
Get your code off the couch by stressing it on the bench
Contact me - Report Bug or Request Feature - Discussions - Documentation
The project in a nutshell
A micro/macro benchmark is an act of testing the performance of a framework, algorithm, routine, or application to make sure it has the performance you are expecting. python-benchmark-harness is therefore a library that aids in creating these micro or macro performance benchmarks for your code to find and visualize performance bottlenecks in your implementation in a flexible way.
With an emphasis on automation and visualizations, this library can integrate your benchmarks within a unit test framework allowing you to test your code early in the development life cycle and letting you render an assortment of visualizations to get the drop on a pesky performance problem in your code.
Installation
Installation is easy using pip or clone the source code straight from GitHub.
pip install python-benchmark-harnessGetting Started
After installing the package import the benchmarking object and define a benchmark name. Use the run() method to execute your benchmark on your creation and evaluate its performance. Below you can find a simple example that benchmarks your code non-intrusively:
from Benchmarking import benchmark as mb
from tests.stubs import FancyCode as Fc
# Give your benchmark a name
mb.test_case_name = "quick_start"
# Define you benchmark
mb.run(
method=Fc().fast_method, # <-- Make sure you don't call the method
arguments=[],
iteration=100,
pacing=0,
processes=2
)
# Get a letter rank how your changes compare to a previous benchmark.
letter_rank = mb.regression.letter_rank # > A+To start up a benchmarking session more flexibly you can also use the trace decorator called "collect_measurements". To do this you use "collect_measurements" to decorator your code that you want to benchmark:
