CLASIFICADOR DE "QUOTES", GENERADOR DE DIÁLOGO Y VISUALIZACIONES VARIAS - SERIE FRIENDS:
Siempre he sido una fan de la serie friends, motivo por el cuál decidí hacer mi proyecto sobre la serie, pensando también en los fans que hay en todo el mundo. También encontré muy interesante la clase de NLP, así que quise profundizar un poco más en el tema.
OBJETIVO DEL PROYECTO
Crear un clasificador de "quotes", un generador de diálogo y visualizaciones varias para publicarlos en alguna web de friends en honor a la reunión que ha tenido lugar este año.
DATASETS
Los datasets utilizados son:
* **"friends_quotes"** : dataset de Kaggle https://www.kaggle.com/ryanstonebraker/friends-transcript: este dataset incluye los guiones de casi todos los capítulos de la serie. El dataset contiene las siguientes columnas:
* author
* episode_number
* episode_title
* quote
* quote_order
* season
* **"Guest_Stars_DF"** : dataset creado a partir del friends_quotes dataset y modificado manualmente. Este contiene las líneas que han tenido diferentes actores/actrices invitados/as a la serie durante las 10 temporadas: Este dataset lo completé manualmente con información encontrada en varios artículos por internet.
* https://www.radiotimes.com/tv/comedy/best-friends-guest-stars/
* https://www.bustle.com/entertainment/23313-73-famous-friends-guest-stars-you-totally-forgot-were-ever-on-the-show
* **"season1_df_modified"** : dataset creado a partir del friends_quotes dataset y modificado manualmente. Este contiene las conversaciones por parejas (no contiene las conversaciones grupales), de los 9 personajes que más frases tienen en la primera temporada
* **"script_ross"** : dataset creado a partir del friends_quotes dataset y modificado manualmente. Este contiene los diálogos entre Ross y otras personas de la serie en la primera temporada --> escogí a Ross ya que era el personaje con más diálogo en la primera temporada por parejas.
PREGUNTAS
PREGUNTA 1: ¿Cuáles son los 9 personajes con más líneas de texto en cada temporada?
Para responder esta pregunta he visualizado un countplot con seaborn y he filtrado las diferentes temporadas con ipywidgets.
PREGUNTA 2: ¿Cuáles de estos personajes hablan más entre ellos en la primera temporada?
Con la información del count plot podemos ver que los 9 personajes que más líneas de texto tienen en la primera temporada son: Ross,Monica, Rachel, Chandler, Joey, Phoebe, Carol, Susan, Janice. He representado las conversaciones entre ellos mediante un nx.Graph().
PREGUNTA 3: ¿Qué actores/actrices invitados aparecieron durante las 10 temporadas?
He visualizado mediante un bar plot con plotly.express la evolución de los/las actores/actrices invitados/as a lo largo de las 10 temporadas, mostrando también la cantidad de líneas de texto de cada uno de ellos.
PREGUNTA 4: ¿Quién de los 6 personajes principales es más positivo/negativo?
Para hacer este análisis he utilizado:
* **CountVectorizer**
* **Librería Textblob**: he considerado palabras positivas aquellas palabras con una puntuación superior a 0.5 y negativas aquellas con una puntación inferior a -0.5
He seleccionado las 10 palabras positivas y negativas más utilizadas por personaje y representado los resultados con un "diverging bar chart" mediante ploty y ipywidgets
PREGUNTA 5: Clasificador de "quotes": ¿Quién ha dicho qué?
He intentado hacer un clasificador de "quotes"
* Primero intenté utilizar el método TF-IDF y utilicé:
* Stemming, Lemmatization, StopWords
* TfidfVectorizer, utilizando diferentes valores de "ngram_range", "min_df"
* El modelo NearestNeighbours (Unsupervised) y KNNeighbours (supervised)
* La clasificación con 2 personajes (Ross y Rachel) y luego con los seis:
Pero la confusion_matrix y el classification_report no fueron los esperados.
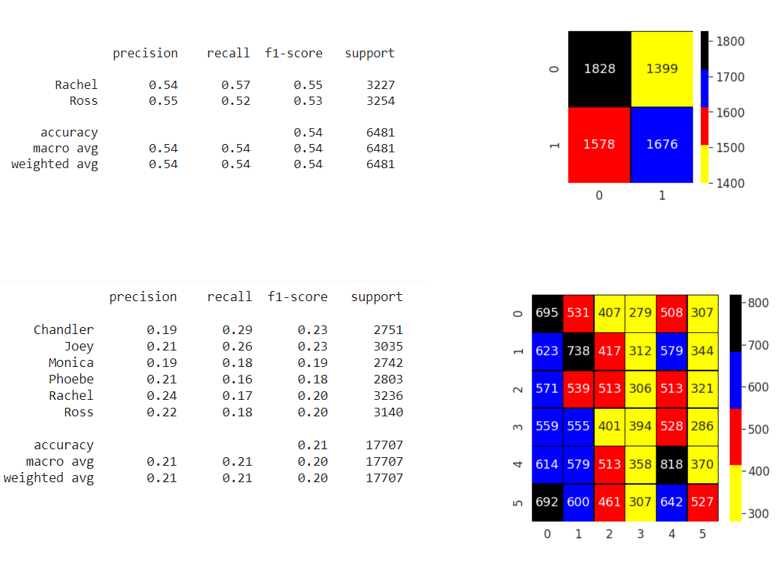
* Como segundo opción intenté utilizar el modelo BERT, pero los resultados no mejoraron mucho.
Realmente creo que el problema no son los modelos utilizados, sino los datos analizados. A pesar de que la mayoría de personajes tiene "quotes" que dicen bastante a menudo (ej: Joey (How are you doing?), Ross (We were on a break!). Monica (I know!)), no las dicen tan a menudo, y a pesar de ser unos personajes muy diferentes los unos de los otros, probablemente todos utilizan frases muy parecidas, y lo que los diferencia no es tanto su forma de hablar, sino su personalidad, sus gestos, etc.
PREGUNTA 6: Generador de diálogo: ¿qué diría Ross?
Dado que Ross es el personaje con más líneas de texto en las conversaciones por parejas de la primera temporada, he decidido crear un generador de diálogo para poder tener una conversación con él. He adaptado el excel manualmente para asegurarme que el diálogo fuera de pregunta- respuesta, es decir, que no hubiese dos líneas seguidas de un mismo personaje.
* El código utilizado es el especificado en este artículo: https://towardsdatascience.com/make-your-own-rick-sanchez-bot-with-transformers-and-dialogpt-fine-tuning-f85e6d1f4e30
* El modelo utilizado es GPT2 y he utilizado el dataset ""script_ross" para entrenar el modelo y hacer el finetuning con el DialoGPT de Hugging Face
Este es un ejemplo del diálogo obtenido:
