 KTurnura
commented
1 year ago
KTurnura
commented
1 year ago backup VM复制primary VM操作,实现了具有分区容错、企业级别的商业系统。设计并实现了一些组件,可以在故障后自动恢复冗余,构造了一个可用,高效的系统
使用最常见的primary/backup方式来实现容错,使用状态机来完成primary/backup同步:通过相同状态启动,并且确保他们以相同顺序接受相同输入请求,但有些操作是不确定的:读取时钟或发送中断。 而且被用来保证backup和primary同步所需的额外消息远远小于交互两者信息所需要的数量.
这种方法在现实物理机器上很难实现协调同步,但在Vmware这种运行在一个hypervisor之上特定的虚拟机中,却是一个很好的平台
hypervisor:可以实现一个对VM的完全控制,可以捕获在primary上所有不确定操作的必要信息,并且在backup上正确的重演 ,为了提供硬件容错性,该系统通过在任意一个本地可用服务器上启动一个新的backupVM来自动恢复冗余
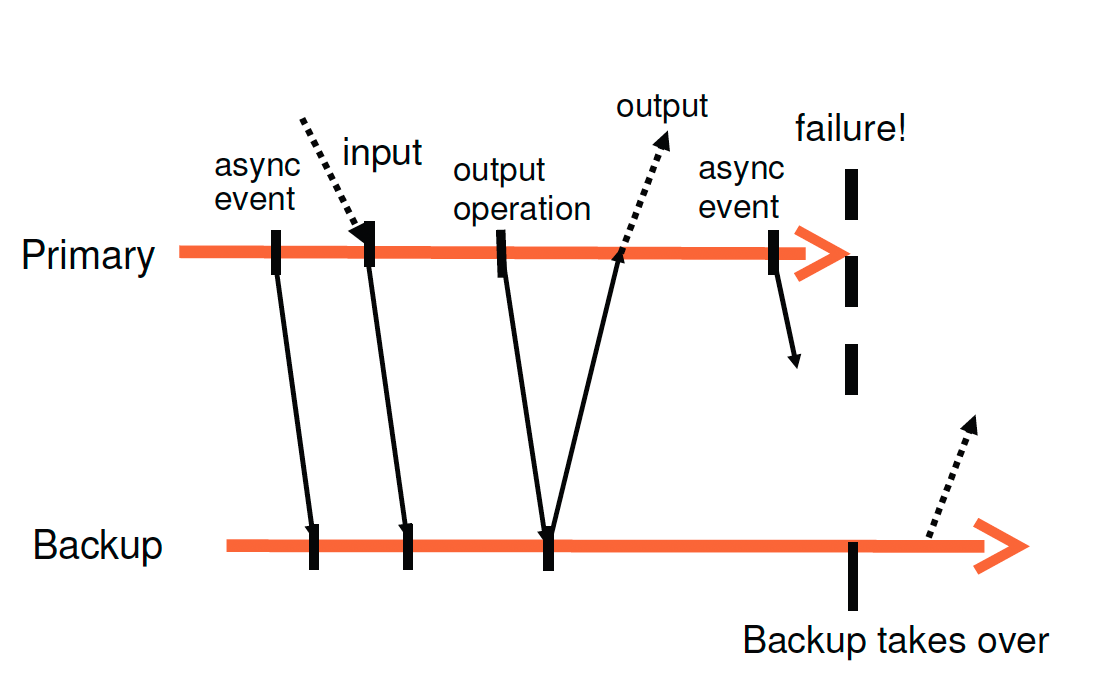
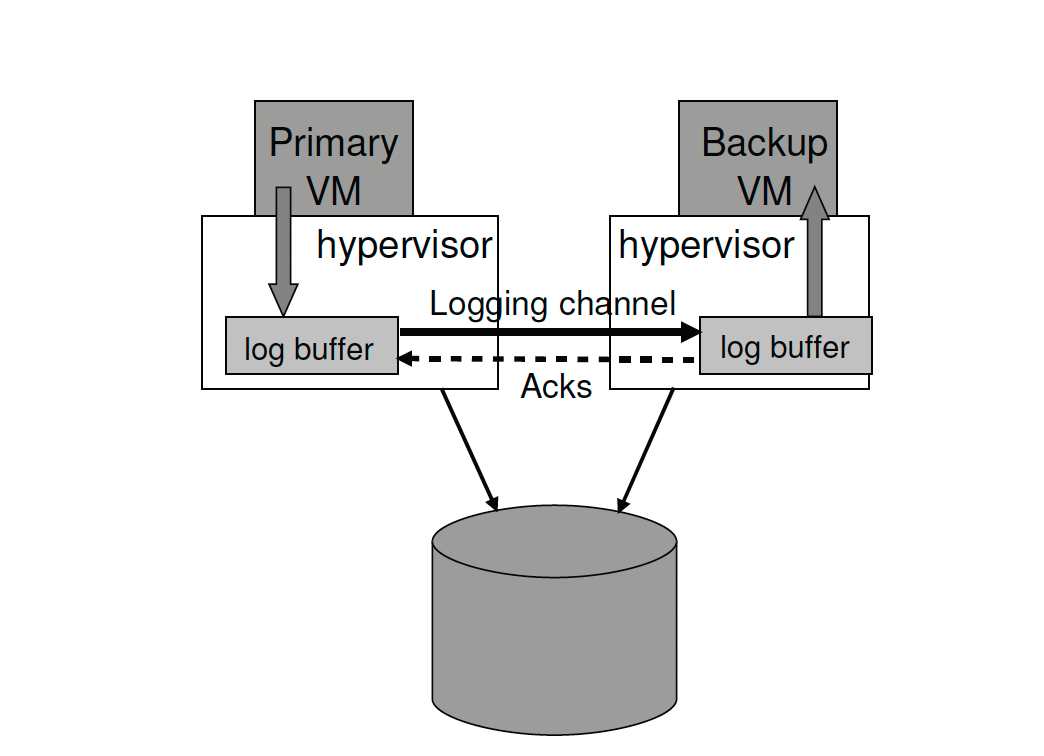
Vmware公司在虚拟机上实现分区容错性