 KTurnura
commented
11 months ago
KTurnura
commented
11 months ago 流程
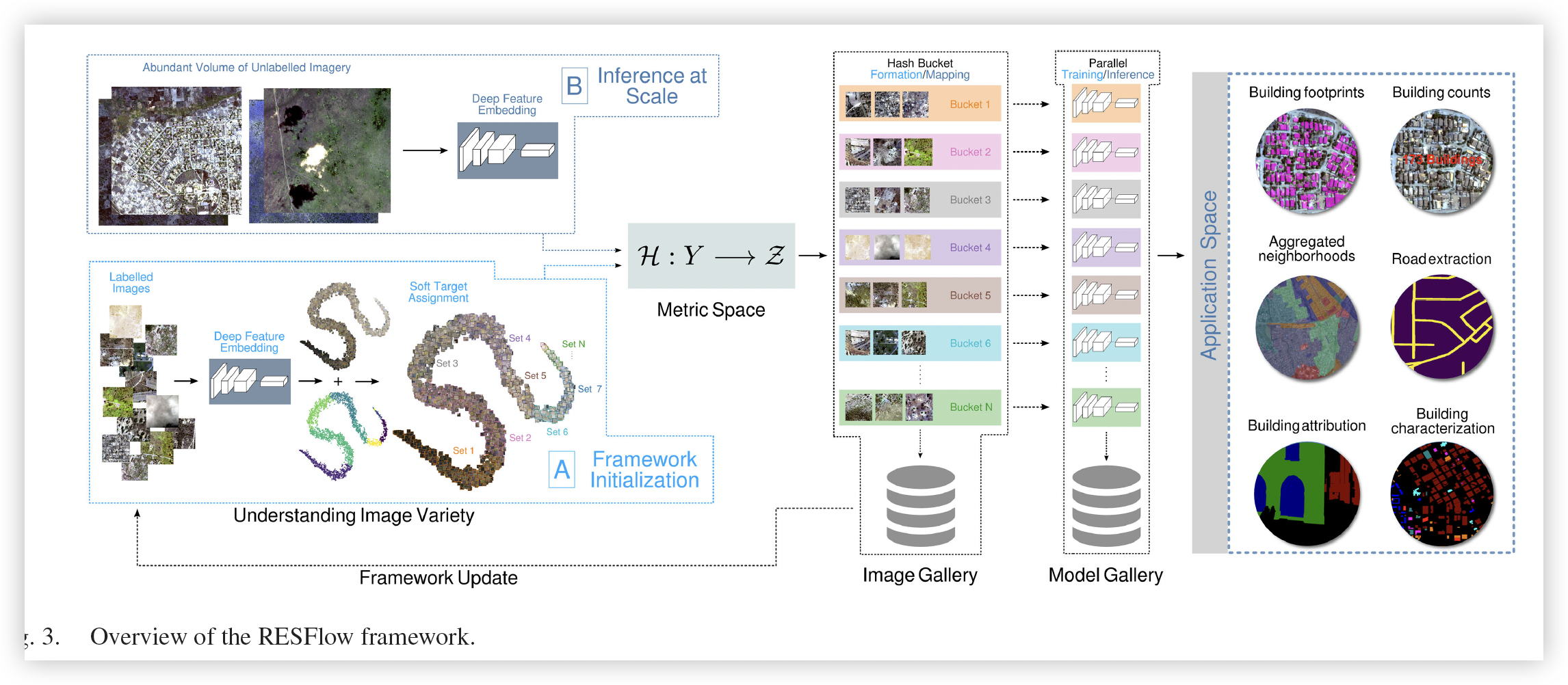
1. Clustering and Embedding module (CEM)
使用聚类进行分类。先使用已标注的图像标签训练深度模型,然后使用该深度模型对未标注的图像进行分类
聚类算法自选,提供图像所需的关键软标签
2. 图像桶分配方法
构建聚类图像的存储桶
使用汉明空间,通过学习哈希度量空间为每个图像生成唯一的二进制表示
3. 构建图片库
每个图片库都是一个相同的分区,是一组同质分区,属于有限多样性的集合,该集合不太依赖标签信息
4. 根据分区图片库构建模型库
使用图片库,构建各自的模型库,模型库被分区来完成多个任务
5. 合并各自的模型,来实现应用内容
特点
- RDD中存储图像位置的引用
- 对于每个图片库,可以使用不同的卷积神经网络来构建各自的模型库
- 我们实现了一个简单的
GPU Checkout Routine,允许在给定工作节点上的执行器之间进行 GPU 资源的软分配。
UDF 内容
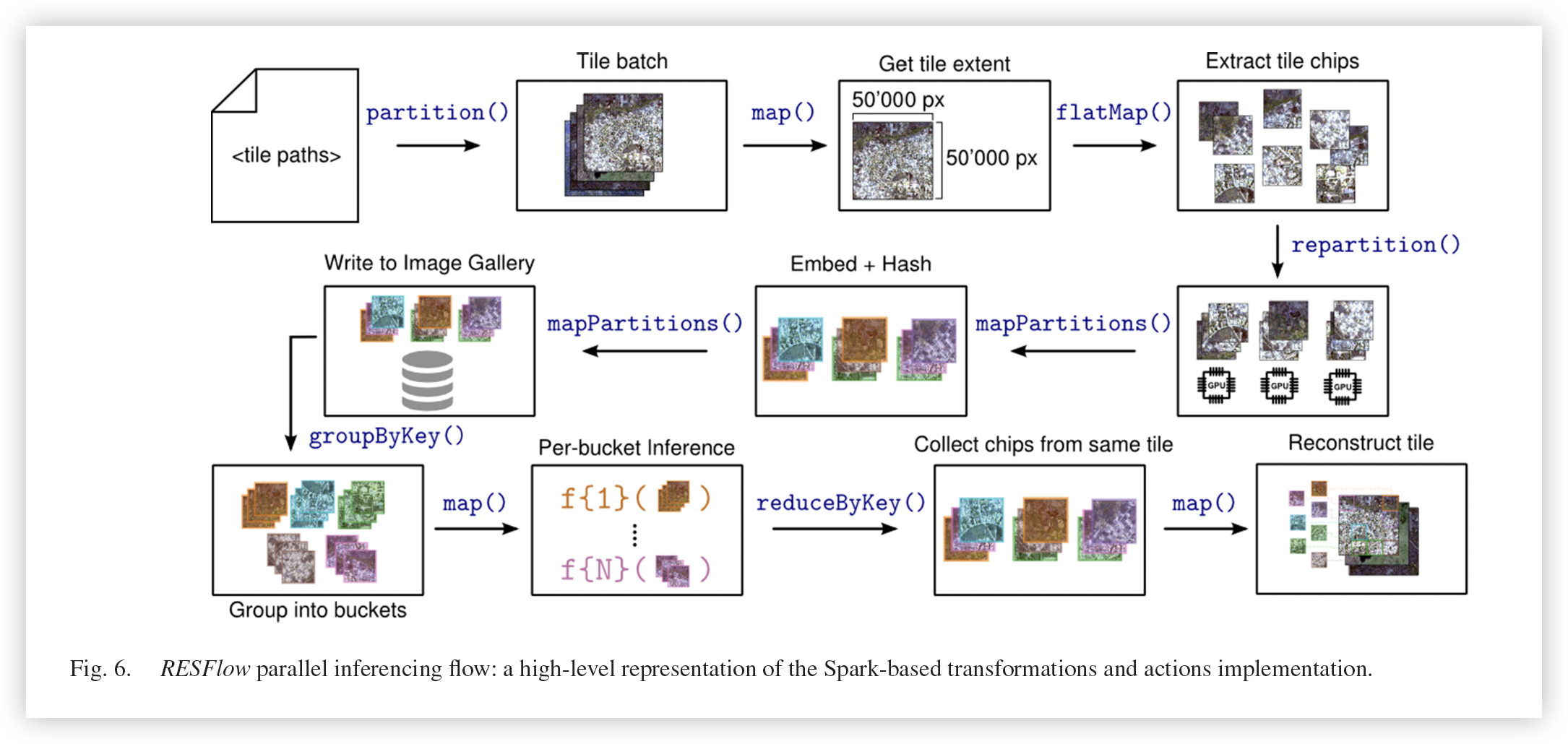
在Spark中是实现了多个UDF来实现ResFlow操作
-
partition()
将RDD中的图片提取出来并进行分区
