 KTurnura
commented
6 months ago
KTurnura
commented
6 months ago 简介
Spanner 是一个可扩展、多版本、全球分布式、同步复制的数据库。能够在全球范围内分发数据并支持外部一致性的分布式事务系统。实现了一个时钟同步的API,用来支持事务外部一致性,还用其实现了快照隔离非阻塞读取、只读事务的无锁执行,已经原子模式更改
特点
-
将数据分片到遍布世界各地的数据中心的多组Paxos状态机上如图所示
-
数据中心是为了加速全球范围内的本地读取(用户直接就近访问数据中心)
-
Spanner 自动跨机器重新分片数据,并自动跨机器(甚至跨数据中心)迁移数据以平衡负载并响应故障
-
Spanner 的主要重点是管理跨数据中心复制数据
-
使用时间戳标记数据,每个数据版本都自动加上了提交时间的时间戳,并且通过垃圾回收机制,限制旧版数据的增长
-
应用程序可以选择Spanner的数据中心包含哪些数据,数据与其用户的距离(以控制读取延迟)、副本彼此之间的距离有多远(以控制写入延迟)以及维护多少副本(以控制持久性、可用性和读取性能)。
-
系统可以在数据中心中动态、透明地移动数据,以平衡数据中心之间的资源使用
-
Spanner 提供读写的外部一致性,以及按时间戳跨数据库进行全局一致的读取。这些功能都是通过为事务分配具有全局意义的提交时间戳来启用的
- 时间戳反应事务的序列化顺序
- 序列化顺序满足外部一致性
-
抽象出directory(更好的定义应该是bucket,桶),用于管理复制和局部性,是数据移动的单位
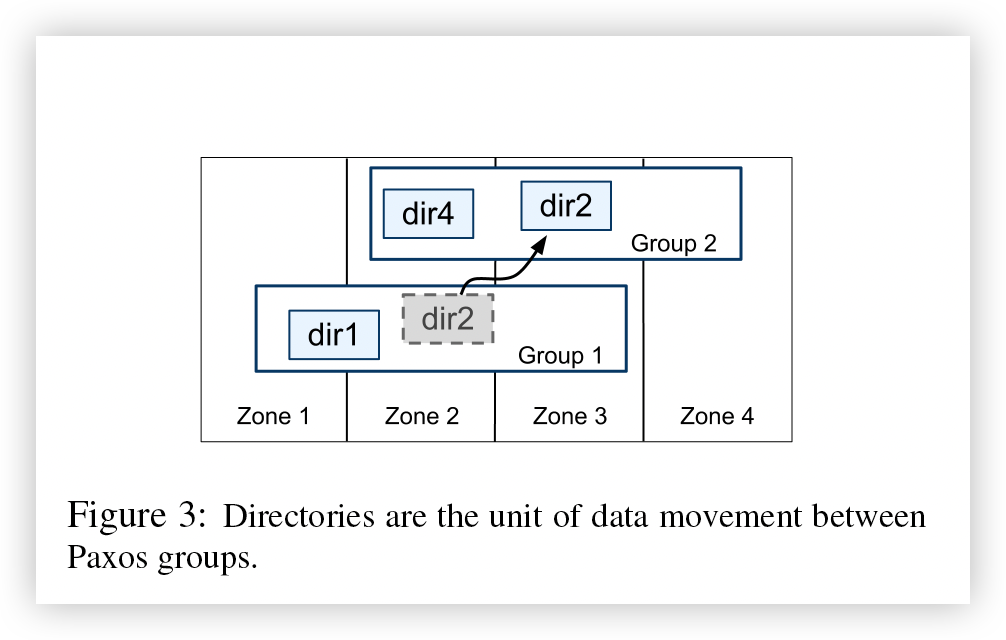
-
zone (数据中心的抽象)是Spanner管理部署的单位,当新数据中心投入使用和旧数据中心关闭时,可以分别在正在运行的系统中添加或删除zone
Spanner需要解决的两大问题
- 从本地数据中心读取数据
- 使用Paxos,Paxos只需要将每个日志条目复制到大多数follower中即可,但有时候每个DC可能还没有更新,可能还没看到由Paxos所提交的最新数据
- 如果使用本地数据来进行读取,那么它们所读取到的数据可能是过时的数据 ,比如属于Paxos大多数之外的那一小部分
- 使用外部一致性的思想,通过某种方式来处理本地replica数据的版本有点儿落后的情况
- 一个事务可能会涉及到多个数据分片,也就是多个Paxos组 ,因此我们需要使用分布式事务,
实现 implementation
Architecture
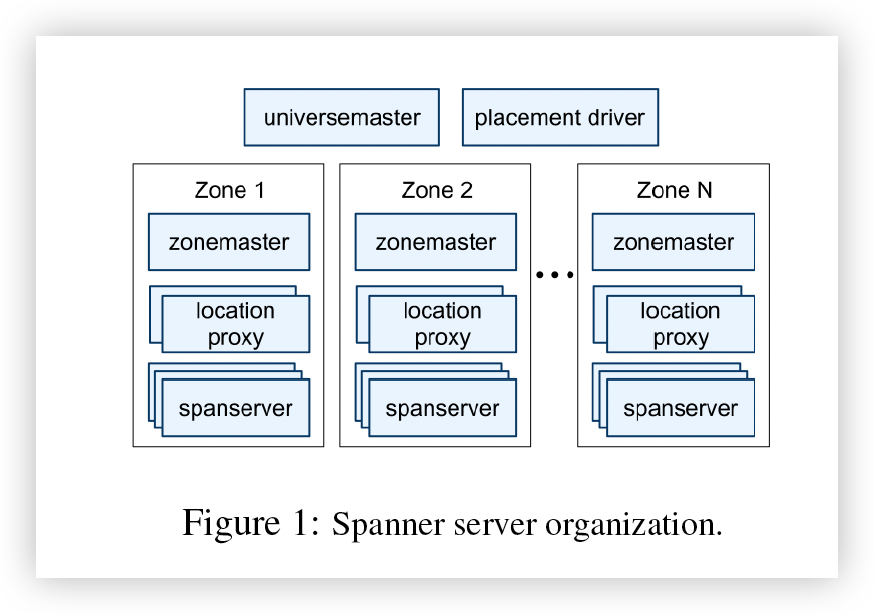
图一说明了Spanner Universe中的服务器,一个zone中有一个zone Master 和许多成百上千的spanserver,前者将数据分配给spanserver,后者向客户提供数据。客户端使用每个zone的 location proxy 来定位分配为其数据提供服务的 spanserver。
universe master 和 placement driver目前是单例
Universe master主要是一个控制台,用于显示所有区域的状态信息以进行交互式调试。
placement driver 主要是一个控制台,用于显示所有区域的状态信息以进行交互式调试,定期与spanserver通信以查找需要移动的数据,以满足更新的复制约束或平衡负载
本文余下部分主要讲spanserver
Spanserver 软件栈
Spanserver软件堆栈如图 2 所示。
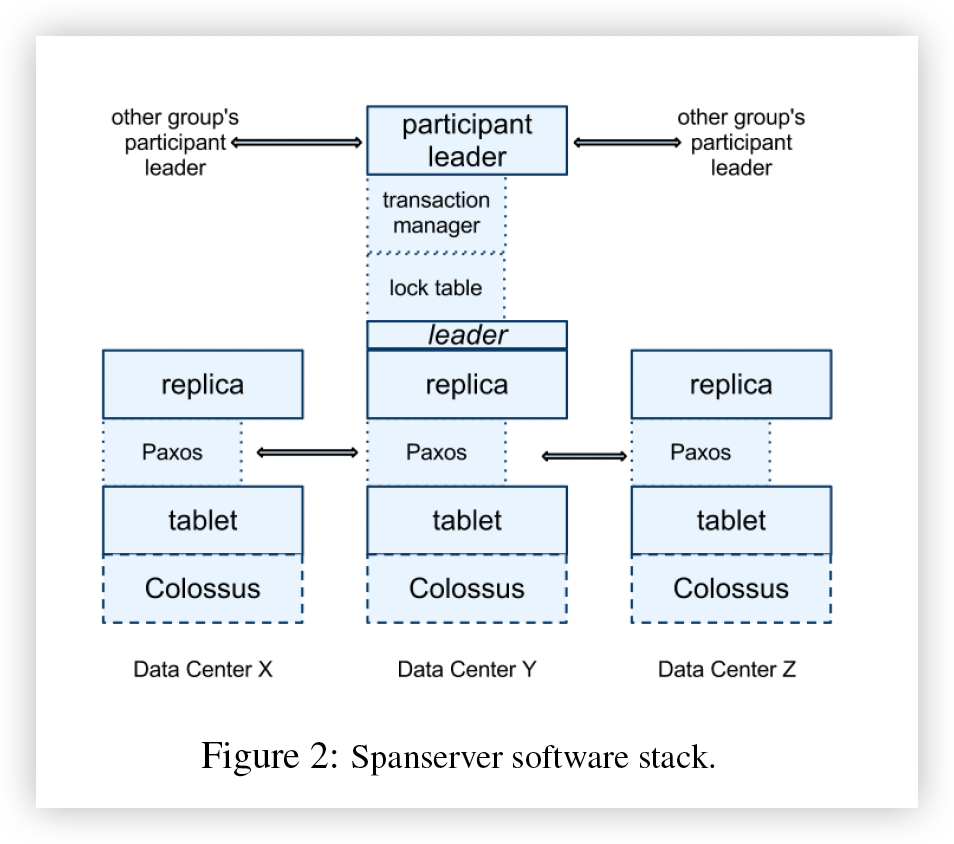
