论文笔记
分享一些自己在看的分布式论文,领域包含,分布式系统构建,联邦学习,去中心化服务等,包括一些经典分布式论文和理论,包括大家耳熟能详的Raft,Zookeeper,Bigtable,ACID性质,CAP理论等,也包括一些会议前沿的论文,VLDB、ICDE、OSDI、SIGMOD等
看到有前辈在github上记录自己读论文的一些记录,以此也想记录并分享一些自己对论文的一些看法。从九月份刚入学开始,读了一部分博客推荐的经典论文,后面开始跟MIT 6.824的课程,MIT课程的代码可能会在repository中更新并解读,关于论文的一些想法会在issue中记录,有对论文有见解的可以在issue中评论,也可以分享一些您认为某篇论文的扩展和值得读的论文,这个分享的过程真的值得人期待
后续一些关键论文的解读可能会放在自己的 博客 中,如果准备对某篇博客进行解读会在issue中指出
关于readme,打算周期性展示一个月内读过的论文,然后每月更新之后归档上一个月的论文
2023-9/10月目录
PS:早期高估了自己的英语能力,有些关键点使用英文写在笔记上的,有些论文也没有总结,第一次做论文分享,内容过于二流请多多包涵,后续阅读文章会为方便文章分享和提高分享质量进行改进
Table of Contents
- 1. architecutre
- 2. Database
- 3. File System
- 4. Data Storage Layer
- 5. CAP theorem && ACID
- 5.1 1978_Time, Clocks, and the Ordering of Events in a Distributed System
- 5.2 1982_Byzantine Generals Problem
- 5.3 2005_Brewer's Conjecture and the Feasibility of Consistent, Available, Partition-Tolerant Web Services
- 5.4 2012_ CAP Twelve years later how the rules have changed
- 5.5 2008_An ACID Alternative : BASE
- 5.6 2008_Zookeeper : A simple totally ordered broadcast protocol
- 5.7 2010_The Design of a Practical System for Fault-Tolerant Virtual Machines
- 5.8 2014_Raft: In Search of Undersatandable consensus Algorithm
- 6. Batch processing
- 7. Blog
- 8. 个人论文
1. architecutre
此处的architecture(架构)指的是数据系统集成方式。当数据量、访问量逐渐增大时,企业要考虑读写分离技术,分库分表等。此时为了同时处理实时到来的数据和积存的数据,需要一种混合分析的方法,来充分利用数据价值,既能保证处理数据的低延迟,又保障获取数据的准确性。
1.1 Lambda
Lambda架构,将数据处理分为(batch layer)批处理层,(speed layer)实时处理层和一个服务层(serving layer)。批处理层可以处理每天的积存数据,更新关系数据库中的现有视图,通常批处理层,多使用HDFS、Hive、Impala。实时处理层负责填补批处理层在提供基于最新数据的视图方面的滞后所造成的"差距",多使用Storm、Spark、HBase等。服务层用于响应用户的查询请求,合并Batch View和Realtime View中的结果数据集到最终的数据集。
