 KTurnura
commented
11 months ago
KTurnura
commented
11 months ago 遥感图像拼接背景
遥感图像拼接技术是将多幅航空或卫星图像拼接成一幅无缝图像的过程[2]。 通过遥感图像镶嵌技术,可以获得大区域的整体遥感图像,有利于大区域的观测和信息分析。
目的: 实现并行遥感图像拼接
传统拼接算法的内容:遥感图像镶嵌算法主要包括图像预处理、重叠区域估计、图像配准和图像融合四个处理步骤
重叠区域估计并行实现
针对传统镶嵌算法中串行进行重叠区域估计导致处理效率低的问题,对传统的图像重叠区域估计算法进行改进,能支持该算法在多节点的有效运行,以此实现集群多个节点的并行处理。
遥感图像拼接的自定义RDD
自定义RDD时,通过继承自Spark RDD的extends关键字覆盖compute和getPartitious方法。
- 在重写的compute方法中调用父RDD的iterator方法来获取父RDD对应分区中的数据。 iterator方法会返回一个迭代器对象,迭代器中存储的每个元素都是父RDD对应分区中的记录数据。 然后返回存储图像数据的迭代器,从而获得自定义RDD中从父RDD传输过来的图像数据,以供后续操作。
- 在重写 getPartitions 方法时,我们调用父 RDD 的 Partitions 方法并返回父 RDD 的分区。
- 同时,我们在自定义的RDD中添加了图像拼接方法,即重叠区域估计、图像配准和图像融合三个算子的设计。
Spark 隐私转换创建自定义RDD
在使用Spark集群进行遥感图像镶嵌处理时,我们是通过对RDD的操作来完成整个过程的,因此需要通过隐式转换来调用自定义RDD的方法。 隐式转换是指当对象调用一个不是该对象方法的方法时,Spark程序会在其作用范围内通过寻求隐式转换来调用该方法[22]。 Spark中我们通过implicit关键字进行隐式转换。 在执行隐式转换时,Spark程序发现对象类型不匹配时,会尝试匹配代码中隐式声明的对象。 隐式转换的一个重要作用是扩展RDD,其目的是实现功能增强。
本文在使用自定义RDD进行遥感图像拼接时,通过隐式转换的处理思想,调用自定义RDD的图像镶嵌方法来完成图像拼接工作。 其主要流程如下:
首先,我们使用SparkContext对象的textFile方法从HDFS中读取遥感影像数据并转换为初始RDD。 初始RDD通过隐式声明调用创建自定义RDD的方法,从而生成一个自定义RDD对象。 总之,通过隐式转换我们可以创建一个自定义的RDD对象,从而完成图像镶嵌的整个过程。 创建自定义 RDD 的详细信息如算法 1 所示。