在底部,每个 spanserver 负责 100 到 1000 个称为“tablet”的数据结构实例。tablet类似于 Bigtable 的tablet抽象
与 Bigtable 不同,Spanner 为数据分配时间戳,这是 Spanner 更像是多版本数据库而不是键值存储的重要方式。
Tablet的状态存储在一组 B 树状文件和一个预写日志中,所有这些都存储在名为 Colossus 的分布式文件系统(Google 文件系统 [15] 的后继者)上。
为了支持复制,每个spanserver在每个tablet之上实现一个Paxos状态机。 (早期的 Spanner 版本支持每个 Tablet 多个 Paxos 状态机,这允许更灵活的复制配置。该设计的复杂性导致我们放弃了它。)
每个状态机都将其元数据和日志存储在其相应的 Tablet 中。 我们的 Paxos 实现通过基于时间的领导者租约支持长期领导者,其长度默认为 10 秒。 当前的 Spanner 实现会记录每个 Paxos 写入两次:一次在tablet日志中,一次在 Paxos 日志中。 这个选择是出于权宜之计,我们最终可能会纠正这个问题。
我们对 Paxos 的实施是管道化的,以便在存在 WAN 延迟的情况下提高 Spanner 的吞吐量; 但是 Paxos 会按顺序应用写入(我们将在第 4 节中依赖这一事实)。 Paxos 状态机用于实现一致复制的映射包(映射数据分片)。 每个副本的键值映射状态存储在其对应的tablet中。 写入必须在leader处启动Paxos协议; 直接从任何足够最新的副本上的tablet读取访问状态。 副本集统称为 Paxos 组。
Spanserver讲解
每个paxos 组都有自己的leader,leader所运行的是自己的Paxos 协议实例,每个Paxos组都有属于自己的leader,各自维护着独立的数据版本协议
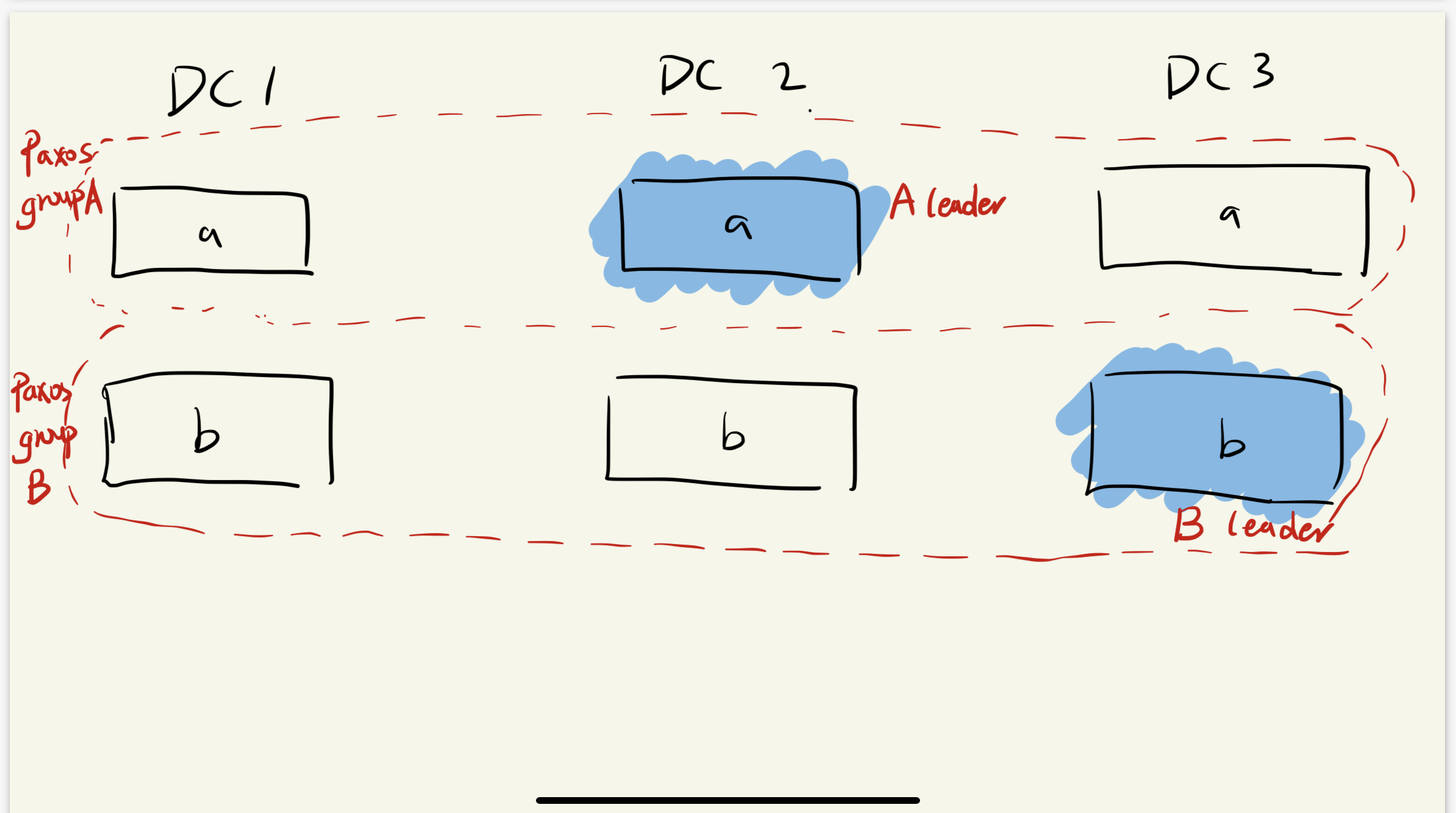
写请求发送给这个需要处理的数据分片所在Paxos 组中的leader
Paxos的作用就是转发该日志到follower,然后保证folower按照相同的执行顺序来执行这些日志记录的操作
如图:有三个DataCenter(DC),其中a、b分别是按照a、b开头的key键,Spanserver按照开头的不同对数据进行分片,三个数据中心相同数据的分片构成一个Paxos Group,选中DC2作为Paxos Group A的leader,,同理选中DC3作为Paxos Group B的leader
Read Write Transaction
在每个作为领导者的副本中,每个spanserver都实现一个锁表来实现并发控制(针对Read-Write 事务)。 锁表包含两阶段锁定的状态:它将键的范围映射到锁状态(单个锁映射一片键区域)。
在存在冲突的乐观并发控制下表现不佳。 需要同步的操作,例如事务性读取,会获取锁表中的锁; 其他操作绕过锁表。
在作为领导者的每个副本中,每个 spanserver 还实现一个Transaction manager来支持分布式事务。 Transaction manager用于实现参与者领导者; 该组中的其他副本将被称为参与者从属副本。
如果一笔事务仅涉及一个 Paxos 组(大多数事务都是这种情况),则它可以绕过事务管理器,因为锁表和 Paxos 一起提供事务性。 (最初的二阶段提交过程)
如果一笔事务涉及多个 Paxos 组,这些组的领导者会协调执行两阶段提交。 选择一个参与者组作为协调者:该组的参与者领导者将被称为协调者领导者,该组的从者将被称为协调者从者。 每个事务管理器的状态都存储在底层 Paxos 组中(因此会被复制)。
