 KTurnura
commented
6 months ago
KTurnura
commented
6 months ago FaRM和Spanner 区别
他们都实现了复制和两阶段提交
Spanner主要关注于跨地理位置的数据事务安排,建立副本,方便访问,解决了二阶段提交上的时间问题等等
FaRM是一种原型,当时并没有落地,他假设:所有的replica都在同一个数据中心
容错能力范围:针对单个服务器的崩溃,当整个数据中心故障后,如何恢复数据
特点:使用RDMA技术,但也因为该技术限制了某些控制、鉴权系统的使用,因此,FaRM强制使用乐观锁并发控制来结合RDMA使用,在事务提交的过程中验证身份;所获得的性能比Spanner快很多 ,FaRM要比Spanenr快100倍,性能高出太多了!!!
Spanner 和 FaRM针对的是分布式事务系统中不同的瓶颈:FaRM主要针对的系统瓶颈在于服务器上的CPU时间,FaRM将所有的replica放在同一个数据中心中,以此来消除卫星信号和网络传播所带来的延迟 ,而Spanner则是为了解决地理位置上的访问速度,以及跨数据中心容错等问题
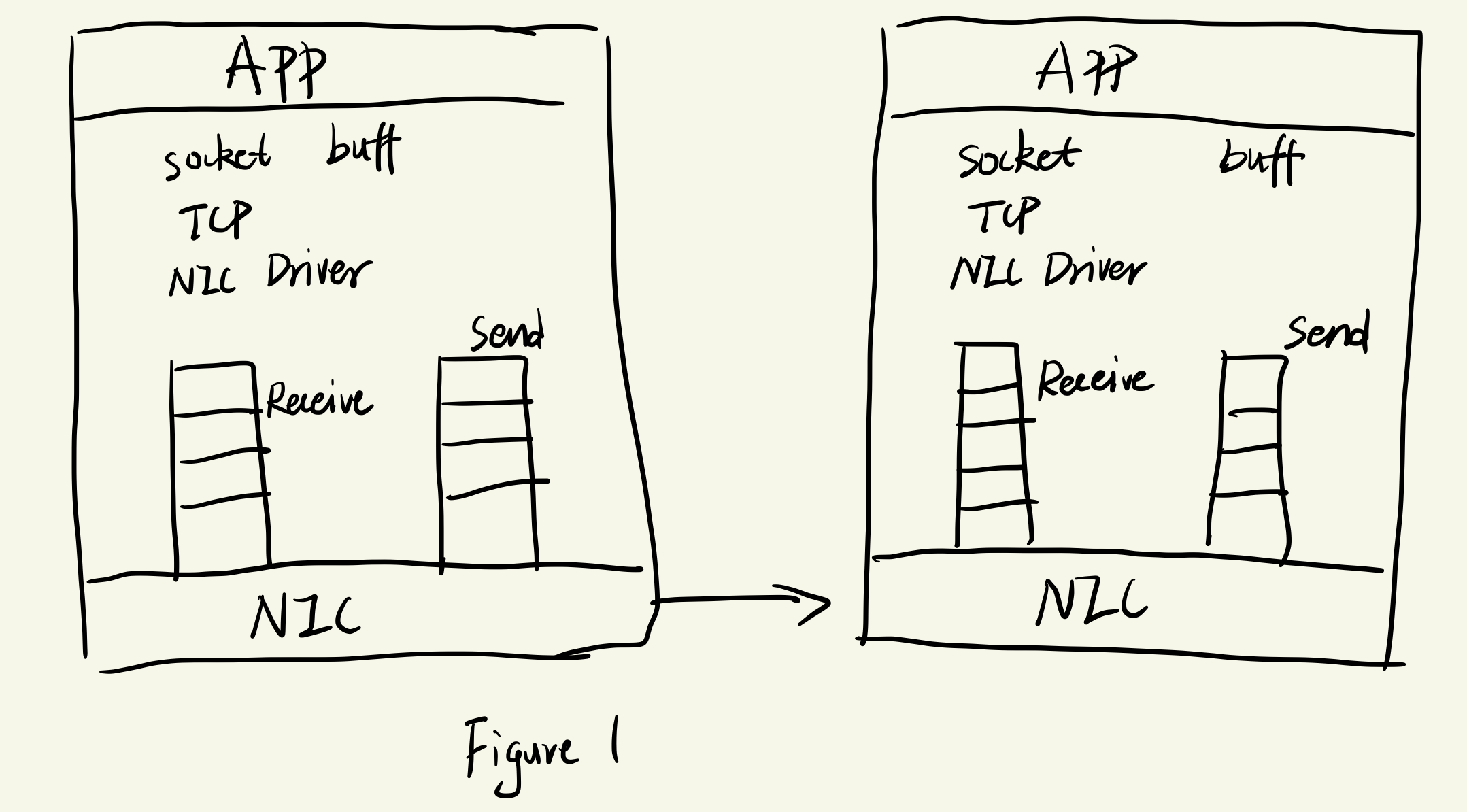 FaRM 思路:减少推送数据包成本
