Open KTurnura opened 2 weeks ago
一篇2022年的浙江大学硕士毕业论文 主要针对的是时空流,使用LSM Tree + 八叉树构建时空树,同时使用LSM-OCTree的优点来构建索引
一、研究背景 二、数据流的分布式时空调度策略 三、 时空流的分布式存储策略 四、性能验证 五、总结展望
这里主要提到的是LSM Tree 时空数据有时候需要即席查询 但是时空瓦片存储应该不需要即席查询,有时候可以通过减缓实时反馈等优势来构建自己的系统
这里提到了很多基于HDFS等已有分布式存储数据库来构建时空数据存储系统的
也有使用Hbase 来索引时空数据,但是HBase 不适合实时数据处理,但是适合遥感影像,同时可以设计二级空间索引来加快非主键属性的高效查询
时空流的数据记录至少包含记录 ID、经度、纬度和时间戳 通常可以使用 ID、经度、纬度 来构成Key键 本章利用监控与反馈机制对输入数据流进行动态均匀划分
流数据分区中数据分区的目的是将数据和查询均匀的分布到集群各个节点上
就选Hilbert
如果集群 各节点的数据之间存在依赖关系,时空查询时就需要通过昂贵的网络通信进行交互。
由于时空流数据具有时空分布的特性,可将时空流划分为独立的时空子域,充分利用集群的并行度进行处理。通常来说,各时空子域中的计算互不影响。例如,在进行时空查询时,涉及到查询的数据均位于本地时空子域,不需要通过网络或磁盘进行数据交互。根据底层存储模式的不同,于以利用不同的时空数据划分策略生成时空子域」问时,划分的粒度需要考虑任务并行度,根据集群计算能力和计算任务空间范围确定时空子域的划分粒度,在减少子任务数据交互的同时控制子任务数量,从而充分利用多节点多核的计算资源。
因此,针欢时空流的无界性, 首先设计时间分片的概念完成时间域划分。在时间分片的基础上,再基于时空流空间属性完成空间域到分,形成完整的时空子域划分方法。时空子域是通过数据划分策咯形成的时空流子集合,也是各节点处理流数据以及存储的基本单元,是数据调度及查询调度的基础。
其实就是编码方式
基于时空子域可形成时空流的时空调度方法。时空调度是指在分布式集群下时空流及时空查询根据时空子域调度至指定节点处理。在数据分发时,先基于时间维度分片,再计算流入时空数据的 Hilbert 值,并按照并行度不断分发至各节点,各节点将形成基于时间域和空间域划分的独立时空子域。如图2.6 所示,通过将时空域分别划分,首先形成多个时空单元(ST Cell),时间单元 (Time Cell)表示时间维度的划分,空间单元(Space Cell)表示空间维度的划分。单位时间分片内,通过 Hilbert 曲线及空间并行粒度聚合多个邻近时空单元,形成独立的时空子域(ST Suyhdomoin 在实际应用中可按照应用需求及服务器运算能力控制划分粒度的精细程度。