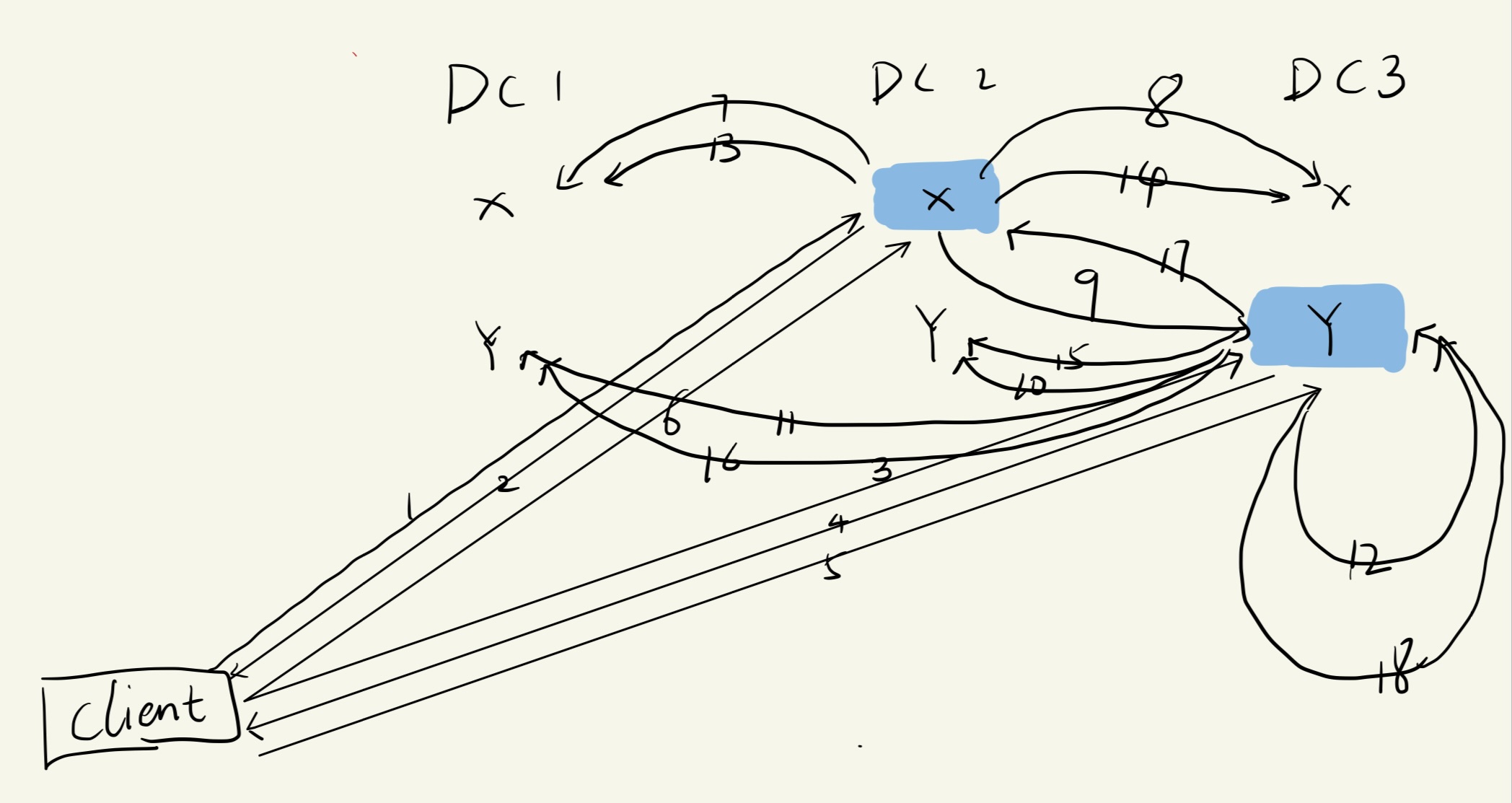
如图所示
三个数据中心,其中DC2保存x键值区域所在的leader,DC3保存y键值区域所在的leader
Client提交一个涉及x和y键值的任务,按箭头步骤如下
- client Requet x
- return x
- client Request y
- return y
- 指定Transaction Manager(也可以是DC2所在的X Paxos leader),同时请求写入Y
- 请求写入X,同时通知X Y leader成为Transaction Manager
- Paxos确认DC1该X写入是否可以提交
- Paxos确认DC3该X写入是否可以提交
- X Paxos leader反馈给Transaction Manager 该X可以提交该写入
- Paxos确认DC2该Y写入是否可以提交
- Paxos确认DC1该Y写入是否可以提交
- Y Paxos leader 反馈给Transaction Manager(他自身)该Y可以提交该写入
- log 预写入
- log 预写入
- log预写入
- log 预写入
- 事务提交
- 事务提交
Spanner Read-Write Trasaction 特点
- Spanner使用2PL,来获得可序列化性和完全标准的2PC来获取分布式事务
- Spanner通过复制事务管理器(TM)来解决2PC卡住(2PC阶段发生故障,一直持有锁)的问题
- TM本身是Paxos复制状态机,所以他所做的一切都可以被其他server感知,其他server不仅可以接管leader,还可以接管TM(接管后继续进行2PC)
Directories and Placement
在键值映射包之上(数据分片),Spanner 实现支持称为目录的分桶抽象,它是一组共享公共前缀的连续键。目录的支持 允许应用程序通过仔细选择键来控制其数据的位置。
目录是数据放置的单位。 目录中的所有数据都具有相同的复制配置。 当数据在 Paxos 组之间移动时,数据会逐目录移动,Spanner 可能会移动目录以减轻 Paxos 组的负载;
将经常访问的目录放在同一个组中; 或者将目录移动到更靠近其访问者的组中。 当客户端操作正在进行时,可以移动目录。 人们预计 50MB 的目录可以在几秒钟内移动。
Paxos 组可能包含多个目录这一事实意味着 Spanner tablet与 Bigtable tablet不同:前者不一定是行空间的单个字典顺序连续分区。 ==相反,Spanner tablet是一个可以封装行空间的多个分区的容器。==
我们做出这个决定是为了可以将经常访问的多个目录放在一起。
_Movedir_是用于在 Paxos 组之间移动目录的后台任务 [14]。 Movedir 还用于向 Paxos 组添加或删除副本 [25],因为 Spanner 尚不支持 Paxos 内配置更改。_Movedir_不作为单个事务实现,以避免阻塞大量数据移动中正在进行的读取和写入。 相反,_Movedir_会记录它正在开始移动数据的事实,并在后台移动数据。 当它移动了除名义数量之外的所有数据时,它使用事务以原子方式移动该名义数量并更新元数据 两个 Paxos 组。