from Benchmarking.profiling.intrusive import collect_measurements
from Benchmarking import benchmark as mb
# decorate your function to be able to collect measurements.
@collect_measurements(test_case_name="decorated_function", enabled=True)
def slow_method():
num = 6 ** 6 ** 6
return len(str(num))
# Run your method.
slow_method()
# Interact with the micro benchmarking object to extract information.
print(mb.test_id)
print(mb.test_case_name)
print(mb.regression.letter_rank)
Check out the documentation for more help to get started.
Visualize that pesky bottleneck
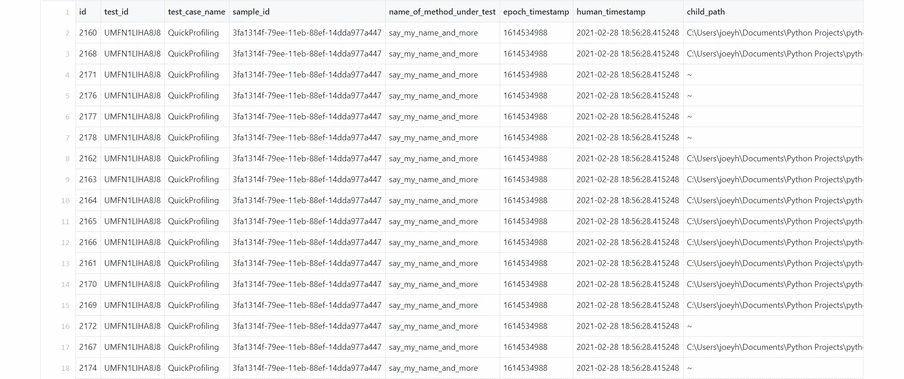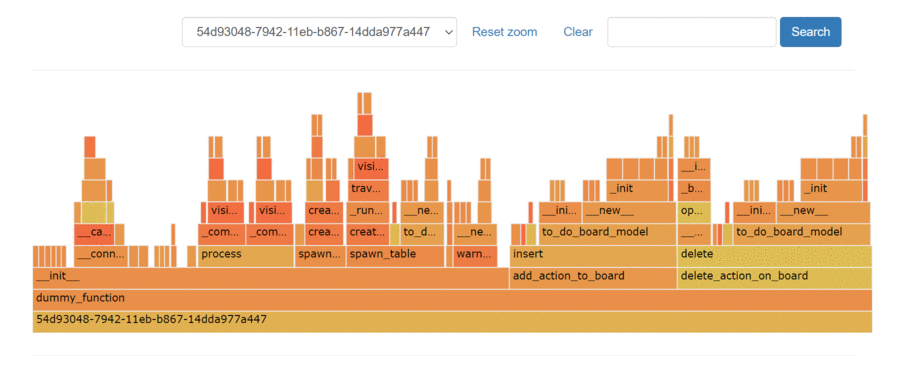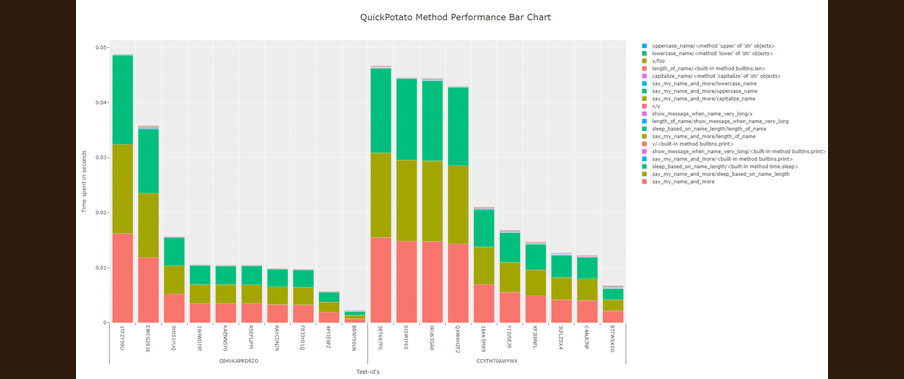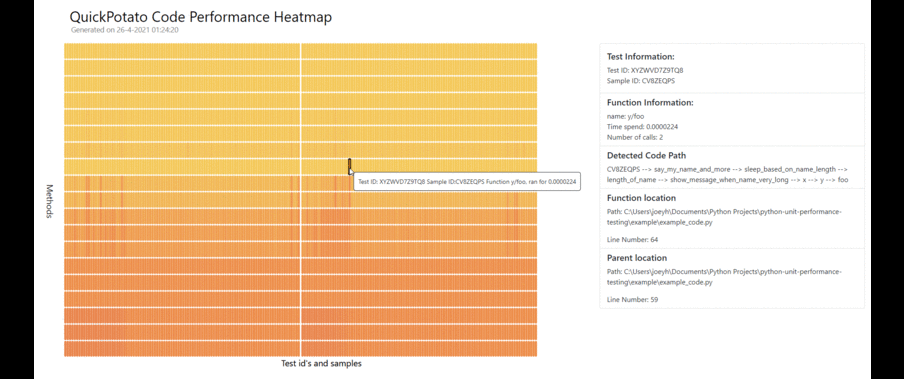
It is possible to visualize performance bottlenecks with variety of visualization the ones that are currently available within the package are the following:
- Flame Graphs
- Code Heat Maps
- Bar charts
- Scatter plots (Coming soon)
- Line Graphs (Coming soon)
If you want to visualize the data yourself or share the data in a common format, this is possible. You can export your benchmarks in the following formats through the benchmark API:
- CSV
- JSON (Coming soon)
Check out the docs for more information how to visualize or export your measurements.
Detecting regression between benchmarks
This project has the ability to detect an interesting performance regression using statistical methods allowing that a code change can be ranked with a score from 0 to 100, or a letter Japanese letter rank ranging from F to S.