基于这种数据分发方式,时空查询任务通常只查询本地时空子域。然而,如果空间划分较细或查询空问范围较大时,时空查询任务将覆盖多个节点存储的数据。因此,还需要实现时空查询的并行化: 如图 2.7 所示,黑色流程表示流数据存储的调度流程,蓝色流程表示时空查询的调度流程。时空查询的步骤包含查询的时空划分、子任务的分发调度、子任务的执行、查询结果的合并四个过程。首先将时空查询划分为多个独立子任务再调度至不同的节点,各节点将分别处理位于不同时空子域的任务,最后将计算结果合并。因此,流数据首先基于时空子域进行存储,而时空查询任务只需访问一个或多个相关时空子域即可,从而提升查询效率。
需要抽样算法来大致了解流数据的空间分布(然而,时空流具有无界性与实时性,同时计算机内存也是有限的,流入的数据无法全部存储至内存再进行排序计算
使用水库抽样算法保证每个样本元素被抽中的概率相同
然而,时空流具有无界性与实时性,同时计算机内存也是有限的,流入的数据无法全部存储至内存再进行排序计算,因此需要一种抽样算法来大致了解流数本文针对每个时间分片,首先利用 Hilbert 曲线将时空数据的空间位置映射为一维数值,再使用水库抽样算法对输入时空流进行持续采样。在采样的基础上,对样本数据按照 Hilbert 曲线的值进行排序,最后根据草点数量来确定数据的划分。通过这种方式,可大致了解每个时间分片的数据空间分布,并生成均匀的空间域划分。
抽样之后,可了解单独某一次进入的时间流的所在空间域位置
时空子域的划分减少了时空查询时集群各节点之间的数据交互,但是由于流的无界性,流入数据的时空分布可能随时会发生改变,无法时刻保证每个节点之间的任务量均衡。当一个节点处理的任务量增多,造成热点问题,影响总体处理效率。
在LSM 树实现思想的基础上,针对时空流的索引实时更新问题,结合内外存索引和时空索引,提出了LSM-OCTree 分层索引结构,兼顾时空数据的更新和查询效率
首先根据时空范围构建八叉树,再进行八叉树的预分区,以时空立方体为单位进行数据处理
LSM 在内存索引树中经常使用AVL树或者红黑树结构,磁盘树多使用磁盘存储的类B+树结构, 由于内存有限,当Co树包含的数据量达到阈值时,需要及时将 Co 树的部分数据合并至C1树。LSM 树通过滚动合并的方式将内存中的数据合并至磁盘
如果C0树和C1树合并过程中,C1中的磁盘快被称为清空块,合并之后新节点写入的磁盘块称为填充快。新节点不覆盖 C1树的旧“清空块’,而是顺序写入磁盘中的空闲区域即“填充块”。待新节点数据写入完成,再删除原始“清空•”中的数据。这种设计的好处在于,如果在写数据的过程中服务器出现宕机,可以通过原有数据块进行数据恢复,提高服务的容灾性能。 与插入操作相同,LSM 树的修改与删除操作并不直接作用于磁盘中的数据,而是通过内存来延迟和批处理。