在算法1中,TextFile函数需要两个参数,FilePath和Partition。 FilePath是遥感影像数据在HDFS中的存储路径,Partition是定义的分区数量, fileRDD是初始RDD。 我们将RDD中隐式修改的交换方法定义为自定义RDD。 该方法中,RDD为参数,返回值为自定义的RDD,即算法1中的imageRDD。

图像拼接中三个算子的设计
在自定义的RDD中,采用重叠区域估计、图像配准和图像融合三种方法来实现遥感图像的镶嵌。 因此,需要在自定义RDD中添加这三个算子,包括重叠区域估计算子、图像配准算子和图像融合算子。
三个算子的设计主要包括以下两个方面:首先,我们划分RDD的依赖关系,RDD的依赖关系是通过调用每个算子而产生的。 其次,我们设置三个运算符的类型。
此处有一个Spark的基础概念,DAG 中Stage的切分通过RDD转换中的宽依赖和窄依赖来实现的。当我们划分RDD之间的依赖关系时,窄依赖关系的RDD属于一个阶段,而宽依赖关系的RDD属于不同阶段。
本文在图像重叠区域估计和图像配准中,每个分区中的遥感图像数量没有变化。 也就是说,即使RDD数据大小发生变化,子RDD中依赖于父RDD中分区的分区数量也不会改变。 所以它们之间是窄依赖关系。
然而,在图像融合中,多幅图像将被合并为一幅图像。 结果是子RDD中依赖于父RDD的Partition数量可能会随着RDD数据大小的变化而变化。 所以他们之间的关系是宽依赖关系。 根据上述划分策略,我们划分如图3所示的RDD依赖关系,这些依赖关系是通过调用图像重叠区域估计、图像配准和图像融合这三个算子生成的。
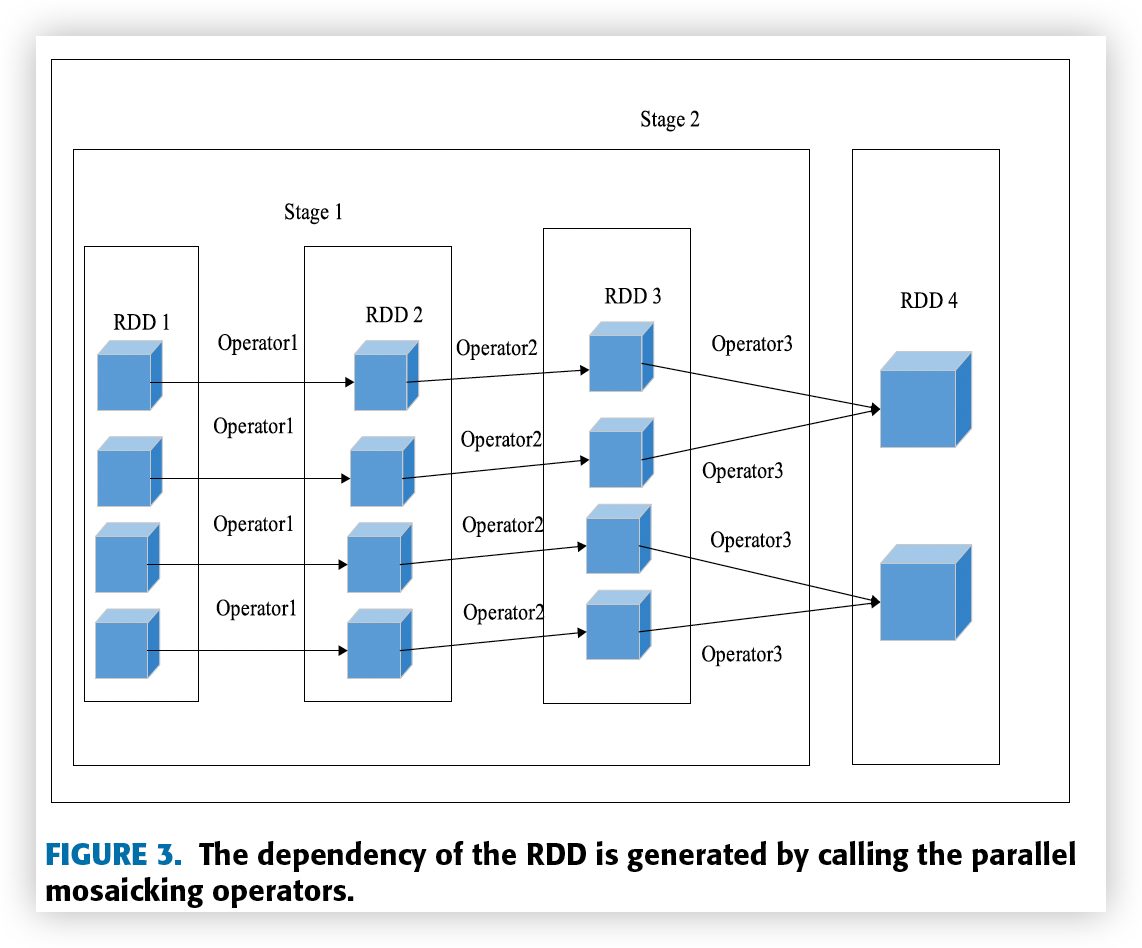
图3中,RDD1是通过隐式转换得到的自定义RDD(面向遥感图数据)。 RDD2-RDD4是依次调用重叠区域估计算子(Operator1)、图像配准算子(Operator2)和图像融合算子(Operator3)得到的新RDD。
从图3可以看出,在RDD 1、RDD 2、RDD 3的转换过程中,每个父RDD的Partition都被子RDD的一个Partition使用,因此它们被划分为一个Stage(Stage1) 。 由于RDD3到RDD4的转换过程中涉及到Partition的合并操作,因此RDD 3和RDD 4被分为不同的阶段(Stage 1和Stage 2)。 通过RDD依赖关系的划分,我们将图像并行镶嵌转化为基于Stages的DAG,这样DAGScheduler就可以根据RDD和Stages之间的关系来完成任务处理
提出一种基于Apache Spark的并行镶嵌算法。 然后,我们自定义遥感图像处理的弹性分布式数据集(RDD),并使用图像镶嵌的三个关键步骤,包括重叠区域估计、图像配准和图像融合,作为变换类型 自定义RDD的运算符