These ranking metrics allow users of this framework to quickly asses how much the performance of their code has regressed after introducing a code change. In the below animation you can see the ranking metrics at work measuring the distance between two CDF and ranking it using a letter rank:
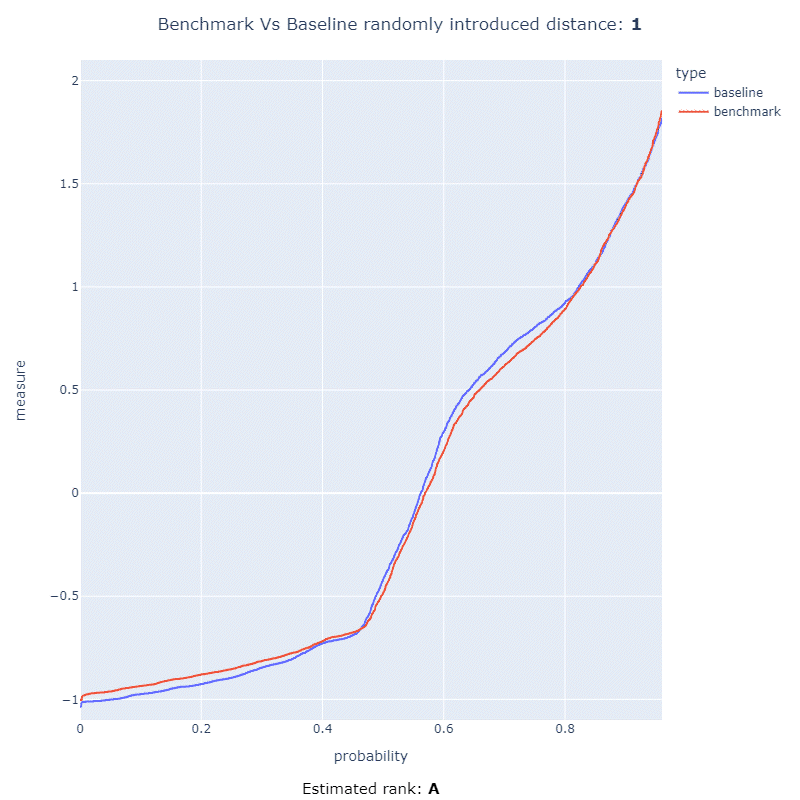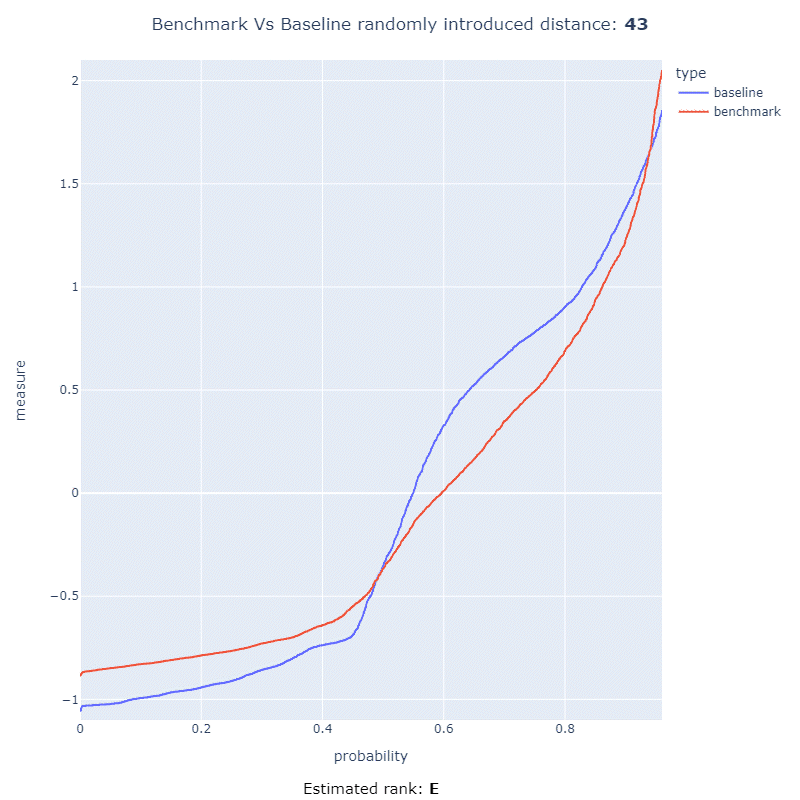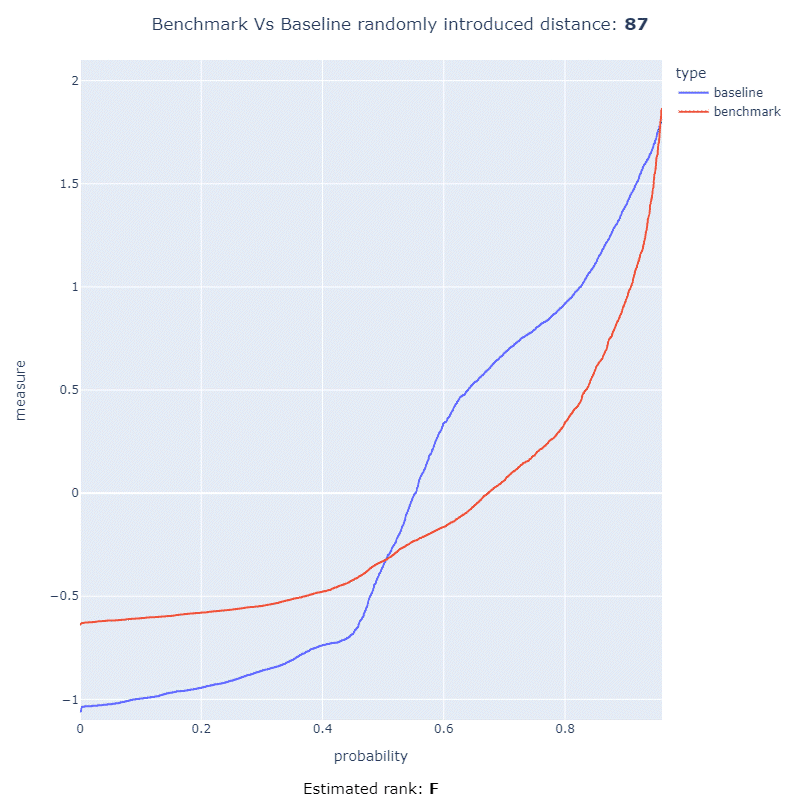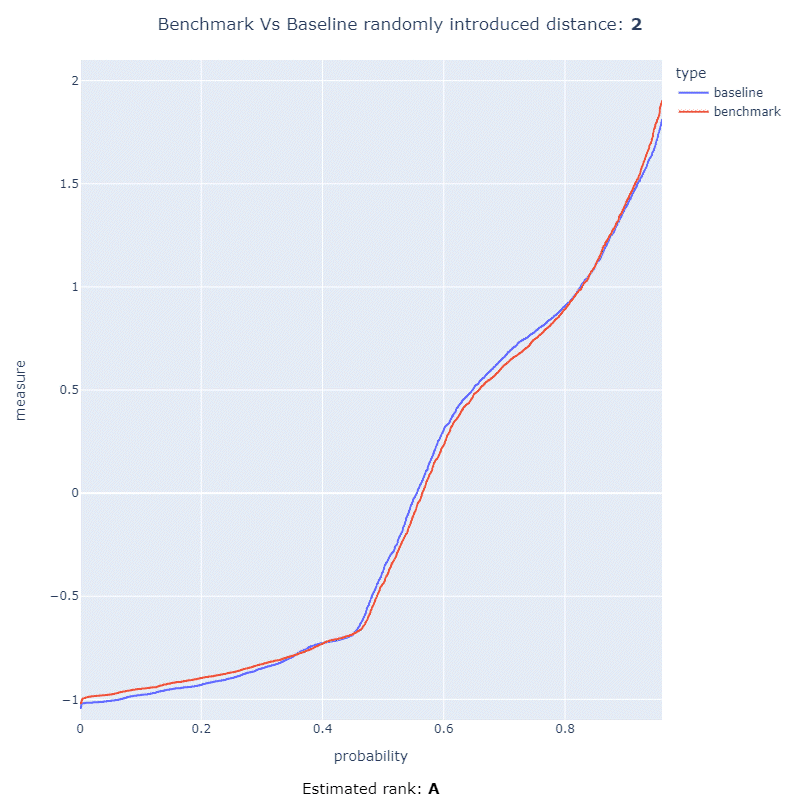
More information about the math behind this method and how this works can be found here or within the documentation.
Learn more about the project
Want to learn more about this project then I would recommend read the documentation, or to check my older conference recordings about this topic:
- 11/07/2020: Don’t lose your mind over slow code check your performance sanity.
- 08/10/2020: My recording about python-micro-benchmarks @NeotysPAC 2020.
- 15/12/2020: Interview about python-micro-benchmarks @TestGuild 2020.)
- 12/01/2020: An article I wrote for Neotys about my @NeotysPAC 2020 presentation.
This project was formerly known as QuickPotato and has been renamed to better reflect its purpose.