两种方式结合使用
FaRM 思路:减少推送数据包成本
两种方式结合使用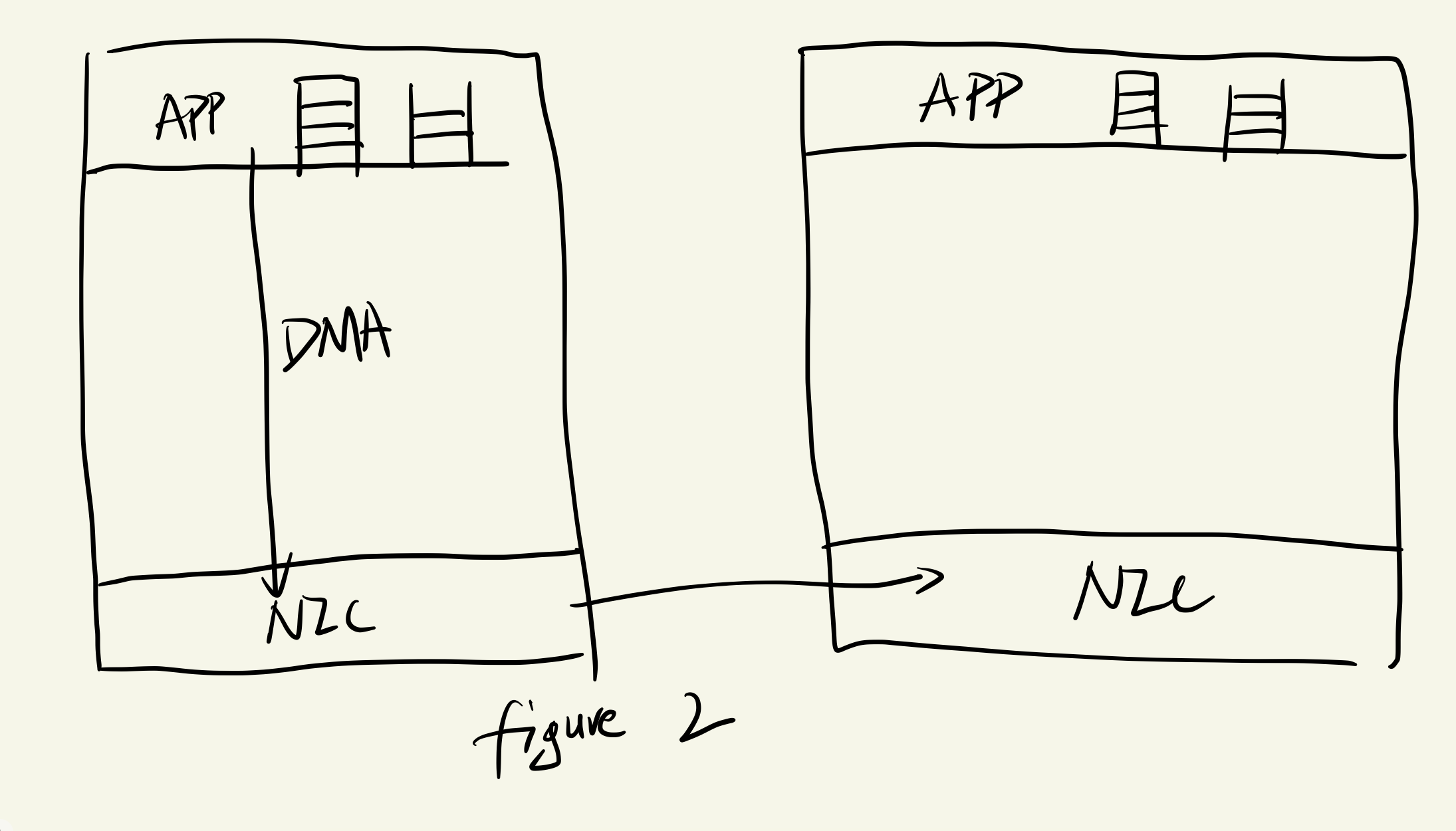
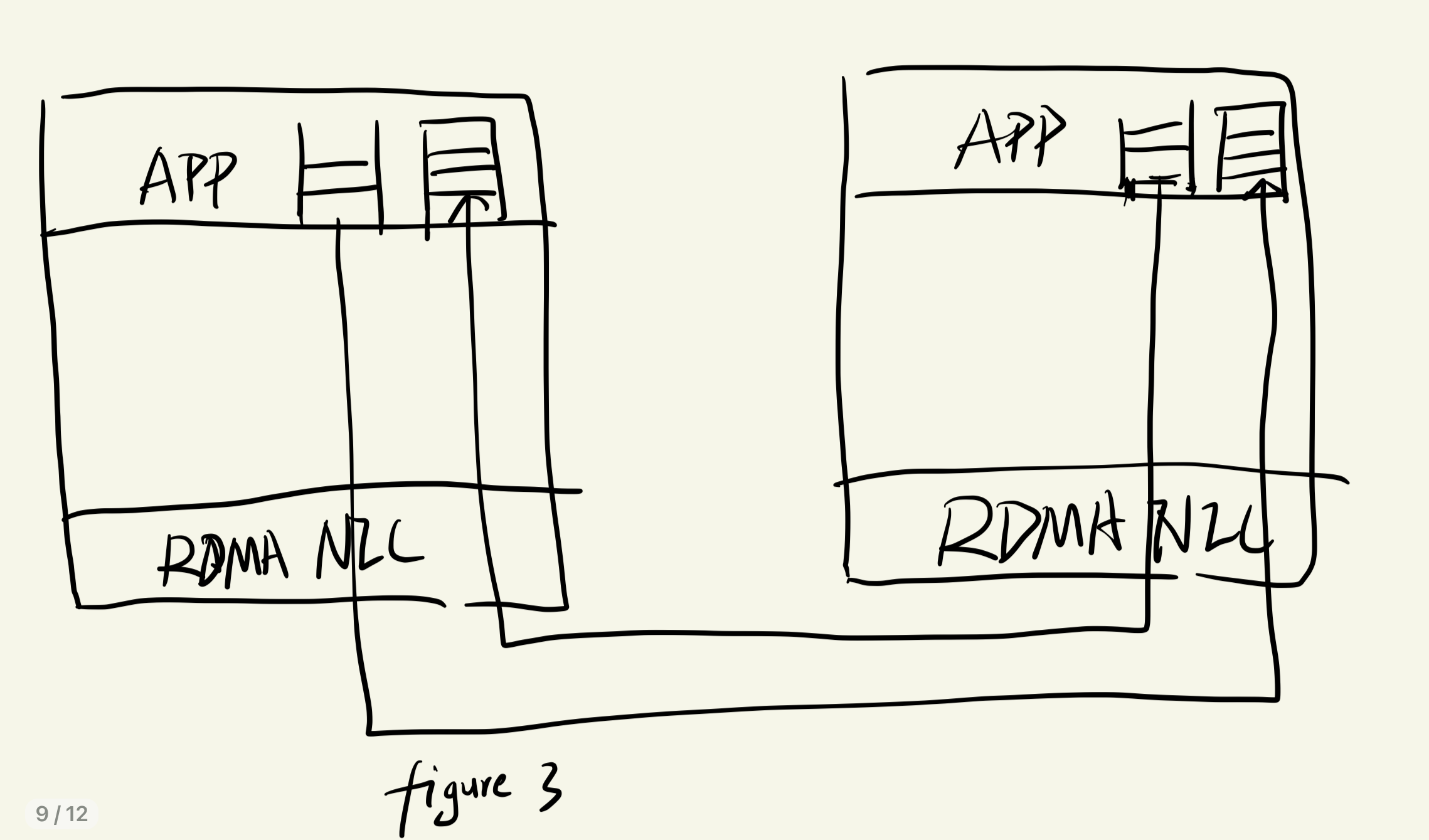