面向带有空问属性的数据.键值炎据库通学利用 Geohash 等手段将空间属性一维化,再将 Geohash 编码与数据ID 作为主键按序存储。拓展至三维时空域后,通常以时间属性与 Geohash 编码共同构成时空编码,较难实现高效的范围查询。
由此可知,基于 LSM树的分布式存储系统利用内存延迟和批量顺序写磁盘,可以极大地提高写入能力,并通过不断的合并以及布隆过滤器等手段来保持良好的读性能。但 HBase 等键值数据库面向海量高速时空流无法兼顾索引更新效率与时空查询效率。
八叉树索引是一种典型的时空区域层级划分索引,其基本划分原理为对空间二维进行四叉树划分,对时间维度进行二叉树划分,从而将整个时空进行八叉树递归划分。
如果某个子空间中的数据量达到國值,则需要将该子空间划分至更深的层级。以二维空间的四叉树索引为例,图3.5所示为四叉树的空间划分方法与对应的树状结构。
通过递归不断将空间范围划分为四象限,各层级的格网形成树形关联索引,空间对象将存于各层的叶子节点中。相较于格网索引,四叉树索引可根据数据的空间分布调整层级,平衡各格网数据容量,增强检索的剪枝能力个叉树将空问和时问维度结合,形成三维数据空间,利用相同的方法将时空范围递归划分为时空立方体。
八叉树的优势在于结构简单,构建方法简便,使用 见则立方体直接索引数据,并且各叶节点是不相交、不重叠的,因此数据的插入和查询效率都较高。当数据分布均匀时, 八叉树中的子空间包含数据量相当;如果分布不均,为保证各子空间的数据均衡,需要进行不断的划分,可能存在层级过深的问题。因此,在构建八叉树索引时需要在深度及叶节点容量之间寻找平衡点。
创新点 由于时空数据规模庞大,传统的八叉树家引存放在磁盘中。数据插入时需要通过多次磁盘读写搜索待插入叶结点,再对索引进行更新。如果叶结点包含数据超过一定容量,就需要分裂该节点再调整其中的数据,将产生大量磁盘读写,导致数据插入效率大大降低。面向连续快速增长的时空数据流,常规八叉树的插入能力明显不足。LSM 树结合内存索引与磁货索引,只在内存中进行数据插入和索引更新,减少了磁盘读写的开销,能够实现数据的即时索引。
空间范围以经纬度为界限,时间域是无限的,时间范围可以按照需求定义
由于八叉树的数据节点互不相交、重叠,针对LSM 树的特点,LSM-OCTree采用预先分区的方式,先将八叉树划分至一定层级形成多个时空立方体,数据将插入在该层级节点及其子节点中,在内存中以预分区层级的叶结点为单位进行数据处理并特久化。为了保持 LSM-OCTree 中每块数据的时空邻近性,将预分区后八叉树中的一个或多个邻近时空立方体作为数据块单位。预分区的深度通常取决于预设时空立方体大小。划分深度需要顾及单位时间的长度,必须控制时空立方体的数据在一个范围内,从而减少后续所需的合并次数。同时也要顾及到时空立方体中的数据量,減少内存中时空索引的复杂度以及所占内存大小。因此需要根据实际需求确定划分的深度。