目录也是应用程序可以指定其地理复制属性(或简称放置)的最小单元。 我们的放置规范语言的设计将管理复制配置的职责分开。 管理员控制两个维度:副本的数量和类型,以及这些副本的地理位置。 他们在这两个维度上创建了一个命名选项菜单(e.g., North America, replicated 5 ways with 1 witness).。 应用程序通过使用这些选项的组合标记每个数据库和/或单个目录来控制数据的复制方式。 例如,应用程序可能将每个最终用户的数据存储在自己的目录中,这将使用户 A 的数据在欧洲拥有三个副本,用户 B 的数据在北美拥有五个副本。
为了说明清楚起见,过于简化配置要求。 事实上,如果目录变得太大,Spanner 会将其分割成多个片段。 片段可以由不同的 Paxos 组(因此也由不同的服务器)提供。 Movedi 实际上在组之间移动片段,而不是整个目录。
Data Model
Spanner 向应用程序公开了以下一组数据功能:基于模式化半关系表的数据模型、查询语言和通用事务
应用程序数据模型位于实现支持的目录存储键值映射之上。 应用程序在 Universe 中创建一个或多个数据库。 每个数据库可以包含无限数量的模式化表。 表看起来像关系数据库表,具有行、列和版本化值。
Spanner 的数据模型不是纯粹的关系模型,因为行必须有名称。 更准确地说,每个表都需要有一组有序的一个或多个主键列。 在这一要求下,Spanner 仍然看起来像一个键值存储:主键形成行的名称,每个表定义从主键列到非主键列的映射。 仅当为行的键定义了某个值(即使它是 NULL)时,该行才存在。 强加这种结构很有用,因为它允许应用程序通过键的选择来控制数据局部性。
图 4 包含一个示例 Spanner 架构,用于按用户、按相册存储照片元数据。
模式语言与 Megastore 的类似,但附加要求是每个 Spanner 数据库必须由客户端分区为一个或多个表层次结构。 客户端应用程序通过 INTERLEAVE IN 声明来声明数据库模式中的层次结构。

层次结构顶部的表是目录表。 目录表中具有键 K 的每一行以及后代表中按字典顺序以 K 开头的所有行一起形成一个目录。 ON DELETE CASCADE 表示删除目录表中的行会删除所有关联的子行。
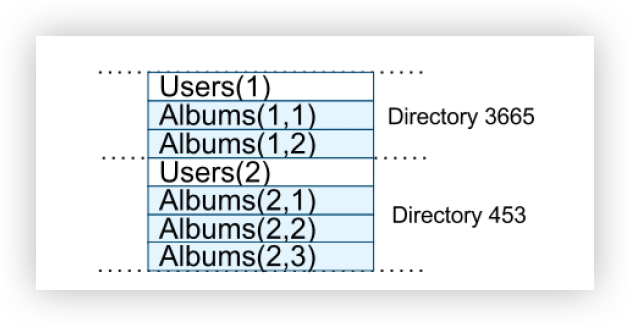
上图还说明了示例数据库的交错布局:例如,Albums(2,1) 表示专辑表中用户 id 2、专辑 id 1 的行。表的这种交错形成目录非常重要,因为它允许客户端 描述多个表之间存在的局部性关系,这对于分片分布式数据库的良好性能是必要的。(我的理解是此处Albums(1,1)指定的是用户id和数据分片所在的位置)
如果没有它,Spanner 将不知道最重要的局部关系
TrueTime
| Method | Returns |
|---|---|
| TT.now | 返回一个区间:[earliest, latest] |
| TT.after(t) | 如果t时刻确认通过,则返回true |
| TT.before(t) | 如果t时刻还没有到达,则返回true |
Spanner基于时间戳实现了很多有意义的操作
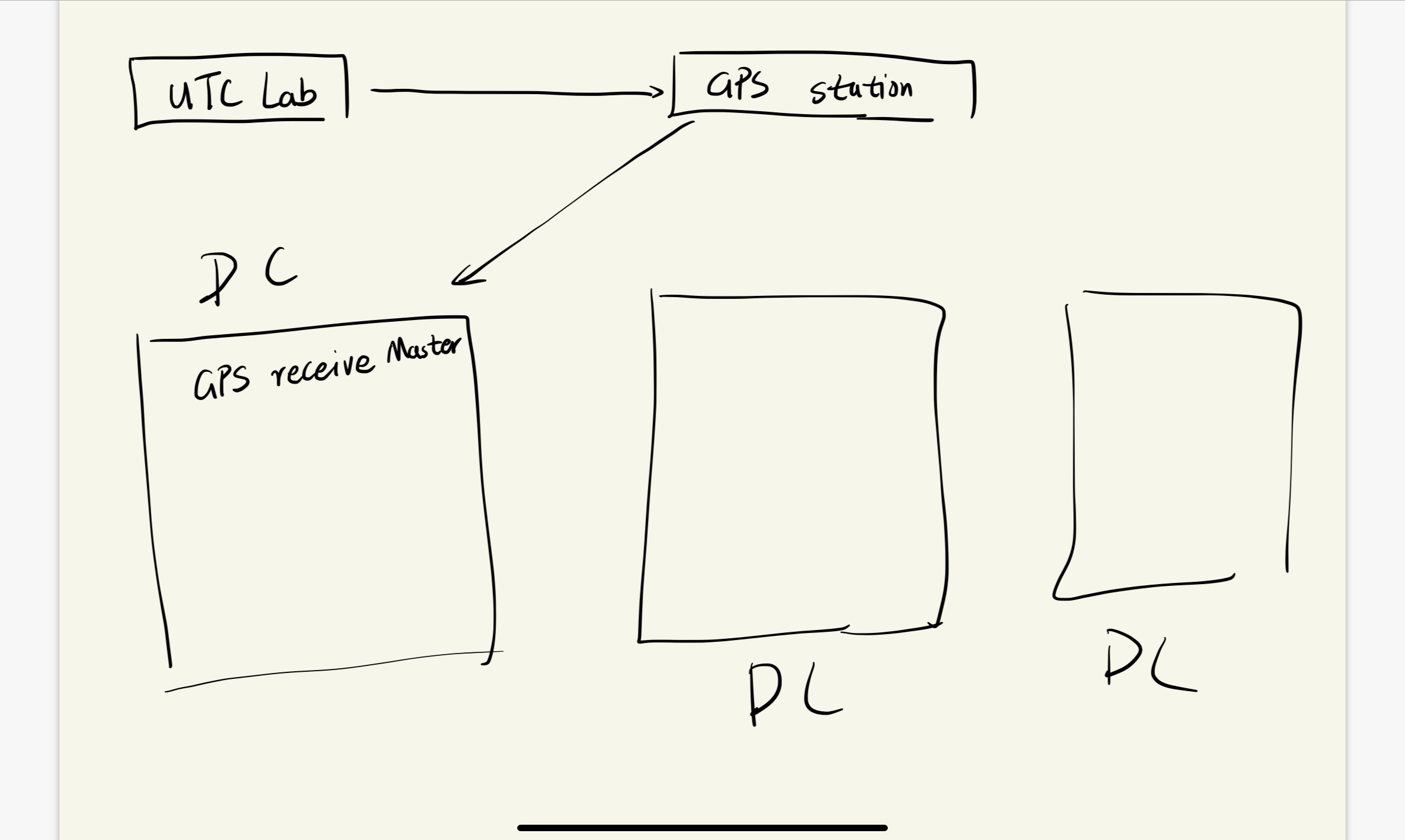
UTC lab实际上是收集各种时钟和政府实验室的时钟中位数,这个时间是通过各种协议广播来的:比如无线电协议,比如GPS,
Spanner使用GPS充当广播当前时间的无线电广播系统
从一些政府实验室发送到Google机房
系统必须对从GPS Receiver中的数据添加未知但估计的局部漂移(因为通信延迟、机器过载、网络链路过载等原因导致)
总之,Spanner实现了一个可靠的时间获取API,保证不出现离谱的时间漂移
并发控制
Spanner使用TrueTime API来保证并发控制的正确性