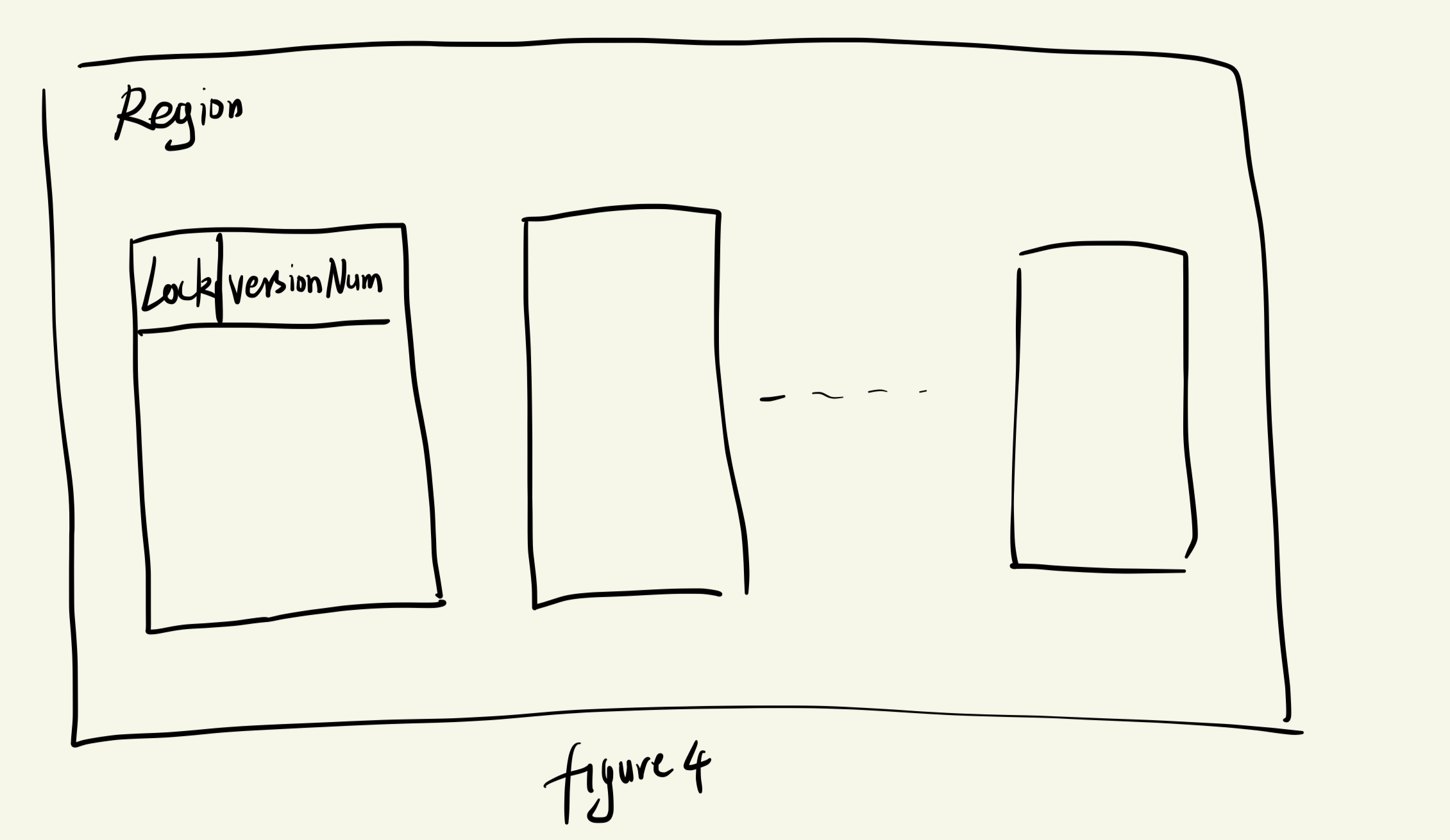
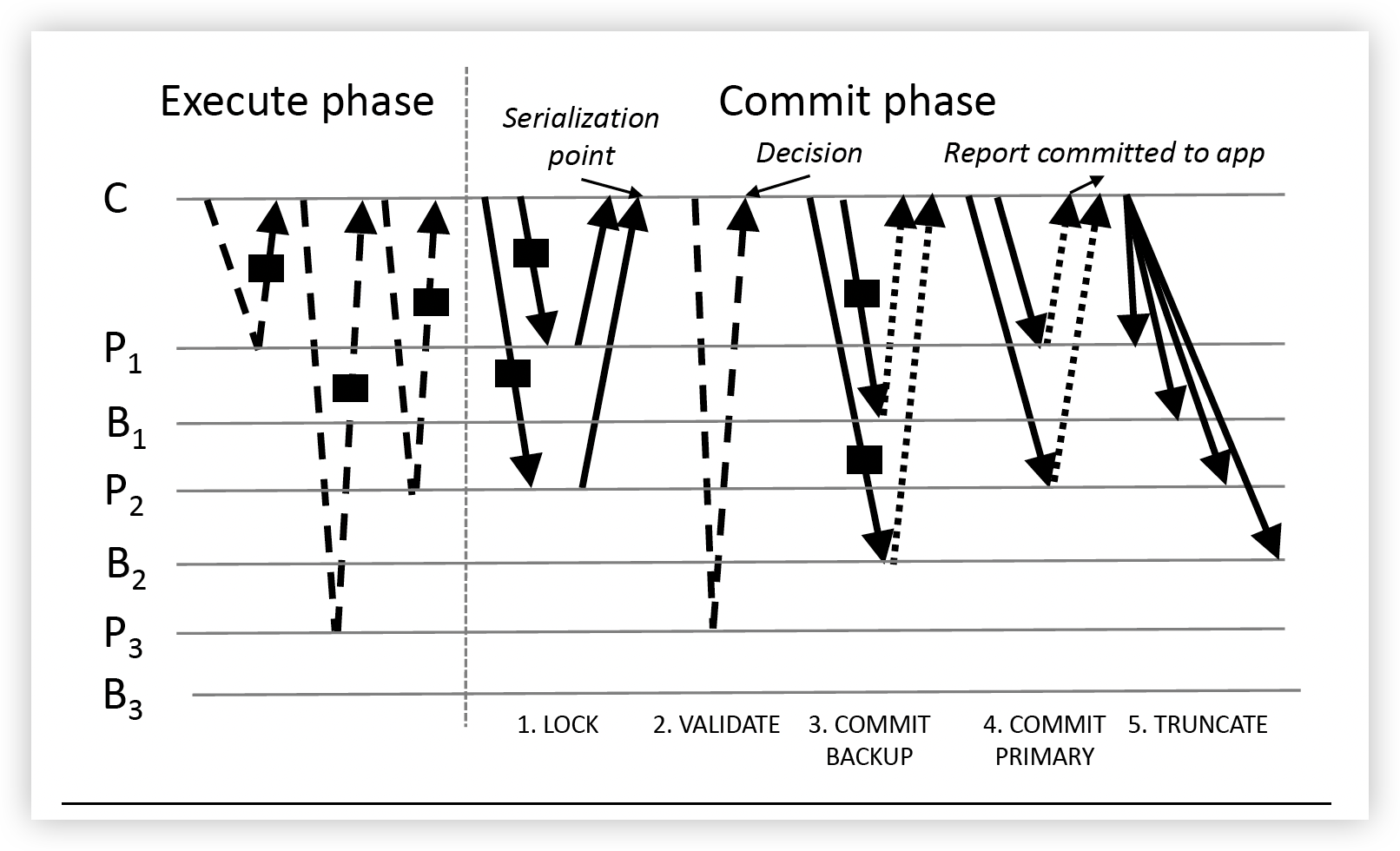 先忽略Commit 阶段的VALIDATE阶段和COMMIT BACKUP阶段
该步骤除了进行replication以外,还实现了事务的有序执行
