Build a knowledge base with domain specific documents
In any business, word documents are a common occurence. They contain information in the form of raw text, tables and images. All of them contain important facts. The data used in this code pattern comes from two Wikipedia articles. The first is taken from the Wikipedia page of oncologist Suresh H. Advani the second is from the Wikipedia page about Oncology. These files are zipped up as archive.zip.
In the figure below, there is a textual information about an oncologist Suresh H. Advani present in a word document. The table consists of the awards that he has been awarded by various organisations.

In this Code pattern, we address the problem of extracting knowledge out of text and tables in word documents. A knowledge graph is built from the knowledge extracted making the knowledge queryable.
Some of the challenges in extracting knowledge from word documents are:
- The Natural Language Processing (NLP) tools cannot access the text inside word documents. The word documents need to be converted to plain text files.
- There are business and domain experts who understand the keywords and entities that are present in the documents. But training the NLP tool to extract domain specific keywords and entities is a big effort. Also, it is impractical in many scenarios to find sufficient number of documents to train the NLP tool to process the text.
This pattern uses the below methodology to overcome the challenges:
- The
python package mammothlibrary is used to convert.docxfiles to html (semi-structured format). - Watson Natural Language Understanding (Watson NLU) is used to extract the common entities.
- A rules based approach that is explained in the code pattern Extend Watson text Classification is used to augment the output from Watson NLU. The rules based approach does not require training documents or training effort. A configuration file is taken as input by the algorithm. This file needs to be configured by the domain expert.
- Watson NLU is used to extract the relations between entities.
- A rules based approach that is explained in the code pattern Watson Document Correlation is used to augment the output from Watson NLU. A configuration file is taken as input by the algorithm. This file needs to be configured by the domain expert.
The best of both worlds - training and rules based approach is used to extract knowledge out of documents.
In this Pattern we will demonstrate:
- Extracting the information from the documents- free-floating text and Table text.
- Cleaning the data pattern to extract entities from documents
- Use Watson Document Correlation pattern to extract relationships between entities
- Build a knowledge base(graph) from it.
What makes this Code Pattern valuable:
- The ability to process the tables in docx files along with free-floating text.
- And also the strategy on combining the results of the real-time analysis by Watson NLU and the results from the rules defined by a Subject matter expert or Domain expert.
This Code Pattern is intended to help Developers, Data Scientists to give structure to the unstructured data. This can be used to shape their analysis significantly and use the data for further processing to get better Insights.
Flow

- The unstructured text data from the docx files (html tables and free floating text) that need to be analyzed and correlated is extracted from the documents using python code.
- Use Extend Watson text Classification text is classified using Watson NLU and also tagged using the code pattern - Extend Watson text classification
- The text is correlated with other text using the code pattern - Correlate documents
- The results are filtered using python code.
- The knowledge graph is constructed.
Video
Included components
- IBM Watson Studio: Analyze data using RStudio, Jupyter, and Python in a configured, collaborative environment that includes IBM value-adds, such as managed Spark.
- Watson Natural Language Understanding: A IBM Cloud service that can analyze text to extract meta-data from content such as concepts, entities, keywords, categories, sentiment, emotion, relations, semantic roles, using natural language understanding.
- Jupyter Notebooks: An open-source web application that allows you to create and share documents that contain live code, equations, visualizations and explanatory text.
Steps
Follow these steps to setup and run this code pattern. The steps are described in detail below.
1. Create IBM Cloud services
Create the following IBM Cloud service and name it wdc-NLU-service:
2. Run using a Jupyter notebook in the IBM Watson Studio
2.1 Create a new Watson Studio project
-
Log into IBM's Watson Studio. Once in, you'll land on the dashboard.
-
Create a new project by clicking
+ New projectand choosingData Science:
-
Enter a name for the project name and click
Create. -
NOTE: By creating a project in Watson Studio a free tier
Object Storageservice andWatson Machine Learningservice will be created in your IBM Cloud account. Select theFreestorage type to avoid fees.
2.2 Create the notebook
-
From the new project
Overviewpanel, click+ Add to projecton the top right and choose theNotebookasset type.
-
Fill in the following information:
- Select the
From URLtab. [1] - Enter a
Namefor the notebook and optionally a description. [2] - Under
Notebook URLprovide the following url: https://raw.githubusercontent.com/IBM/build-knowledge-base-with-domain-specific-documents/master/notebooks/knowledge_graph.ipynb [3] - For
Runtimeselect thePython 3.5option. [4]

- Select the
-
Click the
Createbutton. -
TIP: Once successfully imported, the notebook should appear in the
Notebookssection of theAssetstab.
2.3 Run the notebook
-
Use the menu pull-down
Cell > Run Allto run the notebook, or run the cells one at a time top-down using the play button. -
As the cells run, watch the output for results or errors. A running cell will have a label like
In [*]. A completed cell will have a run sequence number instead of the asterisk.
2.4 Upload data
Upload the data and configuration to the notebook
-
This notebook uses the data in datqa. We need to load these assets to our project.
-
From the new project
Overviewpanel, click+ Add to projecton the top right and choose theDataasset type.
-
A panel on the right of the screen will appear to assit you in uploading data. Follow the numbered steps in the image below.
- Ensure you're on the
Loadtab. [1] - Click on the
browseoption. From your machine, browse to the location of thearchive.zip,config_relations.txt, andconfig_classification.txtfiles in this repository, and upload it. [not numbered] - Once uploaded, go to the
Filestab. [2] - Ensure the files appear. [3]

- Ensure you're on the
NOTE: It is possible to use your own data and configuration files. If you use a configuration file from your computer, make sure to conform to the JSON structure given in
data/config_classification.txt.
3. Analyze the results
As we step through the notebook we first the following:
- The configuration files (
config_classification.txtandconfig_relations.txt) are loaded. - The unstructured information is extracted using python package mammoth. Mammoth converts the
.docxfiles to.htmlfrom where text in the tables is also analysed along with free floating text. - The results from Watson Natural Language Understanding are analyzed and augmented using the configuration files.
- The entities are augmented using the
config_classification.txtand the relationships are augmented usingconfig_relations.txt. - The results are then filtered and formatted to pick up the relevant relations and discard the ones which are not relevant.
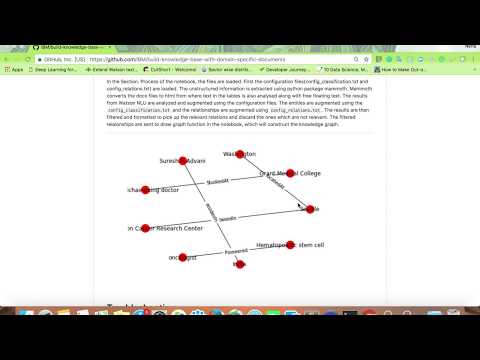
- The filtered relaionships are sent to draw graph function in the notebook, which will construct the knowledge graph.

Learn more
- Data Analytics Code Patterns: Enjoyed this Code Pattern? Check out our other Data Analytics Code Patterns
- AI and Data Code Pattern Playlist: Bookmark our playlist with all of our Code Pattern videos
- Watson Studio: Master the art of data science with IBM's Watson Studio
Troubleshooting
License
This code pattern is licensed under the Apache License, Version 2. Separate third-party code objects invoked within this code pattern are licensed by their respective providers pursuant to their own separate licenses. Contributions are subject to the Developer Certificate of Origin, Version 1.1 and the Apache License, Version 2.