of unique images
unique_images, unique_labels = next(iter(train_loader))
unique_images = unique_images.numpy()
# Display a grid of unique images
fig, axes = plt.subplots(4, 16, figsize=(16, 4), sharex=True, sharey=True) # Create a 4x16 grid of subplots with a wider figure
for i in range(4): # Loop over rows
for j in range(16): # Loop over columns
index = i * 16 + j # Calculate the index in the batch
axes[i, j].imshow(unique_images[index].squeeze(), cmap='gray') # Show the image using a grayscale colormap
axes[i, j].axis('off') # Turn off axis labels and ticks
plt.show() # Display the plot
Our dataset comprising 60,000 square images, showcasing hand-drawn digits ranging from 0 to 9. We’re going to construct the Stable Diffusion architecture and train our model using these images. We’ll experiment with various parameter values during the training process. Once the model is trained, we’ll give it a digit, like 5, and it will generate an image of a hand-drawn digit 5 for us.
Setting the Stage
We’ll be working with a range of Python libraries throughout this project, so let’s import them:
Make sure to have these libraries installed to avoid any errors:
%%capture
# Install the 'einops' library for easy manipulation of tensors
!pip install einops
# Install the 'lpips' library for computing perceptual similarity between images
!pip install lpips# Import the PyTorch library for tensor operations.
import torch
# Import the neural network module from PyTorch.
import torch.nn as nn
# Import functional operations from PyTorch.
import torch.nn.functional as F
# Import the 'numpy' library for numerical operations.
import numpy as np
# Import the 'functools' module for higher-order functions.
import functools
# Import the Adam optimizer from PyTorch.
from torch.optim import Adam
# Import the DataLoader class from PyTorch for handling datasets.
from torch.utils.data import DataLoader
# Import data transformation functions from torchvision.
import torchvision.transforms as transforms
# Import the MNIST dataset from torchvision.
from torchvision.datasets import MNIST
# Import 'tqdm' for creating progress bars during training.
import tqdm
# Import 'trange' and 'tqdm' specifically for notebook compatibility.
from tqdm.notebook import trange, tqdm
# Import the learning rate scheduler from PyTorch.
from torch.optim.lr_scheduler import MultiplicativeLR, LambdaLR
# Import the 'matplotlib.pyplot' library for plotting graphs.
import matplotlib.pyplot as plt
# Import the 'make_grid' function from torchvision.utils for visualizing image grids.
from torchvision.utils import make_grid
# Importing the `rearrange` function from the `einops` library
from einops import rearrange
# Importing the `math` module for mathematical operations
import mathCreating basic forward diffusion
Let’s begin with forward diffusion. In basic terms, the diffusion equation is:
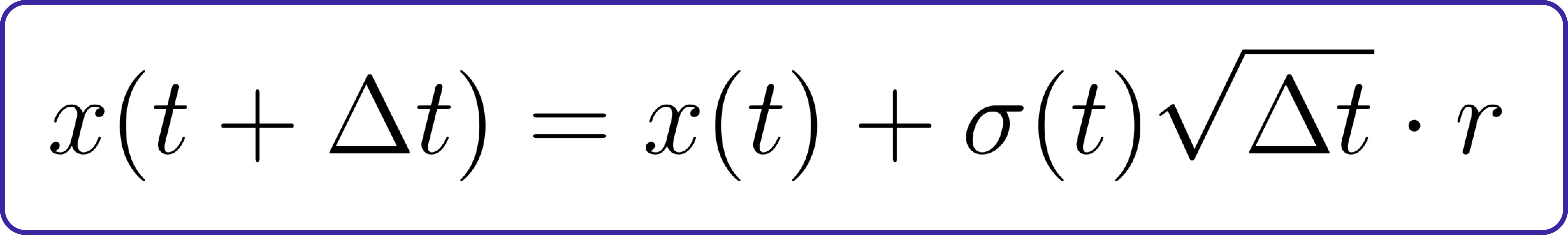
Here, σ(t)>0 is the noise strength, Δt is the step size, and r∼N(0,1) is a standard normal random variable. Simply put, we keep adding normally-distributed noise to our sample. Usually, the noise strength σ(t) is chosen to increase with time (as t gets larger).
# Forward diffusion for N steps in 1D.
def forward_diffusion_1D(x0, noise_strength_fn, t0, nsteps, dt):
"""
Parameters:
- x0: Initial sample value (scalar)
- noise_strength_fn: Function of time, outputs scalar noise strength
- t0: Initial time
- nsteps: Number of diffusion steps
- dt: Time step size
Returns:
- x: Trajectory of sample values over time
- t: Corresponding time points for the trajectory
"""
# Initialize the trajectory array
x = np.zeros(nsteps + 1)
# Set the initial sample value
x[0] = x0
# Generate time points for the trajectory
t = t0 + np.arange(nsteps + 1) * dt
# Perform Euler-Maruyama time steps for diffusion simulation
for i in range(nsteps):
# Get the noise strength at the current time
noise_strength = noise_strength_fn(t[i])
# Generate a random normal variable
random_normal = np.random.randn()
# Update the trajectory using Euler-Maruyama method
x[i + 1] = x[i] + random_normal * noise_strength
# Return the trajectory and corresponding time points
return x, tSetting the noise strength function to always equal 1.
# Example noise strength function: always equal to 1
def noise_strength_constant(t):
"""
Example noise strength function that returns a constant value (1).
Parameters:
- t: Time parameter (unused in this example)
Returns:
- Constant noise strength (1)
"""
return 1Now that we have defined our forward diffusion component, let’s check whether it is working correctly or not for different trials.
# Number of diffusion steps
nsteps = 100
# Initial time
t0 = 0
# Time step size
dt = 0.1
# Noise strength function
noise_strength_fn = noise_strength_constant
# Initial sample value
x0 = 0
# Number of tries for visualization
num_tries = 5
# Setting larger width and smaller height for the plot
plt.figure(figsize=(15, 3))
# Loop for multiple trials
for i in range(num_tries):
# Simulate forward diffusion
x, t = forward_diffusion_1D(x0, noise_strength_fn, t0, nsteps, dt)
# Plot the trajectory
plt.plot(t, x, label=f'Trial {i+1}') # Adding a label for each trial
# Labeling the plot
plt.xlabel('Time', fontsize=20)
plt.ylabel('Sample Value ($x$)', fontsize=20)
# Title of the plot
plt.title('Forward Diffusion Visualization', fontsize=20)
# Adding a legend to identify each trial
plt.legend()
# Show the plot
plt.show()

This visualization illustrates the forward diffusion process, which can be understood as slowly introducing noise to the starting sample. This leads to the creation of various samples as the diffusion process progresses, as depicted in the graph.
Creating basic reverse diffusion
To undo this diffusion process, we use a similar update rule:
s(x,t) is known as the score function. Knowing this function allows us to reverse the forward diffusion and convert noise back into our initial state.
If our starting point is always just one point at x0=0, and the noise strength is constant, then the score function is exactly equal to
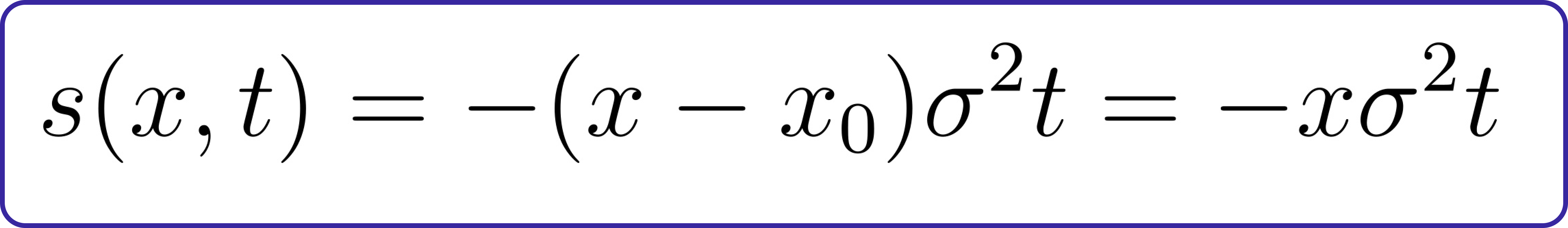
Now that we know the mathematical equations, let’s first code the 1D reverse diffusion function.