同时设置八叉树的自动分裂设置次数上限,放置八叉树深度过深,影响访问效率
常规的 LSM 树在进行时空查询时,必须对磁益上的每一层的每一个索引文件进行查询,并将结果进行合并输出。虽然 LSM-OCTree 通过时间索引可首先筛选相应的索引文件。但大范围的时空查询需要扫描的文件过多,影响查询效率。因此,LSM 树需要合并数据块,减少索引文件数量,以保持高效的查询性能。但LSM 树的合并会占用部分系统资源,影响此期间的系统性能,降低数据插入和查询的效率。为减少合并对系统整体性能的影响,需要实现高效的合并算法。
本章节是介绍在分布式中如何进行索引,同时设计Rebalance ,防止高负载节点的索引树压力过大
面向海量、高速时空流,时空索引不仅需要提供快速更新能力,保证数据在到达时进行快速处理,更重要的是需要具备良好的检索性能。LSM-OCTree 基于时空八叉树,通过判断 MBC 与各层级时空网格的交集进行范围查询,能够支持时空数据的快速检索。同时,LSM 树面向索引的快速更新,适合高速时空流的实时插入。因此,LSM-OCTree 适用于快速增长时空流的高效存储与查询。
使用数据增量来对数据节点进行调整
根据时空流的特性及LSM-OCTree 的特点,本节基于分布式 LSM-OCTree索引结构,利用时间分片将时空流进行切分,单个节点针对每个时空子域构建内存八叉树,并不断合并磁盘中多个八叉树索引提高整体查询性能。
图3.10 面向时问分片的时空流实时存储过程。如图所示,wi、w..•、Wkl、Wk表示时间分片,Co、C、⋯、CI 表示 LSM 树的每一层,Co 位于内存,Cl至Cn位于磁盘。整个过程包括以下四步。
四、性能验证 五、总结展望
一篇2022年的浙江大学硕士毕业论文 主要针对的是时空流,使用LSM Tree + 八叉树构建时空树,同时使用LSM-OCTree的优点来构建索引
结构
一、研究背景 二、数据流的分布式时空调度策略 三、 时空流的分布式存储策略 四、性能验证 五、总结展望
一、研究背景
这里主要提到的是LSM Tree 时空数据有时候需要即席查询 但是时空瓦片存储应该不需要即席查询,有时候可以通过减缓实时反馈等优势来构建自己的系统
这里提到了很多基于HDFS等已有分布式存储数据库来构建时空数据存储系统的
也有使用Hbase 来索引时空数据,但是HBase 不适合实时数据处理,但是适合遥感影像,同时可以设计二级空间索引来加快非主键属性的高效查询
