 KTurnura
commented
5 months ago
KTurnura
commented
5 months ago 实际应用场景:基于RDD实现的Spark被认为是Mapreduce的一种演进。相较于Mapreduce将中间文件写入磁盘中,Spark将数据放在内存中,并将Mapreduce的两部分总结为多步骤数据流图(DAG)。极大的提高了分布式并行计算的速度。
-
方法:使用内存存放数据
解决:读取中间数据过慢的问题
-
方法:lineage
解决:当某个节点故障后,可以根据lineage推断某个RDD的来源,重做该数据(宽依赖情况后面讨论)即可恢复该节点数据

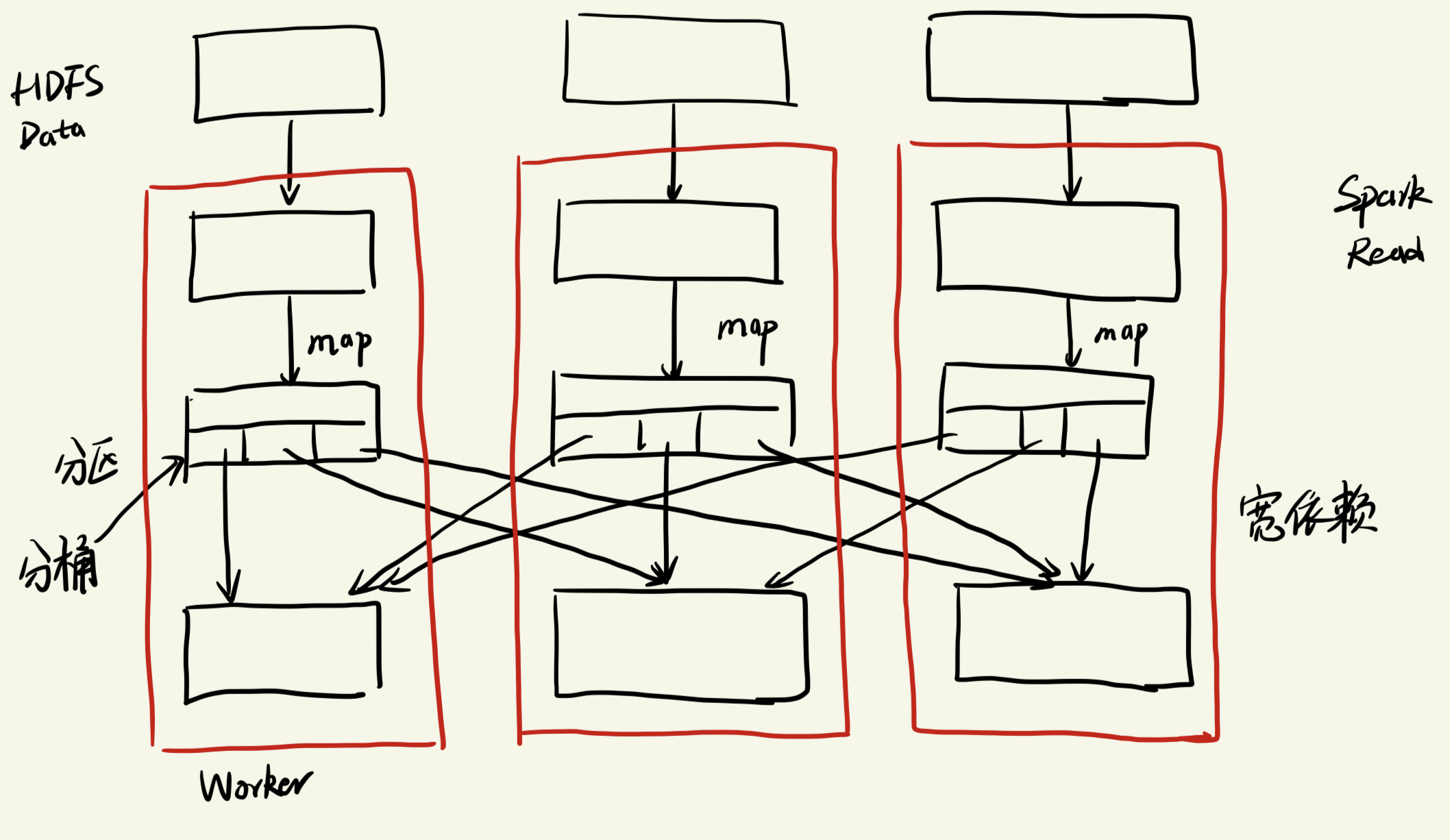
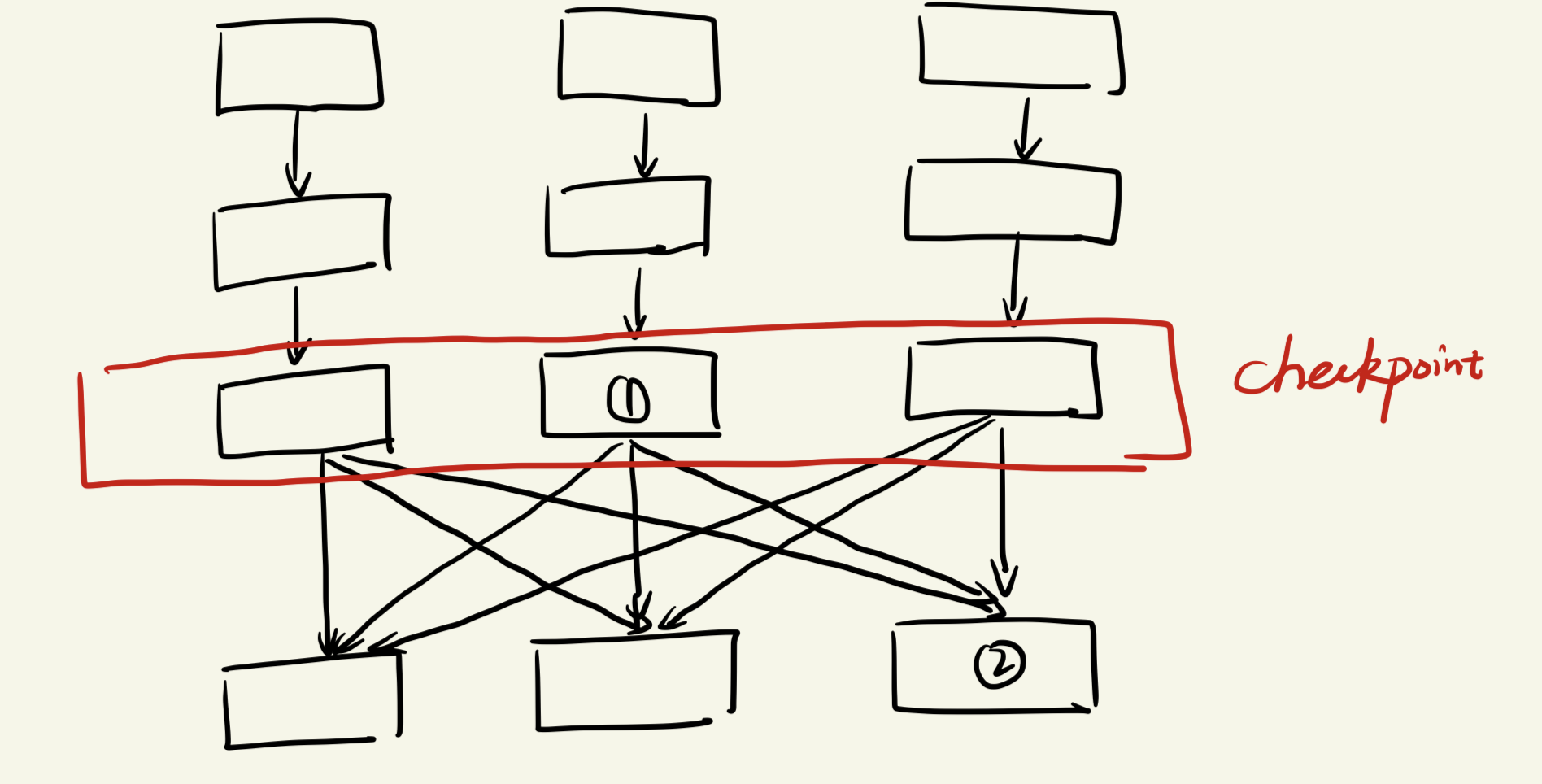
本论文介绍了RDD的基本概念,介绍了RDD中最重要的Lineage 概念,可以通过Lineage 结合Checkpoint 实现快速容错恢复。使用RDD实现了PageRank算法和逻辑回归算法,介绍了宽依赖和窄依赖的概念。