# Reverse diffusion for N steps in 1D.
def reverse_diffusion_1D(x0, noise_strength_fn, score_fn, T, nsteps, dt):
"""
Parameters:
- x0: Initial sample value (scalar)
- noise_strength_fn: Function of time, outputs scalar noise strength
- score_fn: Score function
- T: Final time
- nsteps: Number of diffusion steps
- dt: Time step size
Returns:
- x: Trajectory of sample values over time
- t: Corresponding time points for the trajectory
"""
# Initialize the trajectory array
x = np.zeros(nsteps + 1)
# Set the initial sample value
x[0] = x0
# Generate time points for the trajectory
t = np.arange(nsteps + 1) * dt
# Perform Euler-Maruyama time steps for reverse diffusion simulation
for i in range(nsteps):
# Calculate noise strength at the current time
noise_strength = noise_strength_fn(T - t[i])
# Calculate the score using the score function
score = score_fn(x[i], 0, noise_strength, T - t[i])
# Generate a random normal variable
random_normal = np.random.randn()
# Update the trajectory using the reverse Euler-Maruyama method
x[i + 1] = x[i] + score * noise_strength**2 * dt + noise_strength * random_normal * np.sqrt(dt)
# Return the trajectory and corresponding time points
return x, tNow, we will code a very simple score function, always equal to 1.
# Example score function: always equal to 1
def score_simple(x, x0, noise_strength, t):
"""
Parameters:
- x: Current sample value (scalar)
- x0: Initial sample value (scalar)
- noise_strength: Scalar noise strength at the current time
- t: Current time
Returns:
- score: Score calculated based on the provided formula
"""
# Calculate the score using the provided formula
score = - (x - x0) / ((noise_strength**2) * t)
# Return the calculated score
return scoreJust as we plot our forward diffusion function to check whether it is working correctly, we will do the same for our reverse diffusion function.
# Number of reverse diffusion steps
nsteps = 100
# Initial time for reverse diffusion
t0 = 0
# Time step size for reverse diffusion
dt = 0.1
# Function defining constant noise strength for reverse diffusion
noise_strength_fn = noise_strength_constant
# Example score function for reverse diffusion
score_fn = score_simple
# Initial sample value for reverse diffusion
x0 = 0
# Final time for reverse diffusion
T = 11
# Number of tries for visualization
num_tries = 5
# Setting larger width and smaller height for the plot
plt.figure(figsize=(15, 3))
# Loop for multiple trials
for i in range(num_tries):
# Draw from the noise distribution, which is diffusion for time T with noise strength 1
x0 = np.random.normal(loc=0, scale=T)
# Simulate reverse diffusion
x, t = reverse_diffusion_1D(x0, noise_strength_fn, score_fn, T, nsteps, dt)
# Plot the trajectory
plt.plot(t, x, label=f'Trial {i+1}') # Adding a label for each trial
# Labeling the plot
plt.xlabel('Time', fontsize=20)
plt.ylabel('Sample Value ($x$)', fontsize=20)
# Title of the plot
plt.title('Reverse Diffusion Visualized', fontsize=20)
# Adding a legend to identify each trial
plt.legend()
# Show the plot
plt.show()
This visualization shows that after the forward diffusion process creates a sample from the complex data distribution (as seen in the previous forward diffusion visualization), the reverse diffusion process maps it back to the simple distribution using a series of inverse transformations.
Learning Score Function
In real-world scenarios, we start without knowledge of the score function, our goal is to learn it. One approach involves training a neural network to ‘denoise’ samples using the denoising objective:

Here, p0(x0) represents our target distribution (e.g., images of cars and cats), and *x(noised) denotes the sample from the target distribution x0 after a single forward diffusion step. In simpler terms, [ x(noised) − x0 ] is essentially a normally-distributed** random variable.
Expressing the same idea in a way closer to the actual implementation:
It’s important to understand the concept that our aim is to predict the amount of noise added to each part of our sample effectively at every time t in the diffusion process and for every x0 in our original distribution (cars, cats, etc.)
In these expressions:
-
J represents the denoising objective.
-
E denotes the expectation.
-
t represents the time parameter.
-
x0 is a sample from the target distribution p0(x0).
-
x(noised) represents the target distribution sample x0 after one forward diffusion step.
-
s(⋅,⋅) represents the score function.
-
σ(t) is a function of time.
-
ϵ is a normally-distributed random variable.
So far, we’ve covered the basics of how forward and backward diffusion work, and we’ve explored how to learn our score function.
Time Embedding for Neural Network
Learning the score function is like transforming random noise into something meaningful. To do this, we use a neural network to approximate the score function. When dealing with images, we want our neural network to cooperate well with them and the score function we aim to learn depends on time, we need a method to ensure our neural network accurately responds to time variations. To achieve this, we can use a time embedding.
Instead of only providing our network with a single time value, we represent the current time using many sinusoidal features. By offering various representations of time, we aim to enhance our network’s ability to adapt to time changes. This approach allows us to effectively learn a time-dependent score function s(x,t).
To enable our neural network to interact with time, we need to create two modules.
# Define a module for Gaussian random features used to encode time steps.
class GaussianFourierProjection(nn.Module):
def __init__(self, embed_dim, scale=30.):
"""
Parameters:
- embed_dim: Dimensionality of the embedding (output dimension)
- scale: Scaling factor for random weights (frequencies)
"""
super().__init__()
# Randomly sample weights (frequencies) during initialization.
# These weights (frequencies) are fixed during optimization and are not trainable.
self.W = nn.Parameter(torch.randn(embed_dim // 2) * scale, requires_grad=False)
def forward(self, x):
"""
Parameters:
- x: Input tensor representing time steps
"""
# Calculate the cosine and sine projections: Cosine(2 pi freq x), Sine(2 pi freq x)
x_proj = x[:, None] * self.W[None, :] * 2 * np.pi
# Concatenate the sine and cosine projections along the last dimension
return torch.cat([torch.sin(x_proj), torch.cos(x_proj)], dim=-1)The GaussianFourierProjection function is designed to create a module for generating Gaussian random features, which will be used to represent time steps in our context. When we utilize this module, it generates random frequencies that remain fixed throughout the optimization process. Once we provide an input tensor x to the module, it computes sine and cosine projections by multiplying x with these pre-defined random frequencies. These projections are then concatenated to form a feature representation of the input, effectively capturing temporal patterns. This module is valuable in our task, where we aim to incorporate time-related information into our neural network.
# Define a module for a fully connected layer that reshapes outputs to feature maps.
class Dense(nn.Module):
def __init__(self, input_dim, output_dim):
"""
Parameters:
- input_dim: Dimensionality of the input features
- output_dim: Dimensionality of the output features
"""
super().__init__()
# Define a fully connected layer
self.dense = nn.Linear(input_dim, output_dim)
def forward(self, x):
"""
Parameters:
- x: Input tensor
Returns:
- Output tensor after passing through the fully connected layer
and reshaping to a 4D tensor (feature map)
"""
# Apply the fully connected layer and reshape the output to a 4D tensor
return self.dense(x)[..., None, None]
# This broadcasts the 2D tensor to a 4D tensor, adding the same value across space.Dense is designed to reshape the output of the fully connected layer into a 4D tensor, effectively converting it into a feature map. The module takes as input the dimensionality of the input features (input_dim) and the desired dimensionality of the output features (output_dim). During the forward pass, the input tensor x is processed through the fully connected layer (self.dense(x)) and the output is reshaped into a 4D tensor by adding two singleton dimensions at the end ([..., None, None]). This reshaping operation effectively transforms the output into a feature map suitable for further processing in convolutional layers. This operation broadcasts the 2D tensor to a 4D tensor by adding the same value across spatial dimensions.
Now that we’ve established the two modules for integrating time interaction into our neural network, it’s time to proceed with coding the main neural network.
Coding the U-Net Architecture with Concatenation
When dealing with images, our neural network needs to work seamlessly with them and capture the inherent features associated with images.
We opt for a U-Net architecture, which combines a CNN-like structure with downscaling/upscaling operations. This combination helps the network focus on image features at different spatial scales.
# Define a time-dependent score-based model built upon the U-Net architecture.
class UNet(nn.Module):
def __init__(self, marginal_prob_std, channels=[32, 64, 128, 256], embed_dim=256):
"""
Initialize a time-dependent score-based network.
Parameters:
- marginal_prob_std: A function that takes time t and gives the standard deviation
of the perturbation kernel p_{0t}(x(t) | x(0)).
- channels: The number of channels for feature maps of each resolution.
- embed_dim: The dimensionality of Gaussian random feature embeddings.