-
map()
返回一个新的分布式数据集,其中每个元素都是由源RDD中一个大遥感图像元素经切分出来的50000px * 50000px的规格大小遥感图像
-
flatMap()
类似于map,将各自的规格大小图像提取特定区域碎片
-
repartition()
将RDD数据重新混洗(reshuffle)并随机分布到新的分区中,使数据分布更均衡。该算子总是需要通过网络混洗所有数据。并使用GPU计算(???聚类?)
-
mapPartitions()
类似于map,但基于每个RDD分区(或者数据block)独立运行
进行Embed提供图像所需的关键软标签 ,并通过每个图片的哈希度量空间为每个图片生成一个唯一二进制字符串
-
mapPartitions()
将图片分配到各自的图片库中
-
groupByKey()
通过软标签对图片库中的数据进行分组
-
map()
通过软标签构建各自的卷积模型库
-
reduceByKey()
将同一个文件切分的不同区域标注数据进行合并
-
map()
重新构建遥感区域内容
关键名词解释
tile : 遥感区域
chips : 切分出来的小区域
实现了一种新颖的遥感数据流(RESFlow),用于推进机器学习以计算大量遥感图像。 核心贡献是将大量数据划分为均匀分布以拟合简单模型。 RESFlow 利用 Apache Spark 和现代计算硬件的可用性来加速对广泛遥感图像的深度学习推理。