1.2 Kappa
http://radar.oreilly.com/2014/07/questioning-the-lambda-architecture.html
这篇算是最早挑战Lambda架构的文章
指出了Lambda架构的缺点
- 分别维护批处理层和实时处理层的不同组件太过困难
- 需要保证实时和批处理计算产生的结果需要保持口径一致
- 随着数据量的增大, 批处理无法在计算窗口内完成计算
Kappa 架构去掉了批处理层,只留下了流处理层,使用Kafka这种消息队列的数据保留功能,来实现上游重放能力
当流任务发生代码变动时,或者需要回溯计算时,原先的Job N保持不动(继续进行流式计算),先新启动一个作业Job N+1,从消息队列中获取历史数据,进行计算,计算结果存储到新的数据表中。
当计算进度赶上之前的Job N(启动Job N+1的时刻),Job N+1替换Job N,成为最新的流处理任务。然后程序直接读取新的数据表,停止历史作业Job N,并删除旧的数据表。
技术选型: 流处理: Flink
数据服务: HBase,Druid,ClickHouse
1.3 2014_summingbird ,VLDB, twitter
https://dl.acm.org/doi/10.14778/2733004.2733016 :不推荐读,有些过时
改善了Lambda体系的复杂性,提供了针对批处理和流处理系统的一个统一封装抽象,但是这种抽象限制了能支持的计算的种类,并且仍然需要维护两套系统,运维复杂性仍然存在。
Summingbird程序是使用数据流抽象(例如源、接收器和存储)编写的,并且可以在不同的执行平台上运行:用于批处理的 Hadoop(通过 Scalding/Cascading)和用于在线处理的 Storm。 不同的执行模式需要不同的数据流抽象绑定(例如,HDFS 文件或源消息队列),但不需要对程序逻辑进行任何更改。 此外,Summingbird 可以在混合处理模式下运行,透明地集成批量结果和在线结果,以在长时间跨度内有效生成最新的聚合结果。
2. Database
2.1 2010_Scalable SQL and Nosql data stores
https://dl.acm.org/doi/10.1145/1978915.1978919
简单介绍NOSQL,旨在在许多服务器上扩展简单的 OLTP 样式应用程序负载。
于传统DBMS和Datawarehouse不同,我们对比新系统与传统数据存储的数据模型、一致性机制、存储机制、持久性保证、可用性、查询支持等维度。
NoSQL通常会牺牲一些维度,例如 数据库范围的事务一致性,以实现其他目标,例如更好的可用性和可扩展性。
介绍了不同对象存储中的NoSQL数据库, 以及这些不同对象存储的使用案例。对比了NoSQL和SQL,进行了基准测试以及对未来进行了一定程度的展望
- K-V
- Redis
- etc.
- Document stores
- MongoDB
- etc.
- Extensible record stores
- HBase
- Cassandra
- etc.
- Scalable Relational Systems
- Mysql Cluster
- Other systems
- etc.
3. File System
3.1 2003_GFS
https://research.google/pubs/pub51/
早期谷歌的三驾马车之一,放宽了对分布式系统的一致性,追求可扩展性和可用性。
将文件切分成64MB,只支持顺序写入,不支持修改,因为应用程序大多按顺序读取和写入大文件。
除此之外,对数据块进行管理,例如:块租用管理,孤立块的垃圾收集和块服务器之间的迁移