"""
super().__init__()
# Gaussian random feature embedding layer for time
self.time_embed = nn.Sequential(
GaussianFourierProjection(embed_dim=embed_dim),
nn.Linear(embed_dim, embed_dim)
)
# Encoding layers where the resolution decreases
self.conv1 = nn.Conv2d(1, channels[0], 3, stride=1, bias=False)
self.dense1 = Dense(embed_dim, channels[0])
self.gnorm1 = nn.GroupNorm(4, num_channels=channels[0])
self.conv2 = nn.Conv2d(channels[0], channels[1], 3, stride=2, bias=False)
self.dense2 = Dense(embed_dim, channels[1])
self.gnorm2 = nn.GroupNorm(32, num_channels=channels[1])
# Additional encoding layers (copied from the original code)
self.conv3 = nn.Conv2d(channels[1], channels[2], 3, stride=2, bias=False)
self.dense3 = Dense(embed_dim, channels[2])
self.gnorm3 = nn.GroupNorm(32, num_channels=channels[2])
self.conv4 = nn.Conv2d(channels[2], channels[3], 3, stride=2, bias=False)
self.dense4 = Dense(embed_dim, channels[3])
self.gnorm4 = nn.GroupNorm(32, num_channels=channels[3])
# Decoding layers where the resolution increases
self.tconv4 = nn.ConvTranspose2d(channels[3], channels[2], 3, stride=2, bias=False)
self.dense5 = Dense(embed_dim, channels[2])
self.tgnorm4 = nn.GroupNorm(32, num_channels=channels[2])
self.tconv3 = nn.ConvTranspose2d(channels[2] + channels[2], channels[1], 3, stride=2, bias=False, output_padding=1)
self.dense6 = Dense(embed_dim, channels[1])
self.tgnorm3 = nn.GroupNorm(32, num_channels=channels[1])
self.tconv2 = nn.ConvTranspose2d(channels[1] + channels[1], channels[0], 3, stride=2, bias=False, output_padding=1)
self.dense7 = Dense(embed_dim, channels[0])
self.tgnorm2 = nn.GroupNorm(32, num_channels=channels[0])
self.tconv1 = nn.ConvTranspose2d(channels[0] + channels[0], 1, 3, stride=1)
# The swish activation function
self.act = lambda x: x * torch.sigmoid(x)
self.marginal_prob_std = marginal_prob_std
def forward(self, x, t, y=None):
"""
Parameters:
- x: Input tensor
- t: Time tensor
- y: Target tensor (not used in this forward pass)
Returns:
- h: Output tensor after passing through the U-Net architecture
"""
# Obtain the Gaussian random feature embedding for t
embed = self.act(self.time_embed(t))
# Encoding path
h1 = self.conv1(x) + self.dense1(embed)
h1 = self.act(self.gnorm1(h1))
h2 = self.conv2(h1) + self.dense2(embed)
h2 = self.act(self.gnorm2(h2))
# Additional encoding path layers (copied from the original code)
h3 = self.conv3(h2) + self.dense3(embed)
h3 = self.act(self.gnorm3(h3))
h4 = self.conv4(h3) + self.dense4(embed)
h4 = self.act(self.gnorm4(h4))
# Decoding path
h = self.tconv4(h4)
h += self.dense5(embed)
h = self.act(self.tgnorm4(h))
h = self.tconv3(torch.cat([h, h3], dim=1))
h += self.dense6(embed)
h = self.act(self.tgnorm3(h))
h = self.tconv2(torch.cat([h, h2], dim=1))
h += self.dense7(embed)
h = self.act(self.tgnorm2(h))
h = self.tconv1(torch.cat([h, h1], dim=1))
# Normalize output
h = h / self.marginal_prob_std(t)[:, None, None, None]
return hWe created a model that understands how things change over time. It uses a special architecture called U-Net. Imagine you have a starting picture, and you want to see how it transforms over different moments in time. The model learns patterns and details from these transformations. The code defines how this learning happens, using various layers and computations. It makes sure the output, or the generated pictures, are properly adjusted based on the time information. It’s like a smart tool for understanding and predicting how things evolve visually.
Throughout the U-Net model’s architecture, the shape of tensors evolves as information passes through encoding and decoding paths. In the encoding path, which involves downsampling, tensors undergo shape reduction with each convolutional layer — h1, h2, h3, and h4 successively. In the decoding path, the transpose convolutional layers initiate the recovery of spatial information. The tensor h starts to restore the original spatial dimensions, and at each step (h4 to h1), features from earlier layers are added back to facilitate upsampling. Finally, the last layer, represented by h, produces the output, and a normalization step ensures appropriate scaling for the generated image. The specifics of tensor shapes depend on factors like filter sizes, strides, and padding used in the convolutional layers, shaping the model's ability to capture and reconstruct details effectively.
Coding the U-Net Architecture with Addition
Diffusion models can work well with various architectural choices. In the previous model we built, we combined the tensor from the down blocks using concatenation for skip connection. In the upcoming model we’ll code, we’ll simply add the tensor from the down blocks for skip connection.
# Define a time-dependent score-based model built upon the U-Net architecture.
class UNet_res(nn.Module):
def __init__(self, marginal_prob_std, channels=[32, 64, 128, 256], embed_dim=256):
"""
Parameters:
- marginal_prob_std: A function that takes time t and gives the standard deviation
of the perturbation kernel p_{0t}(x(t) | x(0)).
- channels: The number of channels for feature maps of each resolution.
- embed_dim: The dimensionality of Gaussian random feature embeddings.
"""
super().__init__()
# Gaussian random feature embedding layer for time
self.time_embed = nn.Sequential(
GaussianFourierProjection(embed_dim=embed_dim),
nn.Linear(embed_dim, embed_dim)
)
# Encoding layers where the resolution decreases
self.conv1 = nn.Conv2d(1, channels[0], 3, stride=1, bias=False)
self.dense1 = Dense(embed_dim, channels[0])
self.gnorm1 = nn.GroupNorm(4, num_channels=channels[0])
self.conv2 = nn.Conv2d(channels[0], channels[1], 3, stride=2, bias=False)
self.dense2 = Dense(embed_dim, channels[1])
self.gnorm2 = nn.GroupNorm(32, num_channels=channels[1])
self.conv3 = nn.Conv2d(channels[1], channels[2], 3, stride=2, bias=False)
self.dense3 = Dense(embed_dim, channels[2])
self.gnorm3 = nn.GroupNorm(32, num_channels=channels[2])
self.conv4 = nn.Conv2d(channels[2], channels[3], 3, stride=2, bias=False)
self.dense4 = Dense(embed_dim, channels[3])
self.gnorm4 = nn.GroupNorm(32, num_channels=channels[3])
# Decoding layers where the resolution increases
self.tconv4 = nn.ConvTranspose2d(channels[3], channels[2], 3, stride=2, bias=False)
self.dense5 = Dense(embed_dim, channels[2])
self.tgnorm4 = nn.GroupNorm(32, num_channels=channels[2])
self.tconv3 = nn.ConvTranspose2d(channels[2], channels[1], 3, stride=2, bias=False, output_padding=1)
self.dense6 = Dense(embed_dim, channels[1])
self.tgnorm3 = nn.GroupNorm(32, num_channels=channels[1])
self.tconv2 = nn.ConvTranspose2d(channels[1], channels[0], 3, stride=2, bias=False, output_padding=1)
self.dense7 = Dense(embed_dim, channels[0])
self.tgnorm2 = nn.GroupNorm(32, num_channels=channels[0])
self.tconv1 = nn.ConvTranspose2d(channels[0], 1, 3, stride=1)
# The swish activation function
self.act = lambda x: x * torch.sigmoid(x)
self.marginal_prob_std = marginal_prob_std
def forward(self, x, t, y=None):
"""
Parameters:
- x: Input tensor
- t: Time tensor
- y: Target tensor (not used in this forward pass)
Returns:
- h: Output tensor after passing through the U-Net architecture
"""
# Obtain the Gaussian random feature embedding for t
embed = self.act(self.time_embed(t))
# Encoding path
h1 = self.conv1(x) + self.dense1(embed)
h1 = self.act(self.gnorm1(h1))
h2 = self.conv2(h1) + self.dense2(embed)
h2 = self.act(self.gnorm2(h2))
h3 = self.conv3(h2) + self.dense3(embed)
h3 = self.act(self.gnorm3(h3))
h4 = self.conv4(h3) + self.dense4(embed)
h4 = self.act(self.gnorm4(h4))
# Decoding path
h = self.tconv4(h4)
h += self.dense5(embed)
h = self.act(self.tgnorm4(h))
h = self.tconv3(h + h3)
h += self.dense6(embed)
h = self.act(self.tgnorm3(h))
h = self.tconv2(h + h2)
h += self.dense7(embed)
h = self.act(self.tgnorm2(h))
h = self.tconv1(h + h1)
# Normalize output
h = h / self.marginal_prob_std(t)[:, None, None, None]
return hThe UNet_res model that we have just coded is a variant of the standard UNet model. While both models follow the U-Net architecture, the key difference lies in how skip connections are implemented. In the original UNet model, skip connections concatenate tensors from the encoding path with tensors in the decoding path. However, in the UNet_res model, skip connections involve directly adding tensors from the encoding path to the corresponding tensors in the decoding path. This variation in skip connection strategies can influence the information flow and interactions between different resolution levels, potentially affecting the model’s capacity to capture features and dependencies in the data.