本文内容
二、数据流的分布式时空调度策略
时空流的数据记录至少包含记录 ID、经度、纬度和时间戳 通常可以使用 ID、经度、纬度 来构成Key键 本章利用监控与反馈机制对输入数据流进行动态均匀划分
流数据
流数据分区和调度
流数据分区中数据分区的目的是将数据和查询均匀的分布到集群各个节点上
时空流处理的时空维度优化
空间ID编码方式
就选Hilbert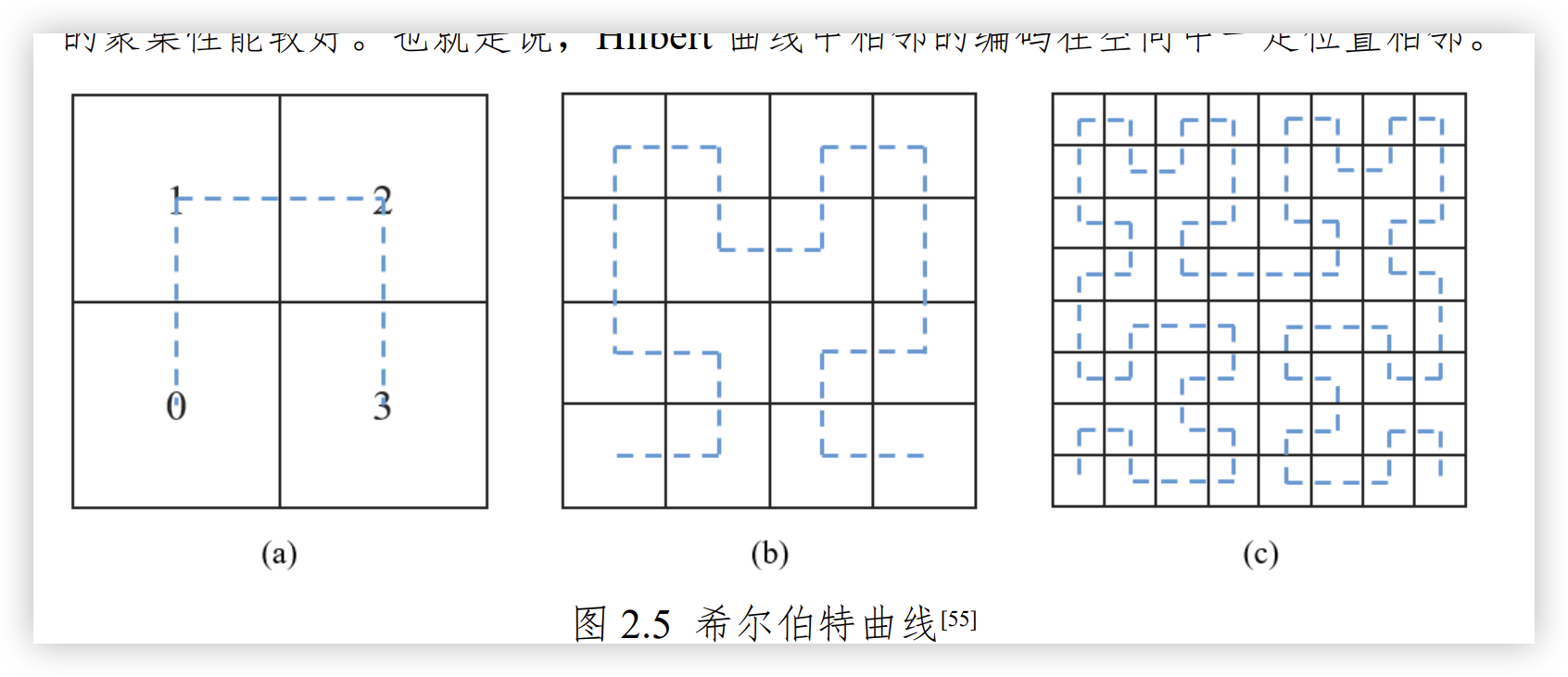
基于时空子域划分策略的时空流加速
如果集群 各节点的数据之间存在依赖关系,时空查询时就需要通过昂贵的网络通信进行交互。
由于时空流数据具有时空分布的特性,可将时空流划分为独立的时空子域,充分利用集群的并行度进行处理。通常来说,各时空子域中的计算互不影响。例如,在进行时空查询时,涉及到查询的数据均位于本地时空子域,不需要通过网络或磁盘进行数据交互。根据底层存储模式的不同,于以利用不同的时空数据划分策略生成时空子域」问时,划分的粒度需要考虑任务并行度,根据集群计算能力和计算任务空间范围确定时空子域的划分粒度,在减少子任务数据交互的同时控制子任务数量,从而充分利用多节点多核的计算资源。
因此,针欢时空流的无界性, 首先设计时间分片的概念完成时间域划分。在时间分片的基础上,再基于时空流空间属性完成空间域到分,形成完整的时空子域划分方法。时空子域是通过数据划分策咯形成的时空流子集合,也是各节点处理流数据以及存储的基本单元,是数据调度及查询调度的基础。
基于时空子域可形成时空流的时空调度方法。时空调度是指在分布式集群下时空流及时空查询根据时空子域调度至指定节点处理。在数据分发时,先基于时间维度分片,再计算流入时空数据的 Hilbert 值,并按照并行度不断分发至各节点,各节点将形成基于时间域和空间域划分的独立时空子域。如图2.6 所示,通过将时空域分别划分,首先形成多个时空单元(ST Cell),时间单元 (Time Cell)表示时间维度的划分,空间单元(Space Cell)表示空间维度的划分。单位时间分片内,通过 Hilbert 曲线及空间并行粒度聚合多个邻近时空单元,形成独立的时空子域(ST Suyhdomoin 在实际应用中可按照应用需求及服务器运算能力控制划分粒度的精细程度。
基于这种数据分发方式,时空查询任务通常只查询本地时空子域。然而,如果空间划分较细或查询空问范围较大时,时空查询任务将覆盖多个节点存储的数据。因此,还需要实现时空查询的并行化: 如图 2.7 所示,黑色流程表示流数据存储的调度流程,蓝色流程表示时空查询的调度流程。时空查询的步骤包含查询的时空划分、子任务的分发调度、子任务的执行、查询结果的合并四个过程。首先将时空查询划分为多个独立子任务再调度至不同的节点,各节点将分别处理位于不同时空子域的任务,最后将计算结果合并。因此,流数据首先基于时空子域进行存储,而时空查询任务只需访问一个或多个相关时空子域即可,从而提升查询效率。