client 和 master交互以元数据操作来进行,客户端和chunkserver都不缓存文件数据,没有这个属性可以通过消除缓存一致性问题来简化客户端和整个系统
单Master结构
三种Metadata:文件和块命名空间、从文件到块儿的映射,还有每个块分片的位置
主人向其中一个副本授予块租约,我们称之为主副本。
使用标准copy-on-write 技术来实现快照当收到快照请求,会第一时间撤销快照所在文件的所有租契,确保后续所有写操作都需要和master交互,这样可以使master首先创建文件的新复制文件
垃圾回收机制
Fault-Tolerance: Fast Recovery, Chunk Replication,Master Replication等
4. Data Storage Layer
4.1 2006_BigTable
https://static.googleusercontent.com/media/research.google.com/zh-CN//archive/bigtable-osdi06.pdf
早期谷歌的三驾马车之一。
记录非结构化数据,HBase前身,使用K-V键值对来存储数据
结构:Rows、ColumnFamily、Column
结构展示:
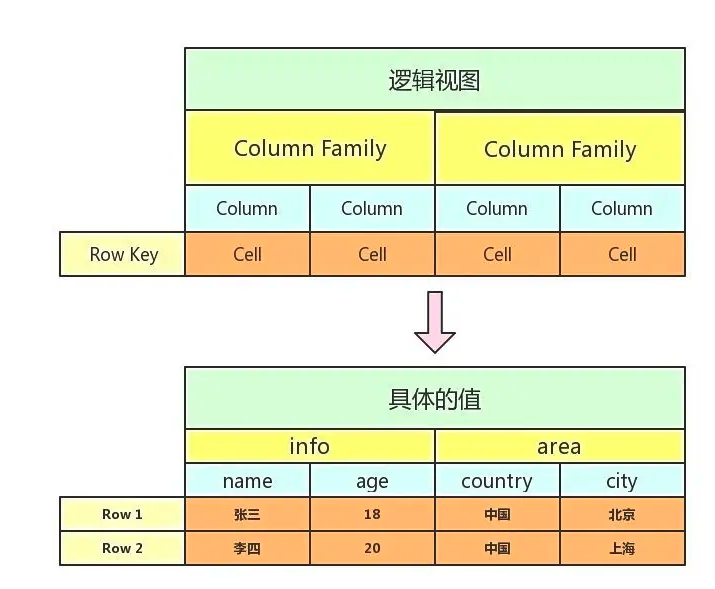
使用时间戳来方便BigTable自动垃圾回收某些列族版本
Bigtable可以与GFS来进行交互,类似于Hbase可以操作HDFS上的数据
BigTable使用chubby来完成多种任务:
- 确保最多只有一个Master活跃
- 存储BigTable数据的引导位置
- 发现tablet server 并最终确定tablet server 死亡
- 存储Bigtable Schema信息(每个表的列族信息)
- 存储访问控制列表
BigTable包含以下三个组件:
-
a library that is linked into every client
-
one master server,
-
and many tablet servers(类似于没有任何管理功能的服务器)
Master 负责分配tablets 给tablet 服务器。检测tablet 服务器的添加和到期信息 均衡tablet-server的负载,在GFS上进行垃圾回收,处理schema结构改变:表创建和列组创建
Tablet 是Bigtable 数据分布和负载均衡的基本单位,不同的子表可以有不同的大小。 为了限制Tablet 的移动成本与恢复成本,每个子表默认的最大尺寸为200 MB。 Tablet 是一个连续的Row Key 区间,当Tablet 的数据量增长到一定大小后可以自动分裂为两个Table
使用三层等级制度,类似于B+树,来存储tablet 位置信息
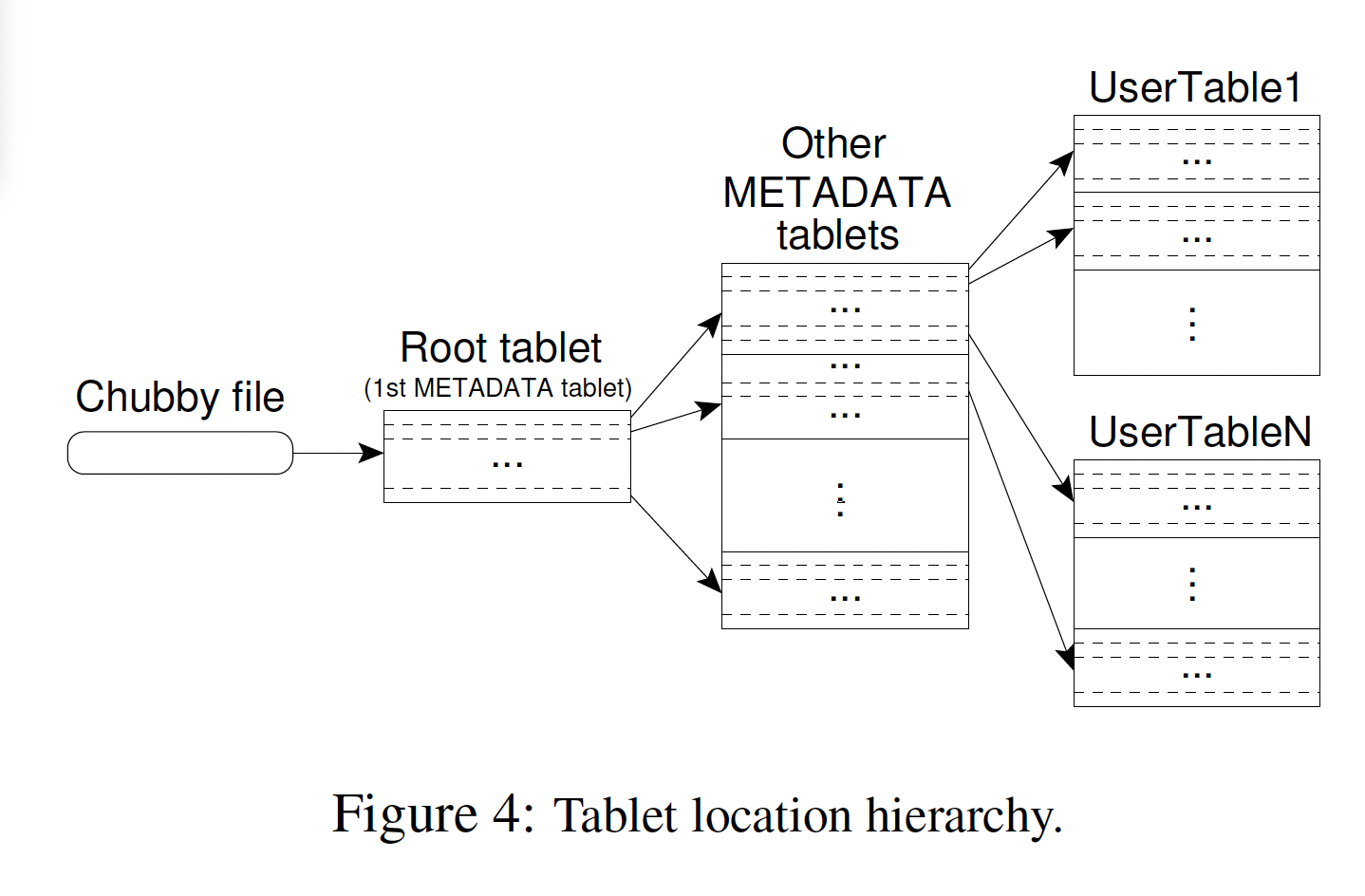
每个tablet 一次分配给一台tablet 服务器,使用chubby跟踪Tablet 服务器
使用 Locality groups、 Compression、Caching for read performance、 Bloom filters、 Commit-log implement、Speeding up tablet recovery and Exploiting immutablity来进行优化
5. CAP theorem && ACID
5.1 1978_Time, Clocks, and the Ordering of Events in a Distributed System