Forward Diffusion Process with Exponential Noise
We will define the specific forward diffusion process:
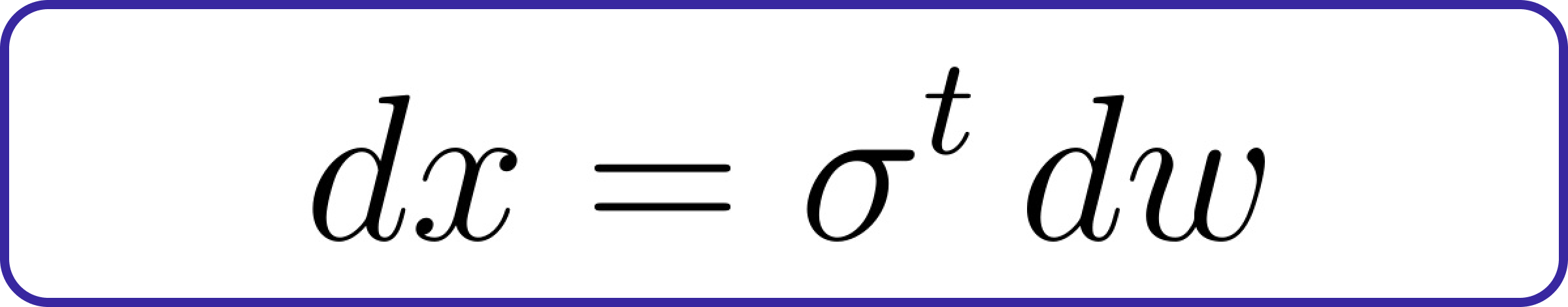
This formula represents a dynamic system where the variable x changes over time (t) with the introduction of noise (dw). The noise level is determined by the parameter σ, and it increases exponentially as time progresses.
Given this process and an initial value x(0), we can find an analytical solution for x(t):
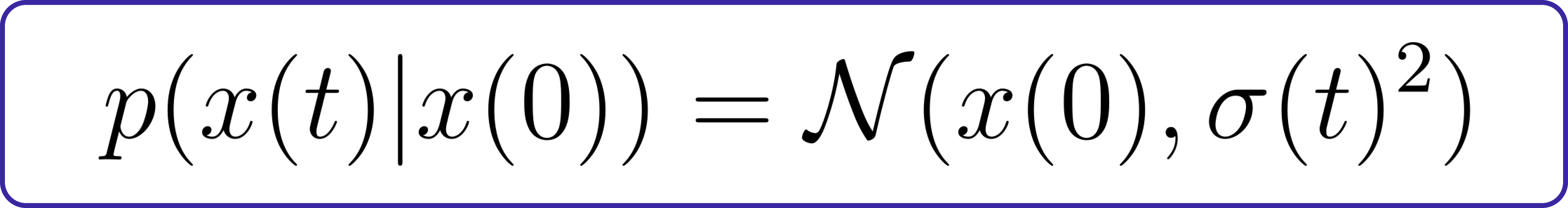
In this context, σ(t) is referred to as the marginal standard deviation. Essentially, it represents the variability of the distribution of x(t) given the initial value x(0).
For our specific case, the marginal standard deviation is calculated as:
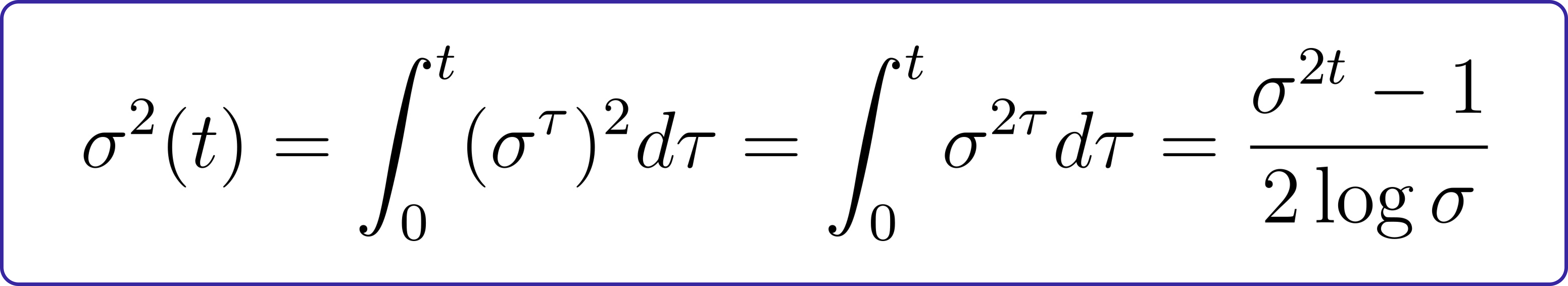
This formula provides a detailed understanding of how the noise level (σ) evolves over time, influencing the variability of the system.
# Using GPU
device = "cuda"
# Marginal Probability Standard Deviation Function
def marginal_prob_std(t, sigma):
"""
Compute the mean and standard deviation of $p_{0t}(x(t) | x(0))$.
Parameters:
- t: A vector of time steps.
- sigma: The $\sigma$ in our SDE.
Returns:
- The standard deviation.
"""
# Convert time steps to a PyTorch tensor
t = torch.tensor(t, device=device)
# Calculate and return the standard deviation based on the given formula
return torch.sqrt((sigma**(2 * t) - 1.) / 2. / np.log(sigma))Now that we have coded the function for marginal probability standard deviation, we can similarly code the diffusion coefficient.
# Using GPU
device = "cuda"
def diffusion_coeff(t, sigma):
"""
Compute the diffusion coefficient of our SDE.
Parameters:
- t: A vector of time steps.
- sigma: The $\sigma$ in our SDE.
Returns:
- The vector of diffusion coefficients.
"""
# Calculate and return the diffusion coefficients based on the given formula
return torch.tensor(sigma**t, device=device)
Now we initialize both marginal probability standard deviation and diffusion coefficient with sigma 25
# Sigma Value
sigma = 25.0
# marginal probability standard
marginal_prob_std_fn = functools.partial(marginal_prob_std, sigma=sigma)
# diffusion coefficient
diffusion_coeff_fn = functools.partial(diffusion_coeff, sigma=sigma)After coding both modules, it’s time to develop the loss function for our stable diffusion architecture.
Coding the Loss Function
Now, we’re putting together the U-Net we made earlier with a method to learn the score function. We’ll create a loss function and train the neural network.
def loss_fn(model, x, marginal_prob_std, eps=1e-5):
"""
The loss function for training score-based generative models.
Parameters:
- model: A PyTorch model instance that represents a time-dependent score-based model.
- x: A mini-batch of training data.
- marginal_prob_std: A function that gives the standard deviation of the perturbation kernel.
- eps: A tolerance value for numerical stability.
"""
# Sample time uniformly in the range (eps, 1-eps)
random_t = torch.rand(x.shape[0], device=x.device) * (1. - 2 * eps) + eps
# Find the noise std at the sampled time `t`
std = marginal_prob_std(random_t)
# Generate normally distributed noise
z = torch.randn_like(x)
# Perturb the input data with the generated noise
perturbed_x = x + z * std[:, None, None, None]
# Get the score from the model using the perturbed data and time
score = model(perturbed_x, random_t)
# Calculate the loss based on the score and noise
loss = torch.mean(torch.sum((score * std[:, None, None, None] + z)**2, dim=(1, 2, 3)))
return lossThis loss function figures out how wrong our model is while training. It involves picking a random time, getting the noise level, adding this noise to our data, and then checking how off our model’s prediction is from reality. The aim is to reduce this error during training.