2.3 时空流调度策略优化
基于时空子域的时空流分发
需要抽样算法来大致了解流数据的空间分布(然而,时空流具有无界性与实时性,同时计算机内存也是有限的,流入的数据无法全部存储至内存再进行排序计算
使用水库抽样算法保证每个样本元素被抽中的概率相同
然而,时空流具有无界性与实时性,同时计算机内存也是有限的,流入的数据无法全部存储至内存再进行排序计算,因此需要一种抽样算法来大致了解流数本文针对每个时间分片,首先利用 Hilbert 曲线将时空数据的空间位置映射为一维数值,再使用水库抽样算法对输入时空流进行持续采样。在采样的基础上,对样本数据按照 Hilbert 曲线的值进行排序,最后根据草点数量来确定数据的划分。通过这种方式,可大致了解每个时间分片的数据空间分布,并生成均匀的空间域划分。
抽样之后,可了解单独某一次进入的时间流的所在空间域位置
2.3.2 基于时间分片抽样的动态时空调度
时空子域的划分减少了时空查询时集群各节点之间的数据交互,但是由于流的无界性,流入数据的时空分布可能随时会发生改变,无法时刻保证每个节点之间的任务量均衡。当一个节点处理的任务量增多,造成热点问题,影响总体处理效率。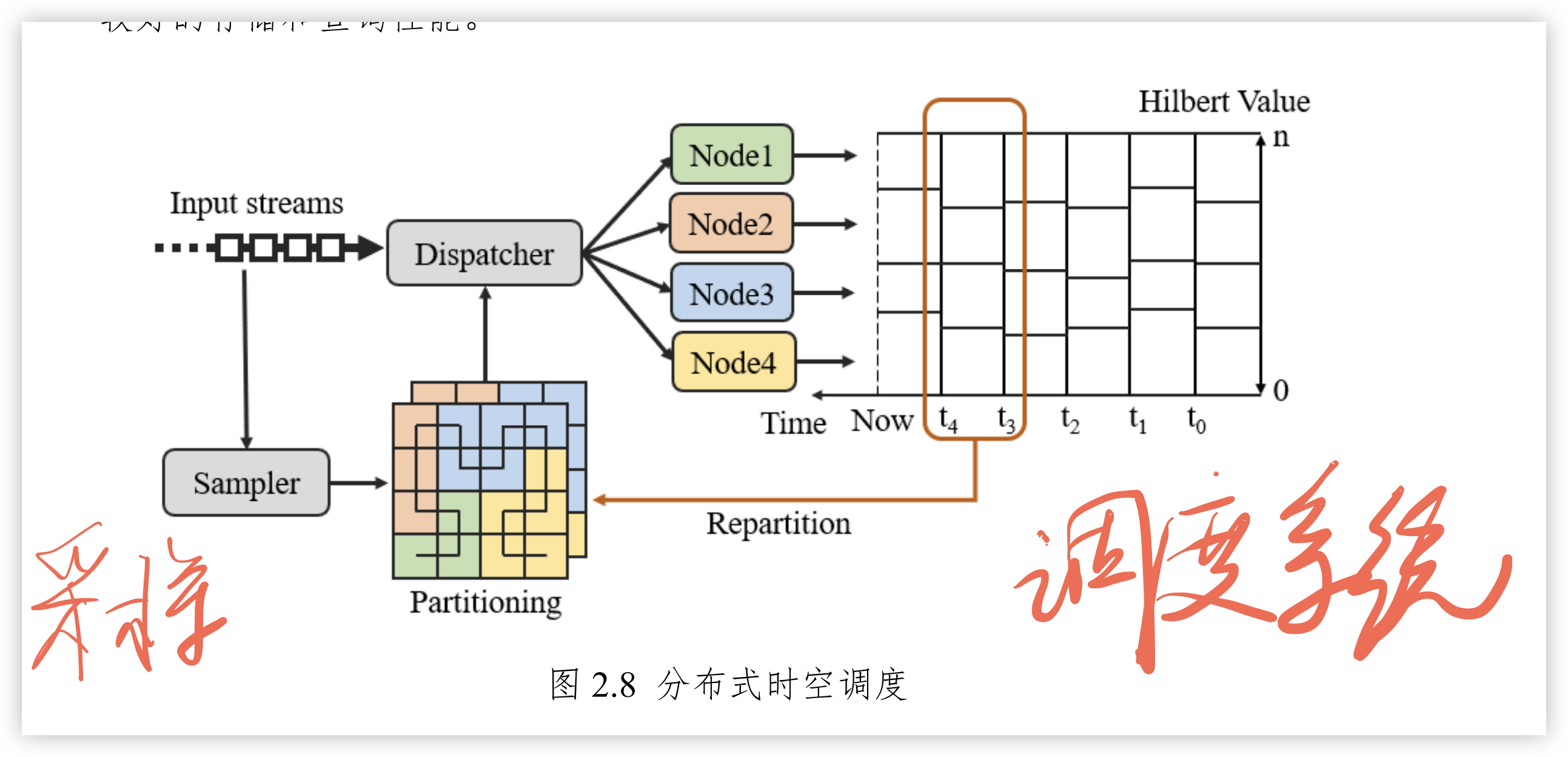
三、 时空流的分布式存储策略
在LSM 树实现思想的基础上,针对时空流的索引实时更新问题,结合内外存索引和时空索引,提出了LSM-OCTree 分层索引结构,兼顾时空数据的更新和查询效率
3.1 结合LSM 树的时空索引
首先根据时空范围构建八叉树,再进行八叉树的预分区,以时空立方体为单位进行数据处理
3.1.1 LSM 树结构与时空增强
LSM 在内存索引树中经常使用AVL树或者红黑树结构,磁盘树多使用磁盘存储的类B+树结构, 由于内存有限,当Co树包含的数据量达到阈值时,需要及时将 Co 树的部分数据合并至C1树。LSM 树通过滚动合并的方式将内存中的数据合并至磁盘
如果C0树和C1树合并过程中,C1中的磁盘快被称为清空块,合并之后新节点写入的磁盘块称为填充快。新节点不覆盖 C1树的旧“清空块’,而是顺序写入磁盘中的空闲区域即“填充块”。待新节点数据写入完成,再删除原始“清空•”中的数据。这种设计的好处在于,如果在写数据的过程中服务器出现宕机,可以通过原有数据块进行数据恢复,提高服务的容灾性能。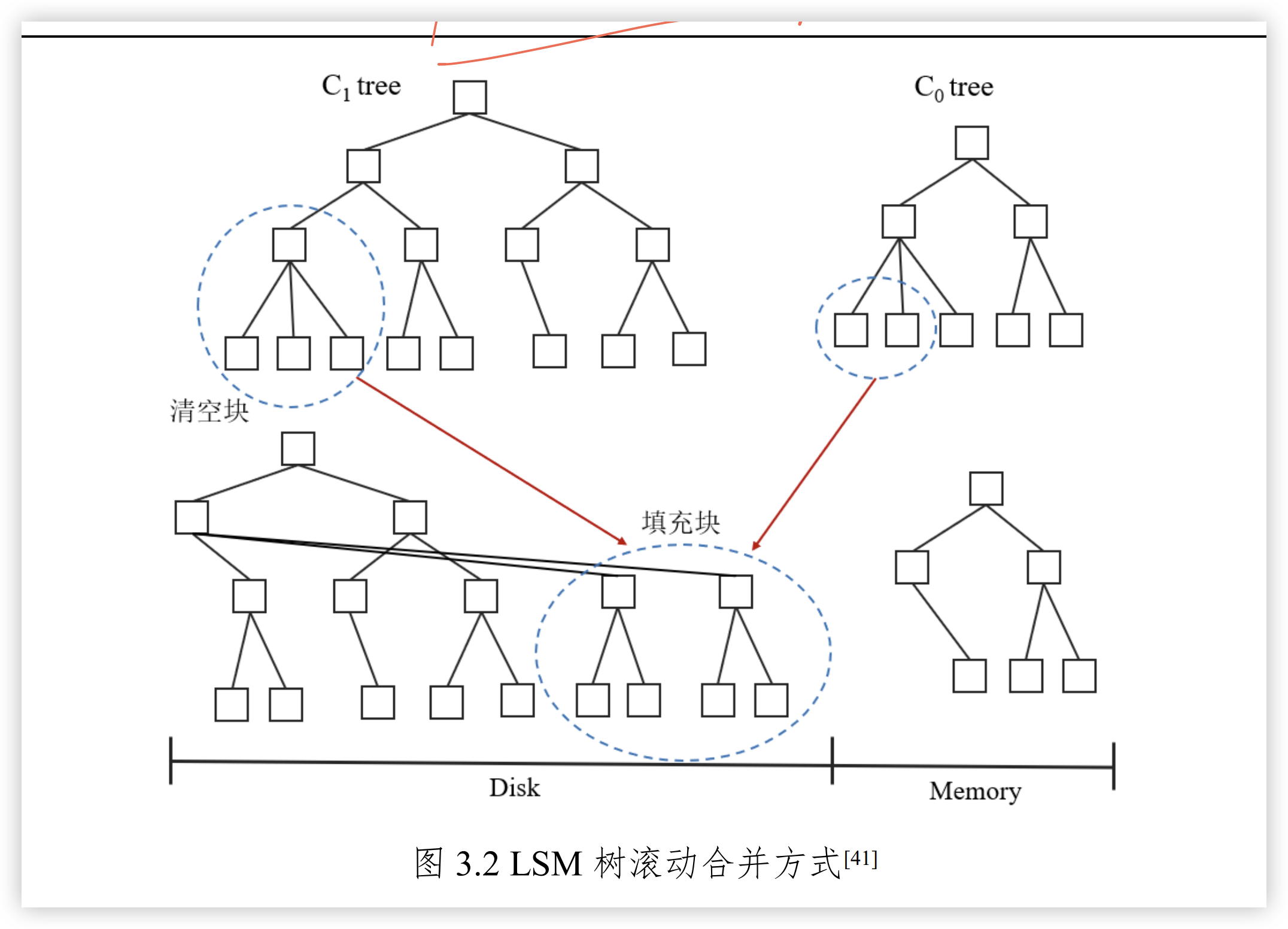 与插入操作相同,LSM 树的修改与删除操作并不直接作用于磁盘中的数据,而是通过内存来延迟和批处理。