本文定义了Happened Before 关系, 由于物理时钟有误差,所以本文考虑逻辑时钟,最终目的就是为了的到一种事件全局排序的机制。而由于事件排序是偏序的。所以定义了“Happened Before关系”。 逻辑时钟给事件打上了时间戳,可以通过比较事件的时间戳数值来判断事件的发生次序(Happened Before 关系)。逻辑时钟给事件打时间戳的时候,需要满足一定条件,该文定义了一个时钟条件。 该文详述的证明了该条件,且该条件也需要满足其他条件[[6_总结#5]]
但时钟条件具有单向推导逻辑的限制,我们不能根据两个事件对应的时间戳在数值上的大小(因为"Happened Before 具有偏序性")来推断出他们之间是否存在"Happened Before"关系。
此时给不同事件指定时间戳,虽然没有意义,但可以按照该时间戳从小到大把所有事件都排成一个序列,那么就得到了分布式系统中所有事件的全局排序。此时所有事件的"Happened before 关系就都被保持住了".即 这种排序和"Happened Before "顺序保持一致
而更近一步,事件的全局排序结合状态机复制(State Machine Replication)的思想,几乎可以为任何分布式系统的设计提供思路
然而,在分布式领域,逻辑时钟仍然存在一些异常行为,有时候行为是发生在系统外部,系统内部并不知晓,此时,我们又需要真实物理事件作为基准。但由于不同机器的物理时钟之间存在偏差,我们需要使物理时钟满足Strong Cock Condition 来保证系统总能对正确的顺序进程打上合理的时间戳。 而时空本身就是一种偏序,在相对论中,事件的排序是根据可能发送的消息来定义的。然而,我们这里采取了更务实的做法,仅仅考虑那些实际上已经发送过的消息
此时我们需要运行一个时钟同步算法,来保证即使两个进程之间存在偏序关系,仍能为不同进程的不同事件打上合理的时间戳。 在论文中,考虑物理时钟的两种误差,不断对各进程本地的物理时钟进行微调,将误差控制在能够满足Strong Clock Conditionde 的范围内 a) :进程内,保证时钟不回退 b): 进程外,在不同进程的物理时钟之间交换信息,借助这些信息同步时钟读书,将不同进程的物理时钟误差控制在一定范围内
它还划定了系统的能力边界。它告诉我们,什么样的问题可以在系统内部,遵循一个纯异步的模型(asynchronous model)框架就能解决(比如非拜占庭模型下的共识问题);而什么样的问题,必须求诸系统的“外部”(也就是物理世界)才能得到解决(比如拜占庭模型下的共识问题、线性一致性问题等)。所有这些,都深深地影响了人们对于分布式系统的思考方式。s in a Distributed System
5.2 1982_Byzantine Generals Problem
本文介绍了拜占庭问题 在最开始全通量图的情况下,给出了口头消息和签字消息的 解拜占庭问题的基本条件。
- 口头消息
- 少于3m+1个将军,无法处理m个叛徒的问题
后序给出了在不完全连接图的时候在口头消息和签字消息的解法:
然后给出了现实中实现Signature Algorithm 算法的例子
5.3 2005_Brewer's Conjecture and the Feasibility of Consistent, Available, Partition-Tolerant Web Services
证明了CAP三种属性在分布式系统中不可能同时实现(反证法
- C : Consistent
- A : Available
- P : Partition-Tolerant
给出了现实中三种属性两两结合的实例
尝试规避定理不可能结果的最明显方法是认识到在现实世界中,大多数网络并不是纯粹异步的。如果允许网络中的每个节点都有一个时钟,就有可能构建更强大的服务。但即使是部分同步网络中,也不存在同时满足CAP属性的机器。有一些部分同步算法,当执行中的所有消息都被传递时(即没有分区),它们将返回原子数据,并且仅在消息丢失时返回不一致(特别是陈旧)的数据。