Coding the Sampler
Stable Diffusion creates an image by starting with a totally random one. The noise predictor then guesses how noisy the image is, and this guessed noise is removed from the image. This whole cycle repeats several times, resulting in a clean image at the end.
This cleaning-up process is called “sampling” because Stable Diffusion produces a fresh image sample at each step. The way it creates these samples is called the “sampler” or “sampling method”.
Stable Diffusion has various options for creating image samples, and one method we’ll use is the Euler–Maruyama method, also known as the Euler method.
# Number of steps
num_steps = 500
def Euler_Maruyama_sampler(score_model,
marginal_prob_std,
diffusion_coeff,
batch_size=64,
x_shape=(1, 28, 28),
num_steps=num_steps,
device='cuda',
eps=1e-3, y=None):
"""
Generate samples from score-based models with the Euler-Maruyama solver.
Parameters:
- score_model: A PyTorch model that represents the time-dependent score-based model.
- marginal_prob_std: A function that gives the standard deviation of the perturbation kernel.
- diffusion_coeff: A function that gives the diffusion coefficient of the SDE.
- batch_size: The number of samplers to generate by calling this function once.
- x_shape: The shape of the samples.
- num_steps: The number of sampling steps, equivalent to the number of discretized time steps.
- device: 'cuda' for running on GPUs, and 'cpu' for running on CPUs.
- eps: The smallest time step for numerical stability.
- y: Target tensor (not used in this function).
Returns:
- Samples.
"""
# Initialize time and the initial sample
t = torch.ones(batch_size, device=device)
init_x = torch.randn(batch_size, *x_shape, device=device) * marginal_prob_std(t)[:, None, None, None]
# Generate time steps
time_steps = torch.linspace(1., eps, num_steps, device=device)
step_size = time_steps[0] - time_steps[1]
x = init_x
# Sample using Euler-Maruyama method
with torch.no_grad():
for time_step in tqdm(time_steps):
batch_time_step = torch.ones(batch_size, device=device) * time_step
g = diffusion_coeff(batch_time_step)
mean_x = x + (g**2)[:, None, None, None] * score_model(x, batch_time_step, y=y) * step_size
x = mean_x + torch.sqrt(step_size) * g[:, None, None, None] * torch.randn_like(x)
# Do not include any noise in the last sampling step.
return mean_xThis function generates image samples using the Euler–Maruyama method, combining a score-based model, a function for noise standard deviation, and a diffusion coefficient. It iteratively applies the method over a specified number of steps, returning the final set of generated samples.
Training U-Net Concatenation Architecture
We have developed two U-Net architectures: one utilizing addition and the other utilizing concatenation. To initiate training, we will use the U-Net architecture based on concatenation with the following hyperparameters: 50 epochs for training, a mini-batch size of 2048, and a learning rate of 5e-4. The training will be conducted on the MNIST dataset.
# Define the score-based model and move it to the specified device
score_model = torch.nn.DataParallel(UNet(marginal_prob_std=marginal_prob_std_fn))
score_model = score_model.to(device)
# Number of training epochs
n_epochs = 50
# Size of a mini-batch
batch_size = 2048
# Learning rate
lr = 5e-4
# Load the MNIST dataset and create a data loader
dataset = MNIST('.', train=True, transform=transforms.ToTensor(), download=True)
data_loader = DataLoader(dataset, batch_size=batch_size, shuffle=True, num_workers=4)
# Define the Adam optimizer for training the model
optimizer = Adam(score_model.parameters(), lr=lr)
# Progress bar for epochs
tqdm_epoch = trange(n_epochs)
for epoch in tqdm_epoch:
avg_loss = 0.
num_items = 0
# Iterate through mini-batches in the data loader
for x, y in tqdm(data_loader):
x = x.to(device)
# Calculate the loss and perform backpropagation
loss = loss_fn(score_model, x, marginal_prob_std_fn)
optimizer.zero_grad()
loss.backward()
optimizer.step()
avg_loss += loss.item() * x.shape[0]
num_items += x.shape[0]
# Print the averaged training loss for the current epoch
tqdm_epoch.set_description('Average Loss: {:5f}'.format(avg_loss / num_items))
# Save the model checkpoint after each epoch of training
torch.save(score_model.state_dict(), 'ckpt.pth')Upon executing the training code, the entire training process is expected to complete in approximately 7 minutes for each epoch. The average loss observed across epochs is 41.481, and the trained model will be saved in the current directory with the filename “ckpt.pth”.
Let’s visualize the results from our U-Net architecture based on concatenation. It’s important to note that we haven’t started working on developing a system where we pass a prompt to generate specific results. The current visualization is simply based on random inputs.
# Load the pre-trained checkpoint from disk.
device = 'cuda'
# Load the pre-trained model checkpoint
ckpt = torch.load('ckpt.pth', map_location=device)
score_model.load_state_dict(ckpt)
# Set sample batch size and number of steps
sample_batch_size = 64
num_steps = 500
# Choose the Euler-Maruyama sampler
sampler = Euler_Maruyama_sampler
# Generate samples using the specified sampler
samples = sampler(score_model,
marginal_prob_std_fn,
diffusion_coeff_fn,
sample_batch_size,
num_steps=num_steps,
device=device,
y=None)
# Clip samples to be in the range [0, 1]
samples = samples.clamp(0.0, 1.0)
# Visualize the generated samples
%matplotlib inline
import matplotlib.pyplot as plt
sample_grid = make_grid(samples, nrow=int(np.sqrt(sample_batch_size)))
# Plot the sample grid
plt.figure(figsize=(6, 6))
plt.axis('off')
plt.imshow(sample_grid.permute(1, 2, 0).cpu(), vmin=0., vmax=1.)
plt.show()
The current results are not satisfactory, as it is challenging to identify any numbers clearly. However, there is still a lot to cover in this blog, which will showcase promising results.
Training U-Net Addition Architecture
The U-Net architecture with concatenation did not perform well. However, let’s proceed with training the U-Net architecture based on addition and determine whether it yields improved results or not.
We will be using following hyperparameters: 75 epochs for training, a mini-batch size of 1024, and a learning rate of 10e-3. The training will be conducted on the MNIST dataset.
# Initialize the alternate U-Net model for training.
score_model = torch.nn.DataParallel(UNet_res(marginal_prob_std=marginal_prob_std_fn))
score_model = score_model.to(device)
# Set the number of training epochs, mini-batch size, and learning rate.
n_epochs = 75
batch_size = 1024
lr = 1e-3
# Load the MNIST dataset for training.
dataset = MNIST('.', train=True, transform=transforms.ToTensor(), download=True)
data_loader = DataLoader(dataset, batch_size=batch_size, shuffle=True, num_workers=4)
# Initialize the Adam optimizer with the specified learning rate.
optimizer = Adam(score_model.parameters(), lr=lr)
# Learning rate scheduler to adjust the learning rate during training.
scheduler = LambdaLR(optimizer, lr_lambda=lambda epoch: max(0.2, 0.98 ** epoch))
# Training loop over epochs.
tqdm_epoch = trange(n_epochs)
for epoch in tqdm_epoch:
avg_loss = 0.
num_items = 0
# Iterate over mini-batches in the training data loader.
for x, y in data_loader:
x = x.to(device)
# Compute the loss for the current mini-batch.
loss = loss_fn(score_model, x, marginal_prob_std_fn)
# Zero the gradients, backpropagate, and update the model parameters.
optimizer.zero_grad()
loss.backward()
optimizer.step()
# Accumulate the total loss and the number of processed items.
avg_loss += loss.item() * x.shape[0]
num_items += x.shape[0]
# Adjust the learning rate using the scheduler.
scheduler.step()
lr_current = scheduler.get_last_lr()[0]
# Print the average loss and learning rate for the current epoch.
print('{} Average Loss: {:5f} lr {:.1e}'.format(epoch, avg_loss / num_items, lr_current))
tqdm_epoch.set_description('Average Loss: {:5f}'.format(avg_loss / num_items))
# Save the model checkpoint after each epoch of training.
torch.save(score_model.state_dict(), 'ckpt_res.pth')0 Average Loss: 1154.632897 lr 9.8e-04
1 Average Loss: 300.499317 lr 9.6e-04
2 Average Loss: 203.206303 lr 9.4e-04
...
74 Average Loss: 24.750734 lr 2.2e-04Upon executing the training code, the entire training process is expected to complete in approximately 11 minutes for each epoch. The trained model will be saved in the current directory with the filename “ckpt_res.pth”.
Let’s visualize the results from our U-Net architecture based on addition.