与插入操作相同,LSM 树的修改与删除操作并不直接作用于磁盘中的数据,而是通过内存来延迟和批处理。
面向带有空问属性的数据.键值炎据库通学利用 Geohash 等手段将空间属性一维化,再将 Geohash 编码与数据ID 作为主键按序存储。拓展至三维时空域后,通常以时间属性与 Geohash 编码共同构成时空编码,较难实现高效的范围查询。
由此可知,基于 LSM树的分布式存储系统利用内存延迟和批量顺序写磁盘,可以极大地提高写入能力,并通过不断的合并以及布隆过滤器等手段来保持良好的读性能。但 HBase 等键值数据库面向海量高速时空流无法兼顾索引更新效率与时空查询效率。
3.1.2 传统时空索引原理
八叉树索引是一种典型的时空区域层级划分索引,其基本划分原理为对空间二维进行四叉树划分,对时间维度进行二叉树划分,从而将整个时空进行八叉树递归划分。
如果某个子空间中的数据量达到國值,则需要将该子空间划分至更深的层级。以二维空间的四叉树索引为例,图3.5所示为四叉树的空间划分方法与对应的树状结构。
通过递归不断将空间范围划分为四象限,各层级的格网形成树形关联索引,空间对象将存于各层的叶子节点中。相较于格网索引,四叉树索引可根据数据的空间分布调整层级,平衡各格网数据容量,增强检索的剪枝能力个叉树将空问和时问维度结合,形成三维数据空间,利用相同的方法将时空范围递归划分为时空立方体。
八叉树的优势在于结构简单,构建方法简便,使用 见则立方体直接索引数据,并且各叶节点是不相交、不重叠的,因此数据的插入和查询效率都较高。当数据分布均匀时, 八叉树中的子空间包含数据量相当;如果分布不均,为保证各子空间的数据均衡,需要进行不断的划分,可能存在层级过深的问题。因此,在构建八叉树索引时需要在深度及叶节点容量之间寻找平衡点。
创新点 由于时空数据规模庞大,传统的八叉树家引存放在磁盘中。数据插入时需要通过多次磁盘读写搜索待插入叶结点,再对索引进行更新。如果叶结点包含数据超过一定容量,就需要分裂该节点再调整其中的数据,将产生大量磁盘读写,导致数据插入效率大大降低。面向连续快速增长的时空数据流,常规八叉树的插入能力明显不足。LSM 树结合内存索引与磁货索引,只在内存中进行数据插入和索引更新,减少了磁盘读写的开销,能够实现数据的即时索引。
3.1.3 LSM-OCTree 原理与实现
空间范围以经纬度为界限,时间域是无限的,时间范围可以按照需求定义