这种算法的一个例子是第 3.2.1 节中描述的集中式协议,该协议被修改为超时丢失消息。 根据读(或写)请求,一条消息被发送到中央节点。
使用弱一致性可以提供很好的服务效果,但对弱一致性也提出了限制
这种保证允许在消息丢失时保留一些过时的数据,但提供了分区修复后恢复一致性所需时间的时间限制。并分析了在四种读写顺序情况下这种弱一致性导致的偏序符合标准的可能
5.4 2012_ CAP Twelve years later how the rules have changed
(本篇论文更倾向于推荐弱一致性,因为是BASE理论论文的作者)
通过显式处理分区,设计人员可以优化一致性和可用性,从而实现所有三者的某种权衡。 CAP 的这种表达方式达到了它的目的,那就是让设计者们敞开心扉,接受更广泛的系统和权衡。 在过去十年中,以及关于一致性和可用性的相对优点的很多争论,但他过度放大了两者之间的沟壑
区分关系型数据库中的ACID性质和本处的CAP理论,本文作者还提出了下一小节的BASE理论
NoSQL将关注点放在可用性上,关系型数据库更关注一致性
区分ACID、BASE和CAP
具有迷惑性的点
- 因为分区是少有的,当不分区时这并不能成为舍弃C或A性质的原因
- 其次,C 和 A 之间的选择可以在同一系统中以非常细的粒度多次发生;子系统不仅可以做出不同的选择,而且选择可以根据操作甚至所涉及的特定数据或用户而改变。
- 最后,所有三个属性都比二进制更加连续。可用性显然是从 0% 到 100% 连续的,但一致性也有很多级别,甚至分区也有细微差别,包括系统内部对于分区是否存在存在分歧
因为分区很少见,所以 CAP 在大多数情况下应该允许完美的 C 和 A,但是当存在或感知到分区时,检测分区并明确说明它们的策略是适当的。 该策略应该包含三个步骤:检测分区,进入可以限制某些操作的显式分区模式,以及启动恢复过程以恢复一致性并补偿分区期间发生的错误。
分析了CAP理论中忽略的“延迟”,从操作上来说,CAP 的本质发生在超时期间,在此期间程序必须做出基本决策 - 分区决策:
- 取消操作,然后降低可用性
- 处理程序,也因此会处罚不一致性
重点可以看看CAP Latency Connection,有些实际生产中相关的内容
理解分区管理
对于设计人员来说,具有挑战性的情况是减轻分区对一致性和可用性的影响。 关键思想是非常明确地管理分区,不仅包括检测,还包括特定的恢复过程以及针对分区期间可能违反的所有不变量的计划。 这种管理方法分为三个步骤:
- 检测分区的开始
- 进入显示分区模式,这可能会限制某些操作
- 当通信恢复时,启动分区恢复
最后一步的目的是恢复一致性并补偿系统分区时程序所犯的错误。
考虑了在分区过程中需要限制的操作:取决于系统必须维持的不变量
在分区结束后,需要考虑在恢复过程中遇到的难题
-
双方的状态必须一致
-
必须对分区模式期间所犯的错误进行补偿
当分区存在时,系统设计者不应盲目牺牲一致性或可用性。 使用所提出的方法,他们可以通过在分区期间仔细管理不变量来优化这两个属性。 作为较新的技术,例如版本向量和 CRDT,进入简化其使用的框架,这种优化应该变得更加广泛。 然而,与 ACID 事务不同,这种方法需要相对于过去的策略进行更周到的部署,并且最佳解决方案将在很大程度上取决于有关服务的不变量和操作的详细信息。
5.5 2008_An ACID Alternative : BASE
如果ACID提供了分区数据库的一致性选择,那你可以选择什么样的替代品呢? 一个答案就是BASE (basically available, soft state, eventually consistent).