先忽略Commit 阶段的VALIDATE阶段和COMMIT BACKUP阶段
该步骤除了进行replication以外,还实现了事务的有序执行 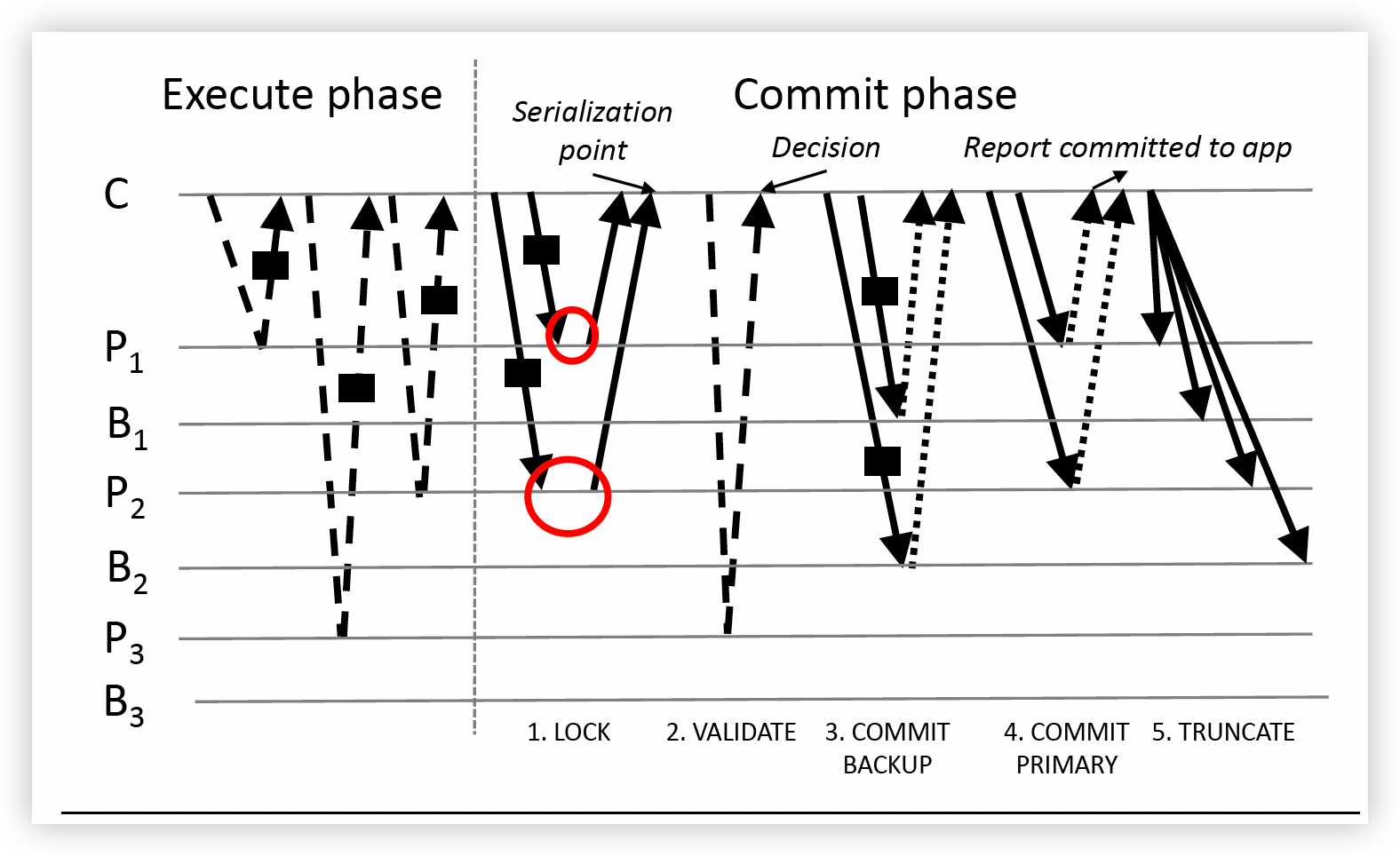