实现了外部一致性,无锁的执行只读事务,非阻塞读取等功能
如果没有时间戳,无法保证事务序列化执行

如图所示,T1,T2为写事务,T3为只读事务,T3对y值的读取延迟,导致读取的y值实际为T2所写的y值
只读事务
只读事务是一种具有快照隔离性能优势的事务。 只读事务必须预先声明为没有任何写入; 它不仅仅是一个没有任何写入的读写事务。 只读事务中的读取在系统选择的时间戳上执行,无需锁定,因此传入的写入不会被阻止。 只读事务中读取的执行可以在任何足够最新的副本上继续
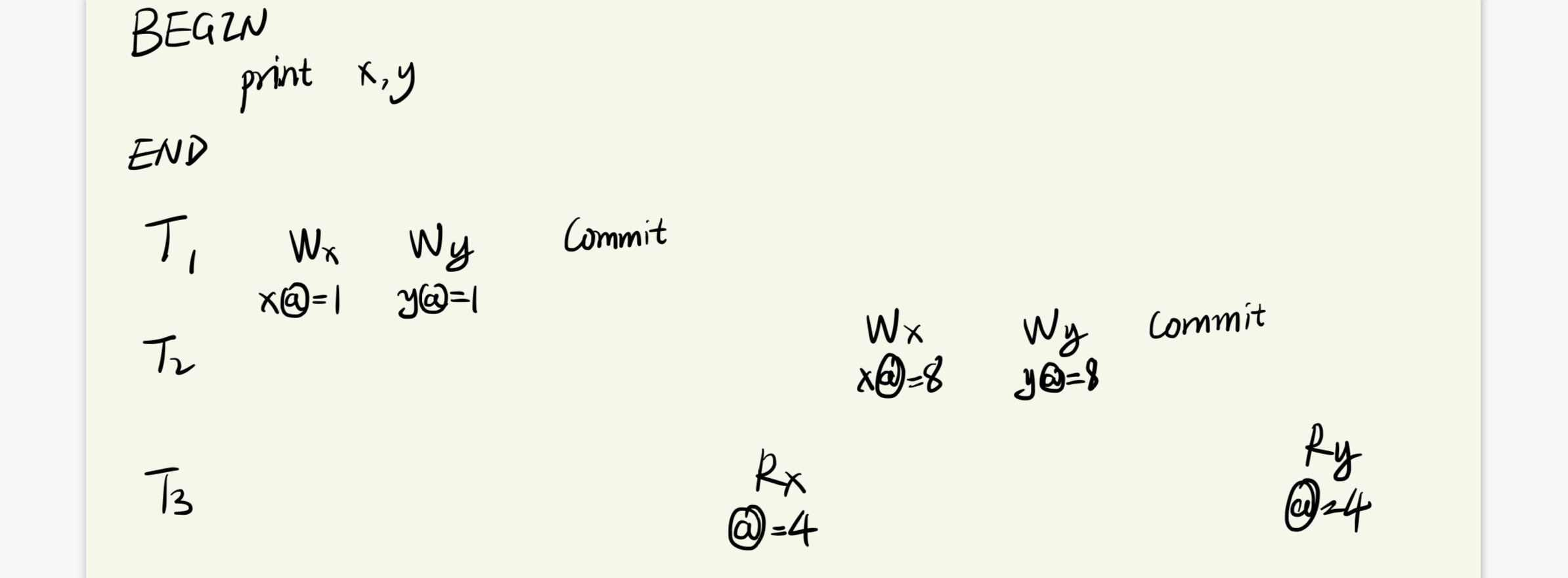
这次,我们给事务添加上时间戳,一般时间戳为事务提交的时间,
T1在timestamp=1的时候提交,给T3事务指定的读取时间戳为4,此时事务T3所有对Paxos Group的读取时间戳都为4,以此形成了快照(即它只能获取某个键时间戳<=4的值),这样后续T2事务的写入不会影响T3事务的读取,即实现了并发控制所提到的三个功能:外部一致性,无锁的执行只读事务,非阻塞读取
question
如何给只读事务和读写事务分配时间戳
Timestamp Management
Paxso Leader lease
Spanner 的 Paxos 实现使用定时租约来使领导力长期有效(默认为 10 秒)。 潜在领导者发送定时租赁投票请求; 在收到法定人数的租赁投票后,领导者知道它有一个租赁。 副本在成功写入时隐式延长其租约投票,并且领导者在租赁投票即将到期时请求延期。 将领导者的租约间隔定义为当它发现它具有法定数量的租赁投票时开始,以及当它不再具有法定数量的租赁投票时结束
定义领导者Lease的最大时间戳为$s{max}$ ,在Leader 放弃之前,必须确保$TT.after(s{max}) == true$
Assigning Timestamp to R/W Transactions
事务性读取和写入使用两阶段锁定。 因此,在获取所有锁后但在释放任何锁之前,可以随时为它们分配时间戳。 对于给定的事务,Spanner 为其分配 "Paxos 分配给表示事务提交的 Paxos 写入的时间戳"。
Spanner 依赖于以下单调性不变量:在每个 Paxos 组内,Spanner 以单调递增的顺序为 Paxos 写入分配时间戳,甚至跨领导者也是如此。 单个领导者副本可以简单地按单调递增的顺序分配时间戳。 领导者必须只在其领导者租约的间隔内分配时间戳。
Spanner 还强制执行以下外部一致性不变量:如果事务 T2 的启动发生在事务 T1 的提交之后,则 T2 的提交时间戳必须大于 T1 的提交时间戳。
定义$T_i$的开始和提交时间为$e_i^{start}$和$e_i^{commit}$,以及事务 i 的提交时间戳为$s_i$
则:$t_{abs}(e1^{commit})<t{abs}(e_2^{start})\Rightarrow s_1<s_2$
执行事务和分配时间戳的协议遵循两条规则,这两条规则共同保证了这一不变性,如下所示。 定义写 Ti 的提交请求到达协调者领导者的事件为$e_i^{server}$
Rule:
- Start : 写 Ti 的协调领导者分配的提交时间戳 si 不小于 $TT.now().latest$ 的值,在 $e_i^{server}$之后计算。
- Commit Wait: 协调者领导者确保客户端在 $TT.after(si) $为 true 之前无法看到 Ti 提交的任何数据。 提交等待确保 si 小于 Ti 的绝对提交时间,或者 $si < t{abs}(e_i^{commit})$。