BASE 是ACID的反面, ACID是悲观并且强一致性,对于每一个操作。 BASE 是乐观,接收数据库一致性是一个可以变动的状态。 虽然听起来不可能,在现实中,它更容易管理去实现扩展性,这个是ACID不能实现的。
BASE的可用性可以通过以下方式获得,支持部分出错,但是整体还是工作的。 即使出错,也不影响该系统的整体可用性
为了实现分布式系统的松一致性,可以将数据库中的表进行解耦,类似于先对一个表进行更新,然后在更新另一个表,相对于一个表更容易保持一致性
假设我们解耦了更新user 和 transaction 表。这两个表的一致性不保证。如果在第一个事务和第二个事务之间发生了错误,那么这两个表就永远不能一致了,如果只要求一个大概统计,那么还是可以接受的。
如果估计不能被接受,则需要引入新的组件来解耦两个表的更新
引入一个持久化的消息队列来解决这个问题。
在交易插入时候,用入队列的方式持久化消息,他和这消息在user被需要时后要进行更新以便达到平衡。
一个独立的消息处理component将从消息队列中,取出每一个消息,并将这些信息写入user table。看来这个例子解决了所有问题,但是有个问题。如果消息里还有user host的联系,那么还是有2PC情况。
消息处理进程 对于2PC问题的一个解决方案, 啥都不做。解耦这个更新到一个分离的后台component, 保持顾客可用行。消息处理的稍低的可用性可以被接收。
虽然有幂等性,但并不是所有的事务都满足幂等性,
本文给出了一个例子,该例子依赖于在队列里找一个消息处理,处理之后再移除。这可以在两个独立的交易,一个是在消息队列,另外一个在user数据库。queue操作只有当数据库操作成功的时候才commit。这个算法支持部分失败,可以保证交易而没有使用2PC
有一个简单的技术可以保证更新的幂等性,如果只考虑顺序。假定你想查看user最后一天的销售和采购,你可以依赖一个一样的schema更新用这个日期用message;还有一个办法是使用时间,也可以使用自增性transaction ID
消息的有序性也相当有必要, 但如果实现消息系统能够确保消息按照接收顺序传递的成本还很高,而且会导致一些自以为解决了的错误。 我们可以放宽消息排序的要求并最终仍然提供一致的数据库视图。
本文一直所讲的,就是使用一致性来换取可用性,在另一方面,即使用软状态和最终一致性,就可以实现一个比较好的分布式系统。 如果确实需要知道状态是否达到了一只,可以使用EDA(事件驱动架构),获得使状态变得一致生成的事件。
传统服务需要进行横向扩展时,传统事务模型就会出现问题, 解耦操作并依次执行它们可以提高可用性和规模以一致性为代价。 BASE 提供了一个思考这种解耦的模型。
5.6 2008_Zookeeper : A simple totally ordered broadcast protocol
https://dl.acm.org/doi/abs/10.1145/1529974.1529978
Zab协议是为分布式协调服务Zookeeper专门设计的一种支持崩溃恢复的原子广播协议,是Zookeeper保证数据一致性的核心算法。
在Zookeeper中主要依赖Zab协议来实现数据一致性,基于该协议,zk实现了一种主备模型(即Leader和Follower模型)的系统架构来保证集群中各个副本之间数据的一致性。 这里的主备系统架构模型,就是指只有一台客户端(Leader)负责处理外部的写事务请求,然后Leader客户端将数据同步到其他Follower节点。
Zookeeper 客户端会随机的链接到 zookeeper 集群中的一个节点,如果是读请求,就直接从当前节点中读取数据;
如果是写请求,那么节点就会向 Leader 提交事务,Leader 接收到事务提交,会广播该事务,只要超过半数节点写入成功,该事务就会被提交。
基于ZAB协议,Zookeeper实现一种主备模式的系统架构来保持集群中主备副本之间数据的一致性。
ZAB协议包括两种基本模式:消息广播(Message Broadcasting)和崩溃恢复(Leader Activation)。 Zookeeper 消息广播顺序
- 读请求直接发生在Follower上,如果发生写请求,则Follower 将请求转发给Leader
- 当Follower 接收到事务请求时,会将该请求转发给Leader,让Leader 来进行处理Follower 在接收到事务后,会向所有Follower节点发送Proposal 提议,并等待各个节点的Ack 反馈,