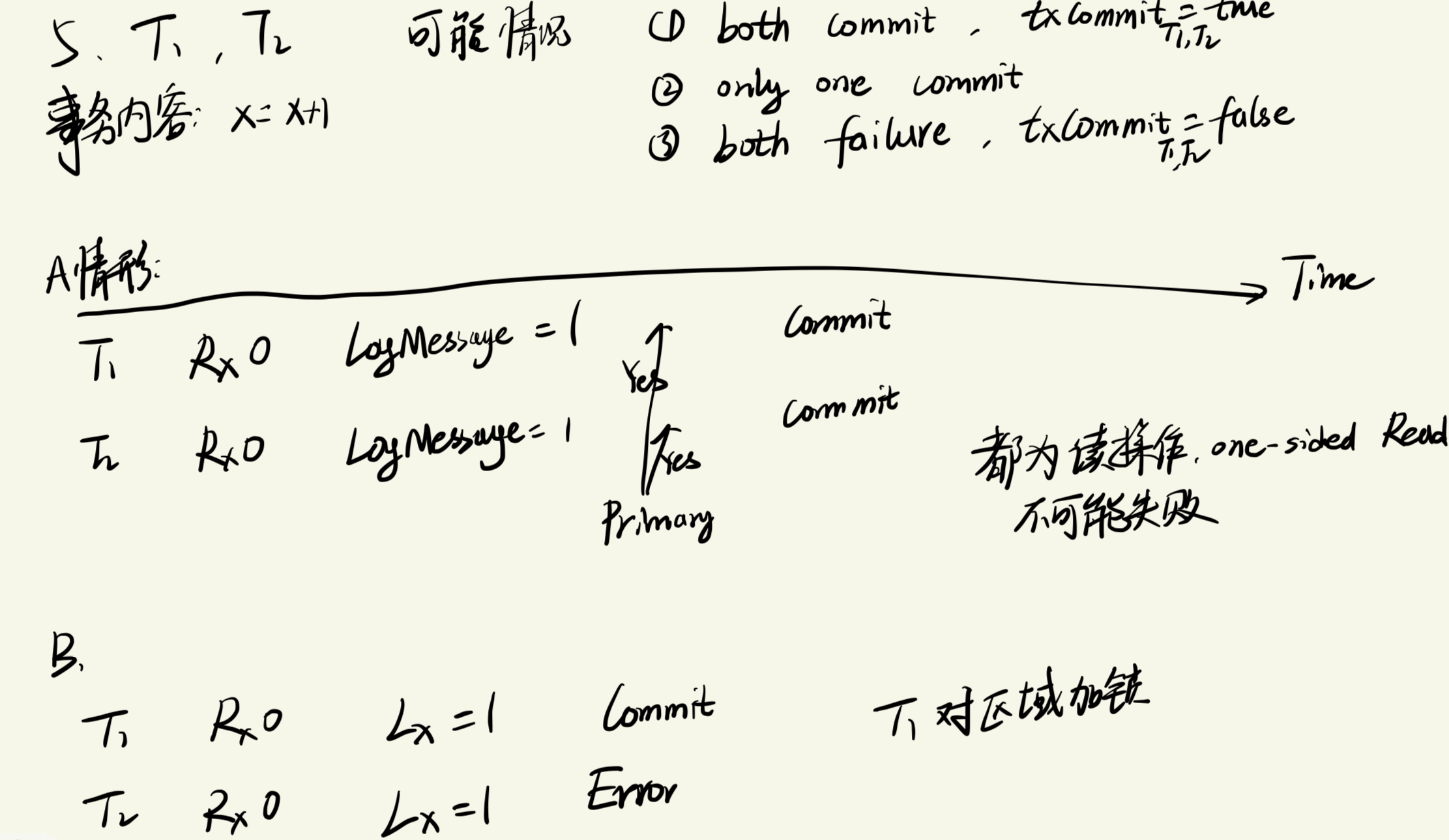

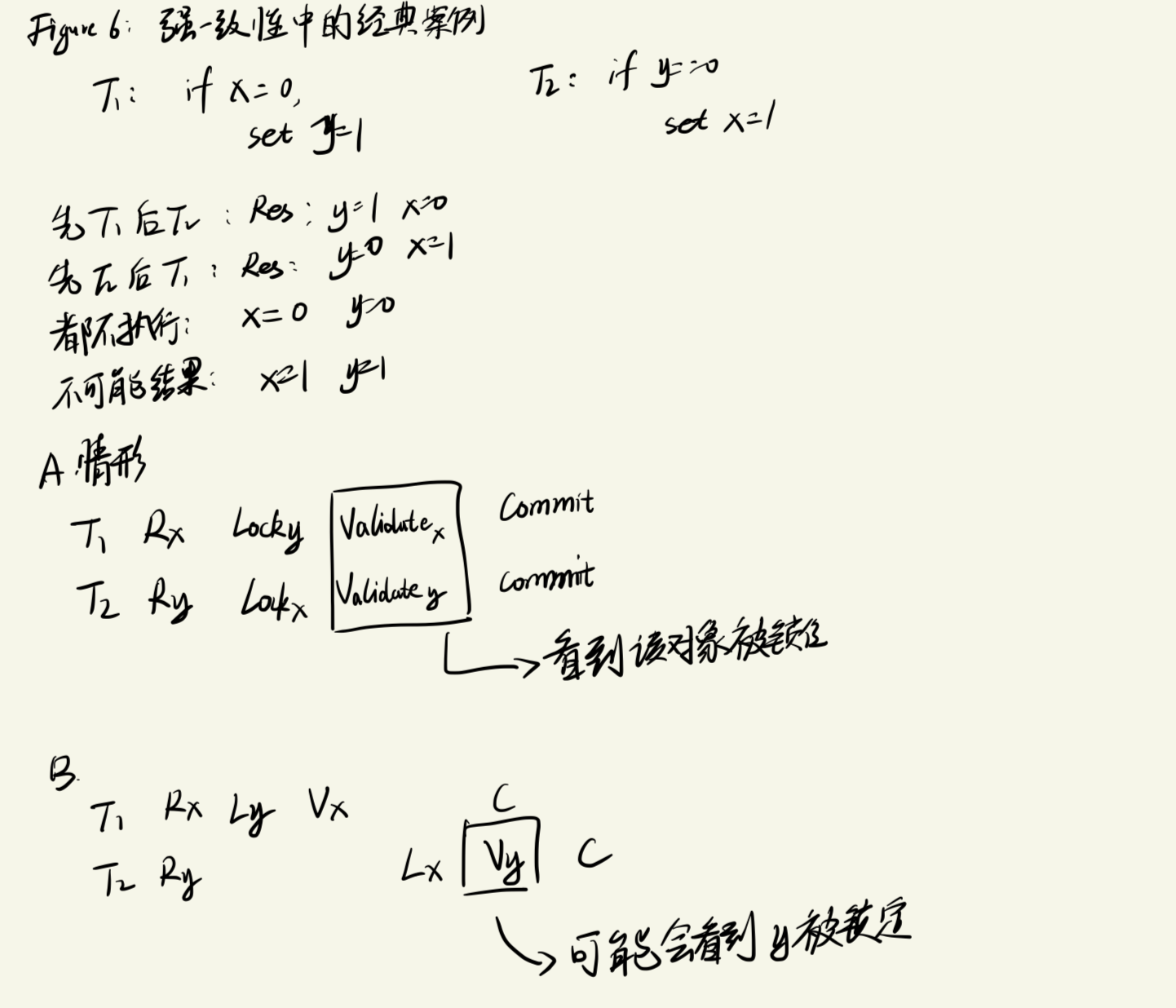
FaRM是微软自己现如今(2015)用来实验的系统:使用RDMA的硬件技术,实现对内存中数据的高速访问,并通过乐观并发控制的办法,避免事务冲突