# Load the pre-trained checkpoint from disk.
device = 'cuda'
# Load the pre-trained model checkpoint
ckpt = torch.load('ckpt_res.pth', map_location=device)
score_model.load_state_dict(ckpt)
# Set sample batch size and number of steps
sample_batch_size = 64
num_steps = 500
# Choose the Euler-Maruyama sampler
sampler = Euler_Maruyama_sampler
# Generate samples using the specified sampler
samples = sampler(score_model,
marginal_prob_std_fn,
diffusion_coeff_fn,
sample_batch_size,
num_steps=num_steps,
device=device,
y=None)
# Clip samples to be in the range [0, 1]
samples = samples.clamp(0.0, 1.0)
# Visualize the generated samples
%matplotlib inline
import matplotlib.pyplot as plt
sample_grid = make_grid(samples, nrow=int(np.sqrt(sample_batch_size)))
# Plot the sample grid
plt.figure(figsize=(6, 6))
plt.axis('off')
plt.imshow(sample_grid.permute(1, 2, 0).cpu(), vmin=0., vmax=1.)
plt.show()
Building Attention Layers
When creating attention models, we usually have three main parts:
-
Cross Attention: Handles self/cross attention for sequences.
-
Transformer Block: Combines attention with a neural network for processing.
-
Spatial Transformer: Transforms the spatial tensor in a U-net to a sequential form and vice versa.
Let’s break down the math behind attention models in simpler terms. In QKV (query-key-value) attention, we represent queries, keys, and values as vectors. These vectors help us connect words or images on one side of a translation task to the other side.
These vectors (q, k, v) are linearly related to the encoder’s hidden state vectors (e) and the decoder’s hidden state vectors (h):
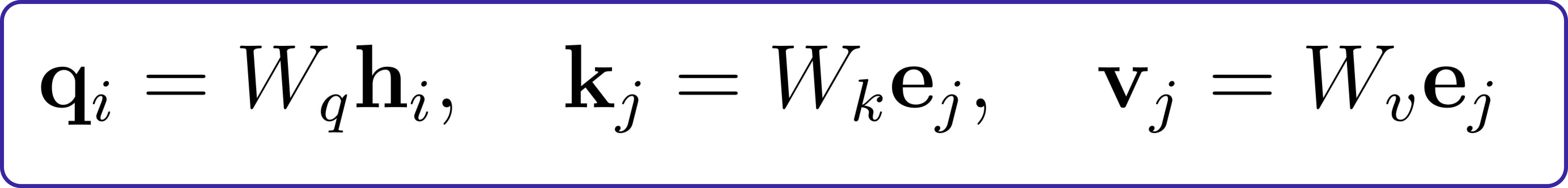
To decide what to ‘pay attention’ to, we calculate the inner product (similarity) of each key (k) and query (q). To ensure the values are reasonable, we normalize them by the length of the query vectors (qi).
The final attention distribution is obtained by applying softmax to these values:
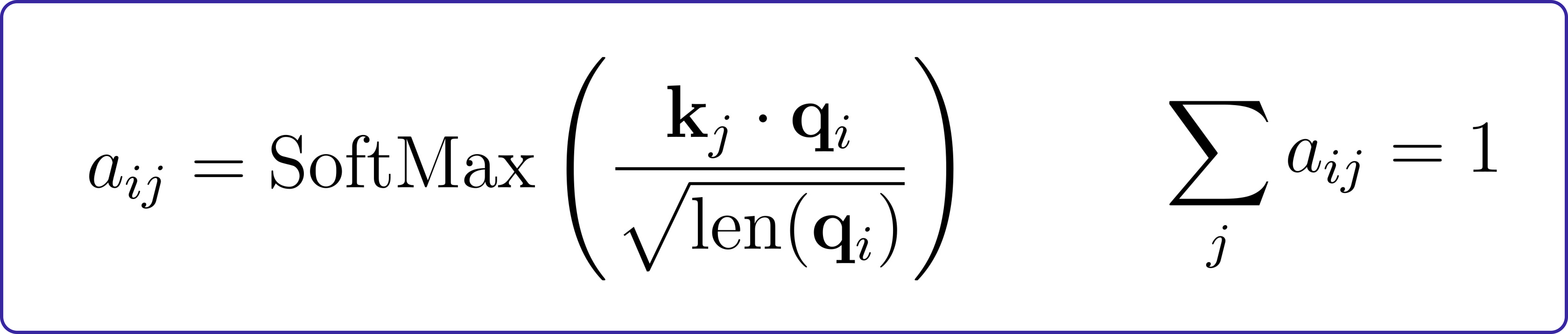
This attention distribution helps pick out a relevant combination of features. For instance, when translating the phrase “This is cool” from English to French, the correct answer (“c’est cool”) involves paying attention to both words simultaneously, rather than translating each word separately. Mathematically, we use the attention distribution to weight the values (vj):
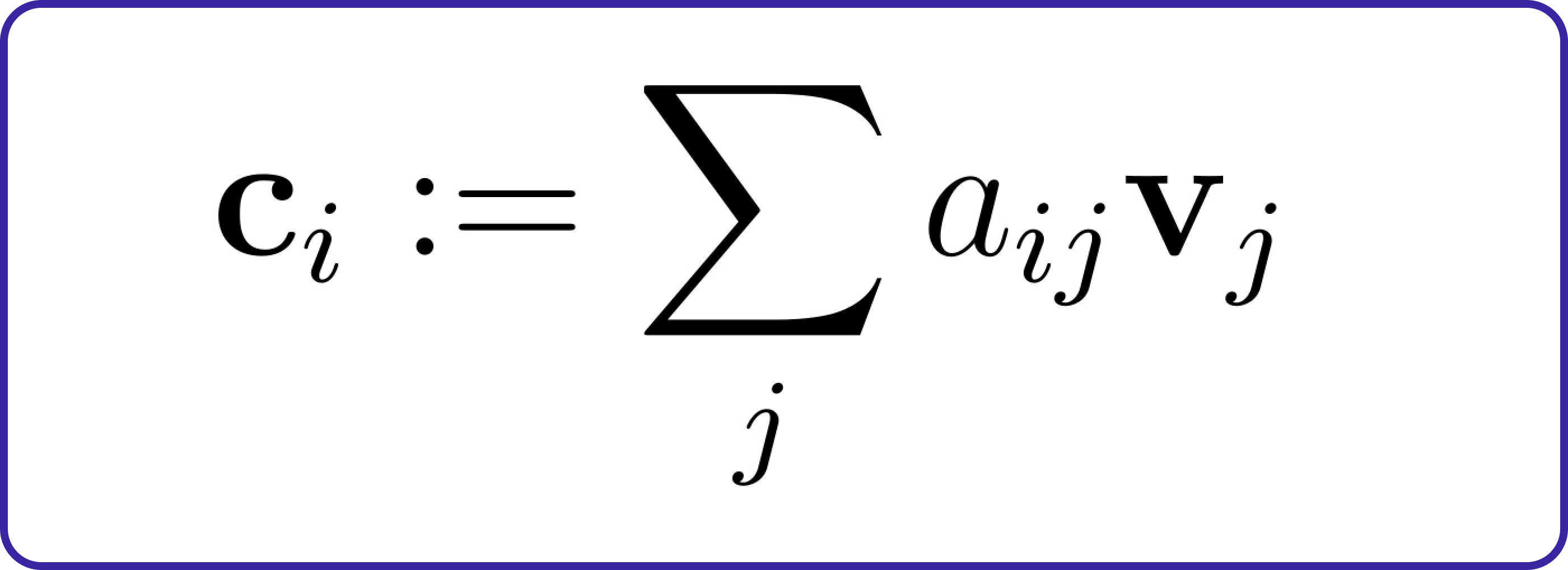
Now that we understand the basics of attention and the three attention modules we need to build, let’s begin coding them.
Let’s start by coding the first attention layer, which is CrossAttention.
class CrossAttention(nn.Module):
def __init__(self, embed_dim, hidden_dim, context_dim=None, num_heads=1):
"""
Initialize the CrossAttention module.
Parameters:
- embed_dim: The dimensionality of the output embeddings.
- hidden_dim: The dimensionality of the hidden representations.
- context_dim: The dimensionality of the context representations (if not self attention).
- num_heads: Number of attention heads (currently supports 1 head).
Note: For simplicity reasons, the implementation assumes 1-head attention.
Feel free to implement multi-head attention using fancy tensor manipulations.