由于八叉树的数据节点互不相交、重叠,针对LSM 树的特点,LSM-OCTree采用预先分区的方式,先将八叉树划分至一定层级形成多个时空立方体,数据将插入在该层级节点及其子节点中,在内存中以预分区层级的叶结点为单位进行数据处理并特久化。为了保持 LSM-OCTree 中每块数据的时空邻近性,将预分区后八叉树中的一个或多个邻近时空立方体作为数据块单位。预分区的深度通常取决于预设时空立方体大小。划分深度需要顾及单位时间的长度,必须控制时空立方体的数据在一个范围内,从而减少后续所需的合并次数。同时也要顾及到时空立方体中的数据量,減少内存中时空索引的复杂度以及所占内存大小。因此需要根据实际需求确定划分的深度。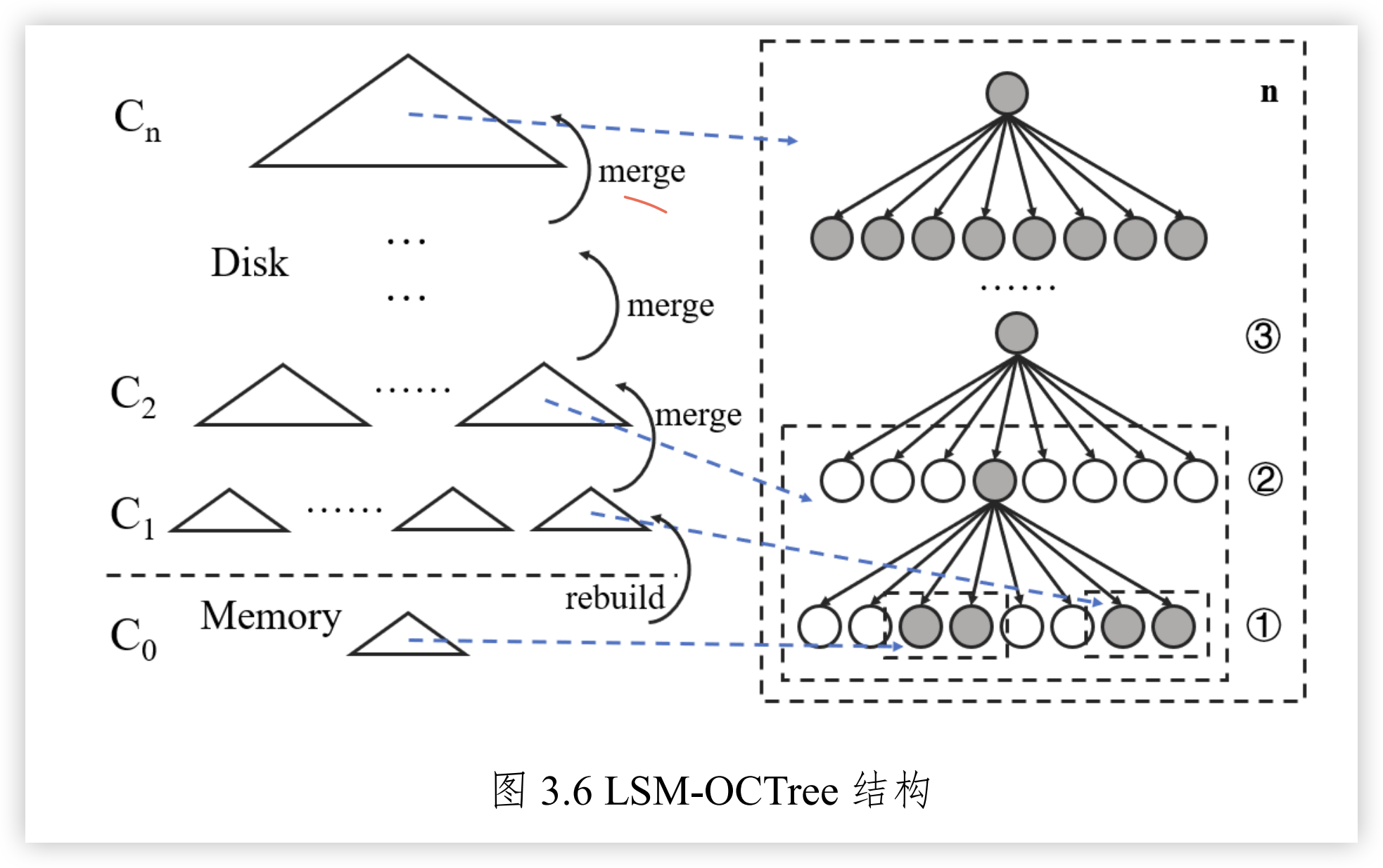
同时设置八叉树的自动分裂设置次数上限,放置八叉树深度过深,影响访问效率
3.1.4 LSM-OC Tree 索引基础时空操作
3.1.5 LSM-OC Tree 索引高效增量合并方法
常规的 LSM 树在进行时空查询时,必须对磁益上的每一层的每一个索引文件进行查询,并将结果进行合并输出。虽然 LSM-OCTree 通过时间索引可首先筛选相应的索引文件。但大范围的时空查询需要扫描的文件过多,影响查询效率。因此,LSM 树需要合并数据块,减少索引文件数量,以保持高效的查询性能。但LSM 树的合并会占用部分系统资源,影响此期间的系统性能,降低数据插入和查询的效率。为减少合并对系统整体性能的影响,需要实现高效的合并算法。
3.2 估计时空调度优化的时空流分布式实时索引(大概从这儿开始迷糊的)
3.2.1 基于LSM-OCTree的分布式索引结构
本章节是介绍在分布式中如何进行索引,同时设计Rebalance ,防止高负载节点的索引树压力过大
面向海量、高速时空流,时空索引不仅需要提供快速更新能力,保证数据在到达时进行快速处理,更重要的是需要具备良好的检索性能。LSM-OCTree 基于时空八叉树,通过判断 MBC 与各层级时空网格的交集进行范围查询,能够支持时空数据的快速检索。同时,LSM 树面向索引的快速更新,适合高速时空流的实时插入。因此,LSM-OCTree 适用于快速增长时空流的高效存储与查询。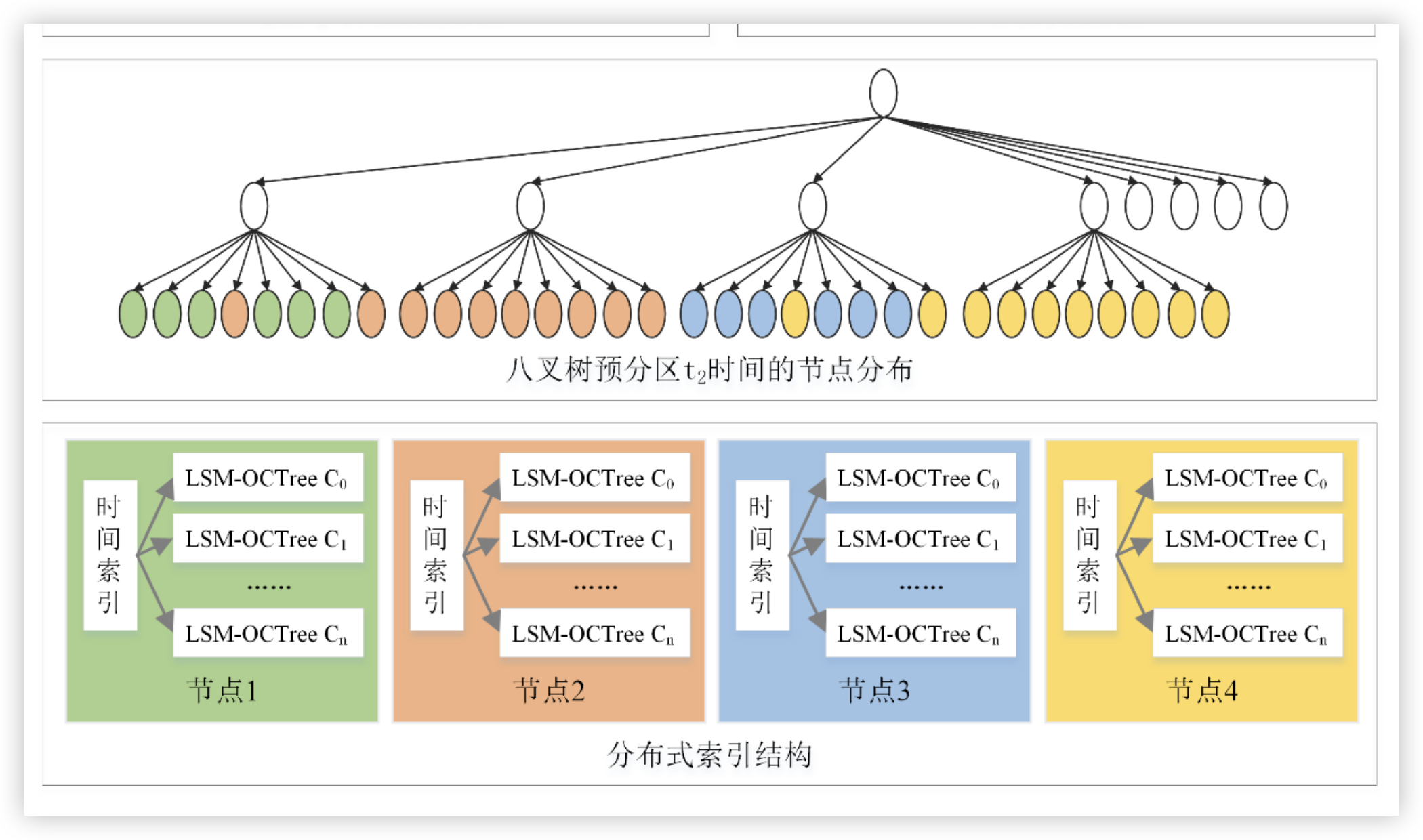
3.2.2 动态时空调度下的时空子域增量合并
使用数据增量来对数据节点进行调整
3.2.3 基于时间分片的时空流存储流程
根据时空流的特性及LSM-OCTree 的特点,本节基于分布式 LSM-OCTree索引结构,利用时间分片将时空流进行切分,单个节点针对每个时空子域构建内存八叉树,并不断合并磁盘中多个八叉树索引提高整体查询性能。
图3.10 面向时问分片的时空流实时存储过程。如图所示,wi、w..•、Wkl、Wk表示时间分片,Co、C、⋯、CI 表示 LSM 树的每一层,Co 位于内存,Cl至Cn位于磁盘。整个过程包括以下四步。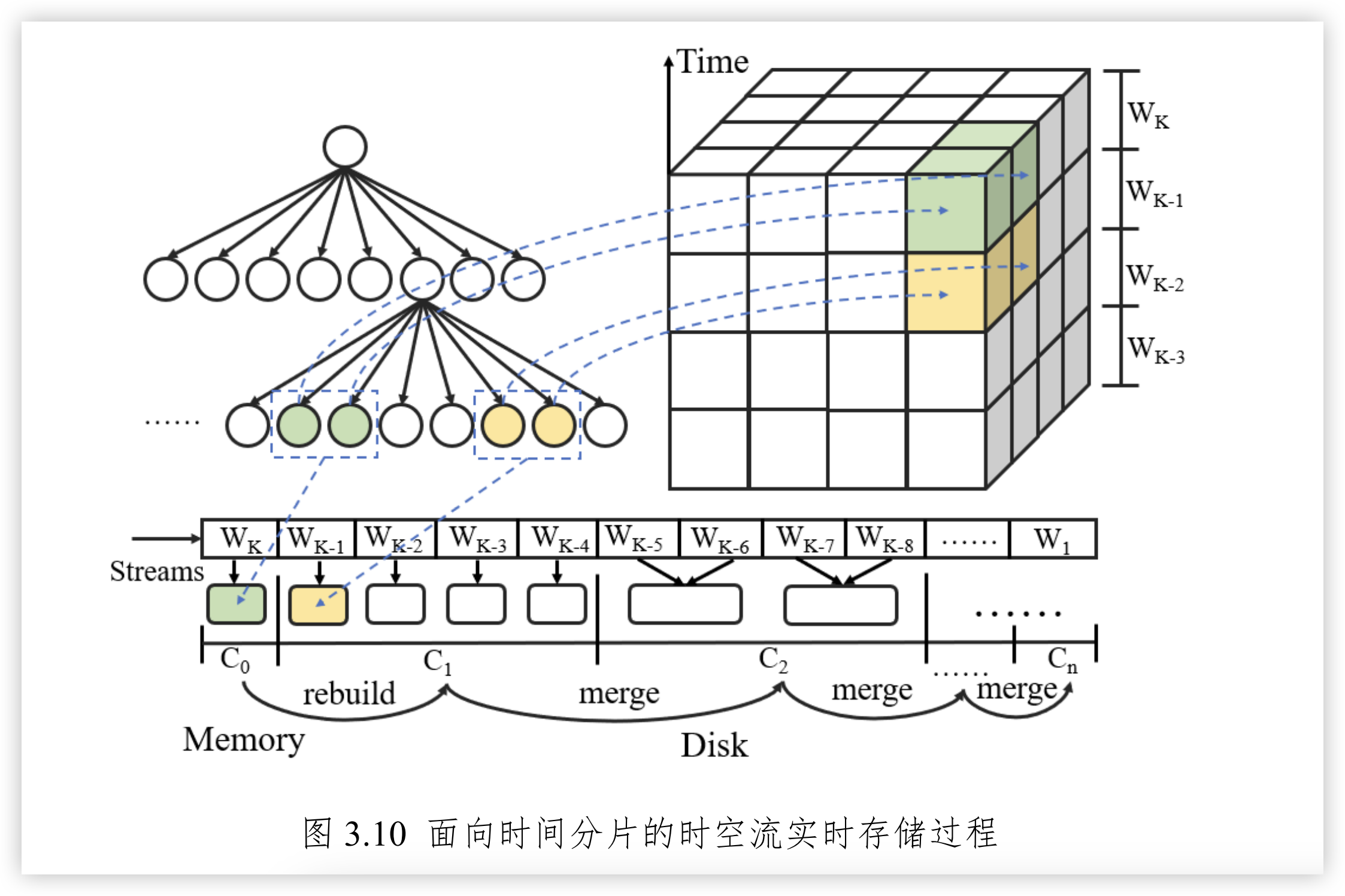
四、性能验证 五、总结展望