- 在广播事务之前Leader服务器会先给这个事务分配一个全局单调递增的唯一ID,也就是事务ID(zxid),每一个事务必须按照zxid的先后顺序进行处理。
- 各个Follower 对Leader 节点进行Ack反馈,Leader 对接受到的Ack进行统计,如果超过半数的Follower 进行了Ack,则执行该事务,否则向客户端进行事务请求失败的Response
- 如果Leader节点接收到了超过半数的Ack响应,此时Leader会向所有的Follower发出事务Commit的指令,同时自己也执行一次Commit,并向客户端进行事务请求成功的Response。
Zookeeper的消息广播过程类似 2PC(Two Phase Commit),ZAB 仅需要超过一半以上的Follower返回 Ack 信息就可以执行提交,大大减小了同步阻塞,提高了可用性。
除消息广播之外,Zookeeper还有崩溃恢复的功能,在上文[[11_Paper_Ref]]中做了更详细的介绍 Leader选举场景
- Zookeeper启动
- Leader崩溃
重点介绍zxid : 由于只有Leader才能进行Proposal,所以这个zxid很容易做到全局唯一且自增。因为Follower没有生成zxid的权限。zxid越大,表示当前节点上提交成功了最新的事务,
Zab 协议通过 epoch 编号来区分 Leader 变化周期,能够有效避免不同的 Leader 错误的使用了相同的 zxid 编号提出了不一样的 Proposal 的异常情况
5.7 2010_The Design of a Practical System for Fault-Tolerant Virtual Machines
https://dl.acm.org/doi/10.1145/1899928.1899932
更多讨论见issue
基于通过另一台服务器上的备份虚拟机复制主虚拟机的执行的方法,实现了一个企业级的容错系统
区别于常见的容错系统: Primary / backup approach
只有Primary VM 宣传他在网络中位置,所有网络输入都面向PVM,类似的,所有其他输入也都面向PVM
所有PVM接收到的输入,都通过网络连接:logging channel 传递给backup VMs
backup VM的输出都顺便经过 hypervisor
primary 和 backup VMs都遵循着一个特殊的协议,包括备份虚拟机的明确确认,来保证backup接管时没有数据损失
通过监控两服务器心跳以及监控 logging channel 来判断primary 和 backup是否故障
此外,我们还需要确保backup和primary 只有一个接管了执行操作,即使在脑裂的情况下
服务器副本执行可以被建模为确定状态机的副本
使用共享存储来解决脑裂情景,且这种方法将不会引入任何额外的可用性
- 注意启动和重启Vitual Machine 的机制,
- 检测Primary 和 backup之间Logging Channel的流量
5.8 2014_Raft: In Search of Undersatandable consensus Algorithm
https://dl.acm.org/doi/10.5555/2643634.2643666
Raft 是针对复制日志的一致性算法 为了提高易理解性,Raft 分离了共识的关键要素,例如领导者选举、日志复制和安全性,并且它强制执行更强的一致性以减少必须考虑的状态数量。 Raft同样包含一个新的改变集群成员的机制,同时使用重叠多数来保证安全
6. Batch processing
6.1 2008_Mapreduce
https://dl.acm.org/doi/abs/10.1145/1327452.1327492
7. Blog
1. you can't sacrifice partition tolerance
https://codahale.com/you-cant-sacrifice-partition-tolerance/
// TODO2. Challenges of Data Stream Processing : big data Streams
https://nexocode.com/blog/posts/data-stream-processing-challenges/
// TODO3. 条分缕析分布式:到底什么是一致性?