"""
super(CrossAttention, self).__init__()
self.hidden_dim = hidden_dim
self.context_dim = context_dim
self.embed_dim = embed_dim
# Linear layer for query projection
self.query = nn.Linear(hidden_dim, embed_dim, bias=False)
# Check if self-attention or cross-attention
if context_dim is None:
self.self_attn = True
self.key = nn.Linear(hidden_dim, embed_dim, bias=False)
self.value = nn.Linear(hidden_dim, hidden_dim, bias=False)
else:
self.self_attn = False
self.key = nn.Linear(context_dim, embed_dim, bias=False)
self.value = nn.Linear(context_dim, hidden_dim, bias=False)
def forward(self, tokens, context=None):
"""
Forward pass of the CrossAttention module.
Parameters:
- tokens: Input tokens with shape [batch, sequence_len, hidden_dim].
- context: Context information with shape [batch, context_seq_len, context_dim].
If self_attn is True, context is ignored.
Returns:
- ctx_vecs: Context vectors after attention with shape [batch, sequence_len, embed_dim].
"""
if self.self_attn:
# Self-attention case
Q = self.query(tokens)
K = self.key(tokens)
V = self.value(tokens)
else:
# Cross-attention case
Q = self.query(tokens)
K = self.key(context)
V = self.value(context)
# Compute score matrices, attention matrices, and context vectors
scoremats = torch.einsum("BTH,BSH->BTS", Q, K) # Inner product of Q and K, a tensor
attnmats = F.softmax(scoremats / math.sqrt(self.embed_dim), dim=-1) # Softmax of scoremats
ctx_vecs = torch.einsum("BTS,BSH->BTH", attnmats, V) # Weighted average value vectors by attnmats
return ctx_vecsThe CrossAttention class is a module designed for handling attention mechanisms in neural networks. It takes input tokens and, optionally, context information. If used for self-attention, it focuses on relationships within the input tokens. In the case of cross-attention, it considers the interaction between input tokens and context information. The module employs linear projections for query, key, and value transformations. It calculates score matrices, applies softmax for attention weights, and computes context vectors by combining the weighted values based on attention weights. This mechanism allows the network to selectively focus on different parts of the input or context, aiding in capturing relevant information during the learning process. The forward method implements these operations, returning context vectors after attention.
Let’s proceed to the second attention layer, known as TransformerBlock.
class TransformerBlock(nn.Module):
"""The transformer block that combines self-attn, cross-attn, and feed forward neural net"""
def __init__(self, hidden_dim, context_dim):
"""
Initialize the TransformerBlock.
Parameters:
- hidden_dim: The dimensionality of the hidden state.
- context_dim: The dimensionality of the context tensor.
Note: For simplicity, the self-attn and cross-attn use the same hidden_dim.
"""
super(TransformerBlock, self).__init__()
# Self-attention module
self.attn_self = CrossAttention(hidden_dim, hidden_dim)
# Cross-attention module
self.attn_cross = CrossAttention(hidden_dim, hidden_dim, context_dim)
# Layer normalization modules
self.norm1 = nn.LayerNorm(hidden_dim)
self.norm2 = nn.LayerNorm(hidden_dim)
self.norm3 = nn.LayerNorm(hidden_dim)
# Implement a 2-layer MLP with K * hidden_dim hidden units, and nn.GELU nonlinearity
self.ffn = nn.Sequential(
nn.Linear(hidden_dim, 3 * hidden_dim),
nn.GELU(),
nn.Linear(3 * hidden_dim, hidden_dim)
)
def forward(self, x, context=None):
"""
Forward pass of the TransformerBlock.
Parameters:
- x: Input tensor with shape [batch, sequence_len, hidden_dim].
- context: Context tensor with shape [batch, context_seq_len, context_dim].
Returns:
- x: Output tensor after passing through the TransformerBlock.
"""
# Apply self-attention with layer normalization and residual connection
x = self.attn_self(self.norm1(x)) + x
# Apply cross-attention with layer normalization and residual connection
x = self.attn_cross(self.norm2(x), context=context) + x
# Apply feed forward neural network with layer normalization and residual connection
x = self.ffn(self.norm3(x)) + x
return xThe TransformerBlock class represents a building block in a transformer model, incorporating self-attention, cross-attention, and a feed-forward neural network. It takes input tensors with shape [batch, sequence_len, hidden_dim] and, optionally, a context tensor with shape [batch, context_seq_len, context_dim]. The self-attention and cross-attention modules are followed by layer normalization and a residual connection. Additionally, the block includes a two-layer MLP with a GELU nonlinearity for further non-linear transformations. The output is obtained after passing through the TransformerBlock.
Let’s proceed to the final attention layer, known as SpatialTransformer.
class SpatialTransformer(nn.Module):
def __init__(self, hidden_dim, context_dim):
"""
Initialize the SpatialTransformer.
Parameters:
- hidden_dim: The dimensionality of the hidden state.
- context_dim: The dimensionality of the context tensor.
"""
super(SpatialTransformer, self).__init__()
# TransformerBlock for spatial transformation
self.transformer = TransformerBlock(hidden_dim, context_dim)
def forward(self, x, context=None):
"""
Forward pass of the SpatialTransformer.
Parameters:
- x: Input tensor with shape [batch, channels, height, width].
- context: Context tensor with shape [batch, context_seq_len, context_dim].
Returns:
- x: Output tensor after applying spatial transformation.
"""
b, c, h, w = x.shape
x_in = x
# Combine the spatial dimensions and move the channel dimension to the end
x = rearrange(x, "b c h w -> b (h w) c")
# Apply the sequence transformer
x = self.transformer(x, context)
# Reverse the process
x = rearrange(x, 'b (h w) c -> b c h w', h=h, w=w)
# Residue connection
return x + x_inNow, you can incorporate SpatialTransformer layers into our U-Net architecture.
Coding the U-Net Architecture with Spatial Transformer
We’re going to code our U-Net architecture using the attention layers created in the previous step.
class UNet_Tranformer(nn.Module):
"""A time-dependent score-based model built upon U-Net architecture."""
def __init__(self, marginal_prob_std, channels=[32, 64, 128, 256], embed_dim=256,
text_dim=256, nClass=10):
"""
Initialize a time-dependent score-based network.
Parameters:
- marginal_prob_std: A function that takes time t and gives the standard deviation
of the perturbation kernel p_{0t}(x(t) | x(0)).
- channels: The number of channels for feature maps of each resolution.
- embed_dim: The dimensionality of Gaussian random feature embeddings of time.
- text_dim: The embedding dimension of text/digits.
- nClass: Number of classes to model.
"""
super().__init__()
# Gaussian random feature embedding layer for time
self.time_embed = nn.Sequential(
GaussianFourierProjection(embed_dim=embed_dim),
nn.Linear(embed_dim, embed_dim)
)
# Encoding layers where the resolution decreases
self.conv1 = nn.Conv2d(1, channels[0], 3, stride=1, bias=False)
self.dense1 = Dense(embed_dim, channels[0])
self.gnorm1 = nn.GroupNorm(4, num_channels=channels[0])
self.conv2 = nn.Conv2d(channels[0], channels[1], 3, stride=2, bias=False)
self.dense2 = Dense(embed_dim, channels[1])
self.gnorm2 = nn.GroupNorm(32, num_channels=channels[1])
self.conv3 = nn.Conv2d(channels[1], channels[2], 3, stride=2, bias=False)
self.dense3 = Dense(embed_dim, channels[2])
self.gnorm3 = nn.GroupNorm(32, num_channels=channels[2])
self.attn3 = SpatialTransformer(channels[2], text_dim)
self.conv4 = nn.Conv2d(channels[2], channels[3], 3, stride=2, bias=False)
self.dense4 = Dense(embed_dim, channels[3])
self.gnorm4 = nn.GroupNorm(32, num_channels=channels[3])
self.attn4 = SpatialTransformer(channels[3], text_dim)
# Decoding layers where the resolution increases
self.tconv4 = nn.ConvTranspose2d(channels[3], channels[2], 3, stride=2, bias=False)
self.dense5 = Dense(embed_dim, channels[2])
self.tgnorm4 = nn.GroupNorm(32, num_channels=channels[2])
self.tconv3 = nn.ConvTranspose2d(channels[2], channels[1], 3, stride=2, bias=False, output_padding=1)
self.dense6 = Dense(embed_dim, channels[1])
self.tgnorm3 = nn.GroupNorm(32, num_channels=channels[1])
self.tconv2 = nn.ConvTranspose2d(channels[1], channels[0], 3, stride=2, bias=False, output_padding=1)
self.dense7 = Dense(embed_dim, channels[0])
self.tgnorm2 = nn.GroupNorm(32, num_channels=channels[0])
self.tconv1 = nn.ConvTranspose2d(channels[0], 1, 3, stride=1)
# The swish activation function
self.act = nn.SiLU()
self.marginal_prob_std = marginal_prob_std
self.cond_embed = nn.Embedding(nClass, text_dim)
def forward(self, x, t, y=None):
"""
Forward pass of the UNet_Transformer model.