Serving Reads at a Timestamp
[上节](###Assigning Timestamp to R/W Transactions)中描述的单调不变量允许 Spanner 正确确定副本的状态是否足够最新以满足读取。 每个副本都会跟踪一个称为安全时间 $t{safe}$的值,该值是副本保持最新状态的最大时间戳。 如果 $t <= t{safe}$,副本可以满足时间戳 t 处的读取。
$t_{safe}$的计算看论文
Assigning Timestamp to RO Transactions
只读事务分两个阶段执行:分配时间戳 $s{read}$,然后在$s{read}$处将事务的读取作为快照读取执行。 快照读取可以在任何足够最新的副本上执行。 在事务开始后的任何时间,简单地分配$ s{read} = TT.now().latest$,通过类似于第 4.1.2 节中为写入提供的参数来保留外部一致性。 然而,如果$t{safe}$ 没有充分提前,这样的时间戳可能需要在 $s{read}$ 处执行数据读取以阻止。 (此外,请注意,选择$s{read}$ 的值也可能会提前 $s_{max}$ 以保持不相交。)为了减少阻塞的机会,Spanner 应分配最旧的时间戳以保持外部一致性。 [下面]()解释了如何选择这样的时间戳。
Timestamp Assign Details
Read-Write Transaction
与 Bigtable 一样,事务中发生的写入会在客户端进行缓冲,直到提交为止(称其为prepare阶段)。 因此,事务中的读取看不到事务写入的影响。 这种设计在 Spanner 中效果很好,因为读取会返回任何数据读取的时间戳,而未提交的写入尚未分配时间戳。
读写事务中的读取使用woundwait来避免死锁。 客户端向相应组的领导者发出读取,该领导者获取读锁,然后读取最新的数据。 当客户端事务保持打开状态时,客户端事务会发送keepalive消息以防止多个Paxos组的leader超时其事务。 当客户端完成所有读取并缓冲所有写入后,客户端事务开始两阶段提交。
客户端选择一个Coordinator Manager(此处选择DC3中的Y数据),并向每个Paxos的领导者(DC2中的X分片和DC3中的Y分片)发送一条提交消息,其中包含协调器的身份和任何缓冲的写入。 让客户端驱动两阶段提交可以避免在广域链路上发送两次数据。
非协调者参与者领导者(图中的DC2 中的X)首先获取写锁。 然后,它选择一个准备时间戳,该时间戳必须大于分配给先前事务的任何时间戳(以保持单调性),并通过 Paxos 记录准备记录。 然后,每个参与者将其准备时间戳通知协调员。
协调领导者(图中的DC3 中的Y)也首先获取写锁,但跳过准备阶段。 它在听取所有其他参与者领导者的意见后为整个交易选择一个时间戳。 提交时间戳 s 必须大于或等于所有准备时间戳(以满足第 4.1.3 节中讨论的约束),大于协调器收到其提交消息时的 TT.now().latest,并且大于任何时间戳领导者(DC3 中的 Y)已分配给以前的事务(同样,为了保持单调性)。 然后协调者领导者通过 Paxos 记录提交记录(如果在等待其他参与者时超时则中止)。
在允许任何协调器副本应用提交记录之前,协调器领导者会等待直到 TT.after(s),以便遵守第 4.1.2 节中描述的提交等待规则。 因为协调者领导者根据 TT.now().latest 选择了 $s$,并且现在等待直到该时间戳保证是过去的,所以还需要预留一段时间的等待时间$\phi$,即最终确定的提交时间为$s + \phi$
这种等待时间$\phi$通常与 Paxos 通信重叠, 因此不增加太多的延迟。 提交等待后,协调者将提交时间戳发送给客户端和所有其他参与者领导者。 每个参与者领导者都通过 Paxos 记录交易的结果。 所有参与者在相同的时间戳处申请,然后释放锁。
Read-only Transaction
分配时间戳需要在读取中涉及的所有 Paxos 组之间进行协商阶段。 因此,Spanner 需要为每个只读事务提供一个作用域表达式,该表达式总结了整个事务将读取的键。 Spanner 自动推断独立查询的范围。
如果范围的值由单个 Paxos 组提供,则客户端向该组的领导者发出只读事务。 (当前的 Spanner 实现仅为 Paxos 领导者处的只读事务选择时间戳,只通过Paxos领导者处获取数据)该领导者分配 $s{read}$并执行读取。 对于单站点读取,Spanner 通常比 TT.now().latest 做得更好。 将 LastTS() 定义为 Paxos 组中最后提交的写入的时间戳。 如果没有处于prepare状态的事务,则赋值 $s{read} = LastTS() $一般会满足外部一致性:事务将看到上次写入的结果,因此会在其之后排序。
如果范围的值由多个 Paxos 组提供,则有多种选择。 最复杂的选择是与所有组的领导者进行一轮沟通,以基于 LastTS() 协商 sread。 Spanner 目前实现了一个更简单的选择。 客户端避免了一轮协商,并且仅在 $s_{read} = TT.now().latest$处执行读取(这可能会等待安全时间提前)。 事务中的所有读取都可以发送到足够最新的副本
Schema-Change Transactions
TrueTime 使 Spanner 能够支持原子架构更改。 使用标准事务是不可行的,因为参与者的数量(数据库中的组的数量)可能达到数百万。
Spanner 架构更改事务通常是标准事务的非阻塞变体。
首先,它被明确分配一个未来的时间戳,该时间戳在准备阶段注册。 因此,可以在对其他并发活动造成最小干扰的情况下完成数千台服务器的架构更改。 其次,隐式依赖于模式的读取和写入与时间 t 处任何注册的模式更改时间戳同步:如果它们的时间戳早于 t,则它们可以继续进行,但如果它们的时间戳晚于 t,则它们必须阻塞在模式更改事务之后。
Refinement 改进
-
$t{safe}$的取值,单个准备好的交易会阻止$t{safe}$增加。即使读取不与事务冲突,在后面的时间戳也不会发生读取。通过使用从关键范围到准备好的交易时间戳的细粒度映射来可以消除此类错误冲突(这里还包含Read-Only Transaction 时间戳选择的另一个参数,可以看原论文)。该信息可以存储在锁表中,该表已经将键范围映射到锁元数据。 当读取到达时,只需要根据与读取冲突的键范围的细粒度安全时间进行检查。
-
上面定义的 LastTS() 也有类似的缺点( LastTS() : Paxos 组中最后提交的写入的时间戳)
如果事务刚刚提交,则仍必须为非冲突的只读事务分配 $s_{read}$以便跟随该事务。 因此,读取的执行可能会延迟。 这个弱点可以通过使用从键范围到锁表中提交时间戳的细粒度映射来扩展 LastTS() 来类似地弥补 (我们还没有实现这个优化。)
原文:This weakness can be remedied similarly by augmenting LastTS() with a fine-grained mapping from key ranges to commit timestamps in the lock table.
当一个只读事务到达时,它的时间戳可以通过取该事务冲突的key range的LastTS()的最大值来分配,除非有一个冲突的准备好的事务( 可以从细粒度的安全时间确定)
-
求取$t{safe}$所需的参数中包含参数$t{safe}^{Paxos}$, 该参数有一个弱点, 在没有 Paxos 写入的情况下它无法前进,也就是说,在 t 处读取的快照无法在最后一次写入发生在 t 之前的 Paxos 组上执行(这个没看懂)
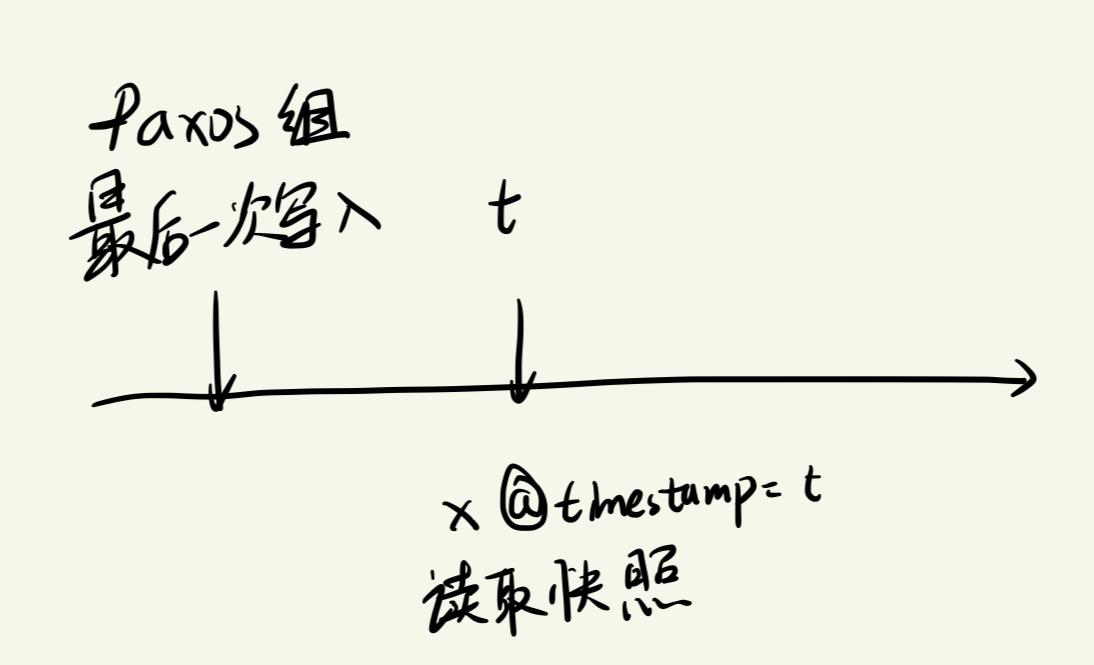
主要是这个执行没看懂
Spanner 通过利用领导者租用间隔的不相交性来解决这个问题。这个Refine的细节可以自行看原文
MIT 6.824中提到了一个内容,应该是针对这个Refine的补充
如果本地数据库是Paxos更新的少数(即Paxos中尚未更新的一小部分),该如何处理:
我们的本地数据库可能永远都不会更新
Spanner使用Safe Time的概念来解决这个问题
每个副本都记住从Paxos leader获取的日志记录
leader 严格按照增长的时间戳顺序发送log日志,因此副本可以看到其领导者发送的最新的log 记录,并知道他是如何更新的
如果我想要一个timestamp = 15的值,但 副本只从Paxos leader处获得了一个timestamp = 13的日志值, replica会要求延迟对该副本某个值的读取,直到日志到达
总结
- 快照隔离提供了可序列化的只读事务
- 交易迅速,有吸引力,没有锁定,没有两阶段提交,提供近距离副本阅读
- 支持无锁的只读事务,读写事务仍然适用2PC和锁定
- 依然会出现读阻塞的情况:Refinement中的第三条,但是延迟很小
Spanner 是一个可扩展、多版本、全球分布式、同步复制的数据库。能够在全球范围内分发数据并支持外部一致性的分布式事务系统。实现了一个时钟同步的API,用来支持事务外部一致性,还用其实现了快照隔离非阻塞读取、只读事务的无锁执行,已经原子模式更改。