http://zhangtielei.com/posts/blog-time-clock-ordering.html
区分Consensus 和consistency , Consensus 共识算法: Paxos Consistency 一致性:线性一致性 所谓的强一致性只与CAP定理有关系,但CAP定理现在并没有办法涵盖分布式领域的主要问题
Consistency : 它指的是任何一个数据库事务的执行,都应该让整个数据库保持在「一致」的状态。 大多数用于数据库的ACID 特性 比如使用: 2PC和3PC属于 原子提交协议两种不同的具体实现 而原子提交是ACID 中Atomic(原子性的一部分
而新论文将原子提交问题抽象为了新的一致性问题: 称为Uniform consensus: 要求所有节点(包括故障节点都要达成共识)
而通常的consensus 问题通常只关注没有发生故障饿节点达成共识 例如: Paxos 算法和解决拜占庭将军问题的算法
CAP理论: C(Consistency) A(Available :可用性) P(Partition-tolerance)只能同时满足三个
但在CAP理论中,C指的线性一致性:系统表现的就像只有一个副本一样
传统对CAP理论的一致性介绍都颇为片面
- 在分布式系统完成某写操作后的任何读操作,都应该获取到该写操作写入的那个最新的值。 只是线性一致性的特例
- 保持所有节点在同一个时刻具有相同的、逻辑一致的数据“ 。 以偏概全
分布式事务处理的并不是同一个数据对象的多个副本的问题,而指的是将针对多个数据对象的各种操作组合起来,提供ACID的特性。将分布式事务看成是强一致性的保证,猜测可能实际上指的就是ACID的原子性。总之,「强一致性」这个词很容易产生误解,所以建议谨慎使用。
4. 条分缕析_强弱一致性
http://zhangtielei.com/posts/blog-distributed-strong-weak-consistency.html
跟大家继续讨论顺序一致性、线性一致性、最终一致性等几个概念。
为了避免产生歧义,我们先明确一下这几个概念的英文表达:
- 顺序一致性的英文是:sequential consistency。
- 线性一致性的英文是:linearizability。实际上,它就是CAP定理中的C,我们在上一篇文章中已经提到过。
- 最终一致性的英文是:eventual consistency。
在进行详细的技术性讨论之前,我们先把本文要讨论的几个重点问题和结论列出如下:
- 线性一致性和顺序一致性,属于分布式系统的一致性模型 (consistency model)。这代表了分布式系统的一个非常非常重要的方面。
- 通常人们把线性一致性称为「强一致性」,把最终一致性称为「弱一致性」,但线性一致性和最终一致性其实存在本质的区别。严格来说,它们并不是一个范畴的概念。
- 一致性模型之间的「强弱」比较,是一个相对的概念。比如,线性一致性是比顺序一致性更强的一致性模型。当然,除了线性一致性和顺序一致性,也存在其它一些一致性模型(其中很多都比顺序一致性要弱)。
- 满足线性一致性的系统,也必定满足顺序一致性,但反过来不一定。这是由一致性模型之间的强弱关系决定的。
线性一致性> 顺序一致性> 最终一致性
5. 漫谈分布式系统、拜占庭将军问题与区块链
http://zhangtielei.com/posts/blog-consensus-byzantine-and-blockchain.html
本文具体分析了拜占庭问题, 介绍了拜占庭问题需要满足的两个条件以及拜占庭问题解决的基本要求(至少要有多少个将军是忠诚的)。
在拜占庭的容错性问题中,以例子辨别拜占庭问题 这种错误,在不同的观察者看来,会有前后不一致的表现
拜占庭问题是一种同步模型,而Paxos 是一种异步模型
和非拜占庭问题 拜占庭问题解法 : 区块链技术,提高"叛变"成本 非拜占庭问题: Paxos,Raft
区块链技术:但是,从技术的角度来说,它首先是个解决了拜占庭将军问题的分布式网络,在完全开放的环境中,实现了数据的一致性和安全性。而其它的属性,都附着于这一技术本质之上。
8. 个人论文
1. 总结CAP理论
https://github.com/KTurnura/KTurnura.github.io/blob/master/pdf/CAP_theorem.pdf