Parameters:
- x: Input tensor.
- t: Time tensor.
- y: Target tensor.
Returns:
- h: Output tensor after passing through the UNet_Transformer architecture.
"""
# Obtain the Gaussian random feature embedding for t
embed = self.act(self.time_embed(t))
y_embed = self.cond_embed(y).unsqueeze(1)
# Encoding path
h1 = self.conv1(x) + self.dense1(embed)
h1 = self.act(self.gnorm1(h1))
h2 = self.conv2(h1) + self.dense2(embed)
h2 = self.act(self.gnorm2(h2))
h3 = self.conv3(h2) + self.dense3(embed)
h3 = self.act(self.gnorm3(h3))
h3 = self.attn3(h3, y_embed)
h4 = self.conv4(h3) + self.dense4(embed)
h4 = self.act(self.gnorm4(h4))
h4 = self.attn4(h4, y_embed)
# Decoding path
h = self.tconv4(h4) + self.dense5(embed)
h = self.act(self.tgnorm4(h))
h = self.tconv3(h + h3) + self.dense6(embed)
h = self.act(self.tgnorm3(h))
h = self.tconv2(h + h2) + self.dense7(embed)
h = self.act(self.tgnorm2(h))
h = self.tconv1(h + h1)
# Normalize output
h = h / self.marginal_prob_std(t)[:, None, None, None]
return h
Now that we’ve implemented the U-Net architecture with attention layers, it’s time to update our loss function.
Updating U-Net Loss with Denoising Condition
Let’s update the loss function by incorporating the y information during training.
def loss_fn_cond(model, x, y, marginal_prob_std, eps=1e-5):
"""The loss function for training score-based generative models with conditional information.
Parameters:
- model: A PyTorch model instance that represents a time-dependent score-based model.
- x: A mini-batch of training data.
- y: Conditional information (target tensor).
- marginal_prob_std: A function that gives the standard deviation of the perturbation kernel.
- eps: A tolerance value for numerical stability.
Returns:
- loss: The calculated loss.
"""
# Sample time uniformly in the range [eps, 1-eps]
random_t = torch.rand(x.shape[0], device=x.device) * (1. - eps) + eps
# Generate random noise with the same shape as the input
z = torch.randn_like(x)
# Compute the standard deviation of the perturbation kernel at the sampled time
std = marginal_prob_std(random_t)
# Perturb the input data with the generated noise and scaled by the standard deviation
perturbed_x = x + z * std[:, None, None, None]
# Get the model's score for the perturbed input, considering conditional information
score = model(perturbed_x, random_t, y=y)
# Calculate the loss using the score and perturbation
loss = torch.mean(torch.sum((score * std[:, None, None, None] + z)**2, dim=(1, 2, 3)))
return lossTraining U-Net Architecture With Attention Layers
The advantage of training the U-Net architecture based on the attention layer is that, once trained, we can provide a specific number for our stable diffusion model to draw. Let’s initiate the training process with the following hyperparameters: 100 epochs, a mini-batch size of 1024, and a learning rate of 10e-3. The training will be performed using the MNIST dataset.
# Specify whether to continue training or initialize a new model
continue_training = False # Either True or False
if not continue_training:
# Initialize a new UNet with Transformer model
score_model = torch.nn.DataParallel(UNet_Tranformer(marginal_prob_std=marginal_prob_std_fn))
score_model = score_model.to(device)
# Set training hyperparameters
n_epochs = 100 #{'type':'integer'}
batch_size = 1024 #{'type':'integer'}
lr = 10e-4 #{'type':'number'}
# Load the MNIST dataset and create a data loader
dataset = MNIST('.', train=True, transform=transforms.ToTensor(), download=True)
data_loader = DataLoader(dataset, batch_size=batch_size, shuffle=True, num_workers=4)
# Define the optimizer and learning rate scheduler
optimizer = Adam(score_model.parameters(), lr=lr)
scheduler = LambdaLR(optimizer, lr_lambda=lambda epoch: max(0.2, 0.98 ** epoch))
# Use tqdm to display a progress bar over epochs
tqdm_epoch = trange(n_epochs)
for epoch in tqdm_epoch:
avg_loss = 0.
num_items = 0
# Iterate over batches in the data loader
for x, y in tqdm(data_loader):
x = x.to(device)
# Compute the loss using the conditional score-based model
loss = loss_fn_cond(score_model, x, y, marginal_prob_std_fn)
optimizer.zero_grad()
loss.backward()
optimizer.step()
avg_loss += loss.item() * x.shape[0]
num_items += x.shape[0]
# Adjust learning rate using the scheduler
scheduler.step()
lr_current = scheduler.get_last_lr()[0]
# Print epoch information including average loss and current learning rate
print('{} Average Loss: {:5f} lr {:.1e}'.format(epoch, avg_loss / num_items, lr_current))
tqdm_epoch.set_description('Average Loss: {:5f}'.format(avg_loss / num_items))
# Save the model checkpoint after each epoch of training
torch.save(score_model.state_dict(), 'ckpt_transformer.pth')0 Average Loss: 1010.038110 lr 9.8e-04Upon executing the training code, the entire training process is expected to complete in approximately 20 minutes. The trained model will be saved in the current directory with the filename “ckpt_transformer.pth”.
Generating Images
Now, with the addition of conditional generation through attention layers, we can instruct our stable diffusion model to draw any digit. Let’s observe its outcome when tasked to draw the digit 9.
## Load the pre-trained checkpoint from disk.
# device = 'cuda' ['cuda', 'cpu'] {'type':'string'}
ckpt = torch.load('ckpt_transformer.pth', map_location=device)
score_model.load_state_dict(ckpt)
########### Specify the digit for which to generate samples
###########
digit = 9
###########
###########
# Set the batch size for generating samples
sample_batch_size = 64
# Set the number of steps for the Euler-Maruyama sampler
num_steps = 250
# Choose the sampler type (Euler-Maruyama, pc_sampler, ode_sampler)
sampler = Euler_Maruyama_sampler # ['Euler_Maruyama_sampler', 'pc_sampler', 'ode_sampler'] {'type': 'raw'}
# score_model.eval()
## Generate samples using the specified sampler.
samples = sampler(score_model,
marginal_prob_std_fn,
diffusion_coeff_fn,
sample_batch_size,
num_steps=num_steps,
device=device,
y=digit*torch.ones(sample_batch_size, dtype=torch.long))
## Sample visualization.
samples = samples.clamp(0.0, 1.0)
%matplotlib inline
import matplotlib.pyplot as plt
# Create a grid of samples for visualization
sample_grid = make_grid(samples, nrow=int(np.sqrt(sample_batch_size)))
# Plot the generated samples
plt.figure(figsize=(6,6))
plt.axis('off')
plt.imshow(sample_grid.permute(1, 2, 0).cpu(), vmin=0., vmax=1.)
plt.show()<ipython-input-14-a1f1fa6cc02f>:17: UserWarning: To copy construct from a tensor, it is recommended to use sourceTensor.clone().detach() or sourceTensor.clone().detach().requires_grad_(True), rather than torch.tensor(sourceTensor).
t = torch.tensor(t, device=device)
0%| | 0/250 [00:00<?, ?it/s]
<ipython-input-15-4946fa702d78>:16: UserWarning: To copy construct from a tensor, it is recommended to use sourceTensor.clone().detach() or sourceTensor.clone().detach().requires_grad_(True), rather than torch.tensor(sourceTensor).
return torch.tensor(sigma**t, device=device)
Here is the visualization of all the digits generated by our stable diffusion architecture.

What’s Next
We trained the stable diffusion architecture on the MNIST dataset, which is relatively small. You can experiment with training the same architecture on the CelebA dataset with slight modifications. I attempted it, but it crashed the Colab GPU, indicating that even a modest stable diffusion model demands substantial computational power. Alternatively, you can explore finetuning existing open-source versions of Stable Diffusion.
I hope this provides you with a solid grasp of the practical implementation of stable diffusion. Check out my other blogs for further insights: