IndoT5: T5 Language Models for the Indonesian Language!
This project focuses on pre-training a T5 (Text-to-Text Transfer Transformer) model specifically for the Indonesian language, using nanoT5 as its training framework. Our aim is to provide fully open-source, budget-constrained, sequence-to-sequence language models for Indonesia that are on-par with state-of-the-art models!
![]()
Pre-trained Models
| Model | #params | Dataset |
|---|---|---|
| LazarusNLP/IndoNanoT5-base | 248M | uonlp/CulturaX |
Results
We evaluate our models on IndoNLG, which consists of multiple downsteam generation tasks in Indonesian. The dataset also supports Javanese and Sundanese, but as our model is currently monolingual, we fine-tune on Indonesian tasks only.
IndoNLG baseline results are obtained from the official IndoNLG paper.
IndoSum
| Model | #params | R1 ↑ | R2 ↑ | RL ↑ |
|---|---|---|---|---|
| Scratch | 132M | 70.52 | 65.43 | 68.35 |
| mBART Large | 610M | 74.65 | 70.43 | 72.54 |
| mT5 Small | 300M | 74.04 | 69.64 | 71.89 |
| IndoBART | 132M | 70.67 | 65.59 | 68.18 |
| IndoGPT | 117M | 74.49 | 70.34 | 72.46 |
| Our work | ||||
| LazarusNLP/IndoNanoT5-base | 248M | 75.29 | 71.23 | 73.30 |
Liputan6 Canonical
| Model | #params | R1 ↑ | R2 ↑ | RL ↑ |
|---|---|---|---|---|
| Scratch | 132M | 38.14 | 20.67 | 31.85 |
| See et al. (2017) | 22M | 36.09 | 19.19 | 29.81 |
| Koto et al. (2020) | 153M | 41.06 | 22.83 | 34.23 |
| mBART Large | 610M | 39.17 | 21.75 | 32.85 |
| mT5 Small | 300M | 39.69 | 22.03 | 33.28 |
| IndoBART | 132M | 39.87 | 22.24 | 33.50 |
| IndoGPT | 117M | 37.41 | 20.61 | 31.54 |
| Our work | ||||
| LazarusNLP/IndoNanoT5-base | 248M | 39.76 | 22.29 | 33.46 |
Liputan6 Extreme
| Model | #params | R1 ↑ | R2 ↑ | RL ↑ |
|---|---|---|---|---|
| Scratch | 132M | 32.47 | 13.45 | 25.52 |
| See et al. (2017) | 22M | 30.39 | 12.03 | 23.55 |
| Koto et al. (2020) | 153M | 34.84 | 15.03 | 27.44 |
| mBART Large | 610M | 32.87 | 13.79 | 25.91 |
| mT5 Small | 300M | 33.37 | 14.01 | 26.21 |
| IndoBART | 132M | 33.58 | 14.45 | 26.68 |
| IndoGPT | 117M | 31.45 | 13.09 | 24.91 |
| Our work | ||||
| LazarusNLP/IndoNanoT5-base | 248M | 33.26 | 14.17 | 26.21 |
TyDiQA
| Model | #params | EM ↑ | F1 ↑ |
|---|---|---|---|
| Scratch | 132M | 21.40 | 29.77 |
| mBART Large | 610M | 62.69 | 76.41 |
| mT5 Small | 300M | 35.67 | 51.90 |
| IndoBART | 132M | 57.31 | 69.59 |
| IndoGPT | 117M | 50.18 | 63.97 |
| Our work | |||
| LazarusNLP/IndoNanoT5-base | 248M | 58.94 | 72.19 |
XPersona
| Model | #params | SacreBLEU ↑ | BLEU ↑ |
|---|---|---|---|
| Scratch | 132M | 1.86 | 1.86 |
| CausalBERT $^\dagger$ | 110M | 2.24 | 2.23 |
| mBART Large | 610M | 2.57 | 2.56 |
| mT5 Small | 300M | 1.90 | 1.89 |
| IndoBART | 132M | 2.93 | 2.93 |
| IndoGPT | 117M | 2.02 | 2.02 |
| Our work $^\dagger$ | |||
| LazarusNLP/IndoNanoT5-base | 248M | 4.07 | 4.07 |
$^\dagger$ Our models are trained with additional persona information, just like the original CausalBERT baseline. The remaining models are not trained with persona information. Our findings suggest that persona information is crucial for this task; serving a similar purpose to system prompts in recent LLM development.
Installation
git clone https://github.com/LazarusNLP/IndoT5.git
cd IndoT5
git submodule update --init # clone nanoT5 submodule
pip install -r requirements.txt
pip install -r nanoT5/requirements.txtDataset
We leverage the existing uonlp/CulturaX dataset which contains 23M Indonesian documents, collected and cleaned from the OSCAR corpora and mc4. We selected this dataset as it is sufficiently large and has been deduplicated. More details can be found in their dataset card.
Since this dataset is rather large, we utilize the dataset streaming feature of Hugging Face datasets, which is thankfully also supported in nanoT5. This feature is likewise usable during tokenizer training.
Train SentencePiece Tokenizer
We first need to train a SentencePiece tokenizer on our pre-pretraining corpus. We followed the uncased T5 tokenizer training implementation from HuggingFace. We then initialize a T5 config based on google/t5-v1_1-base and the newly trained tokenizer. Both the tokenizer and the config are then saved for loading later.
To train the SentencePiece tokenizer, run train_tokenizer.py with the desired arguments:
python train_tokenizer.py \
--vocab-size 32000 \
--dataset-name uonlp/CulturaX \
--dataset-config id \
--output-dir outputs/indonesian-t5-base/ \
--base-model-config google/t5-v1_1-base \
--hf-repo-id LazarusNLP/IndoNanoT5-baseIt took us about an hour to train the tokenizer.
Pre-train T5
NanoT5 handles most of the training process and exposes a clean API to pre-train a T5 model from scratch. We follow their default training configuration, with the exception of a lower learning rate which is specific to our dataset. Other than that, running pre-training is as simple as:
python -m nanoT5.main \
optim.name=adamwscale \
optim.lr_scheduler=cosine \
optim.base_lr=5e-3 \
model.name=LazarusNLP/IndoNanoT5-base \
model.compile=true \
data.num_workers=16We achieved a negative log-likelihood loss of 2.082 and an accuracy of 57.4% on a heldout subset (1%) of the pre-training corpus.
Experiments
We experimented with different learning rates, optimizers, and layer initialization strategies. Whilst we found that the default scaled AdamW optimizer worked best for our baseline results, we aim to further improve the results. Specifically, we aim to experiment with:
- [x] Initializing
lm_headweights withstd=1/sqrt(d_model) - [ ] (Unscaled) AdamW Optimizer
- [ ] NAdamW Optimizer
- [ ] Shampoo and CASPR Optimizers
This growing list of ideas stem from a fruitful discussion here.
Training Losses
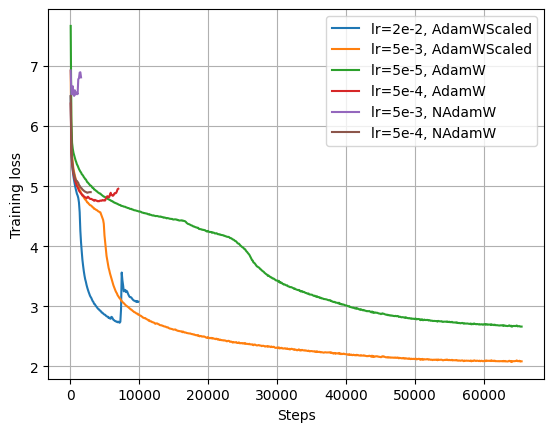
Fine-tune T5
NanoT5 supports fine-tuning to a downstream dataset like Super Natural-Instructions (SNI). However, since this requires further customization of fine-tuning code to other downstream datasets, we opted to develop our own fine-tuning script based on Hugging Face's sample fine-tuning code.
In particular, we developed fine-tuning scripts for 3 IndoNLG tasks, namely: summarization, question-answering, and chit-chat (conversational), which you can find in scripts.
Summarization
To fine-tune for summarization, run the following command and modify accordingly:
python scripts/run_summarization.py \
--model-checkpoint LazarusNLP/IndoNanoT5-base \ # pre-trained model checkpoint
--dataset-name LazarusNLP/indonlg \ # Hugging Face 🤗 dataset name
--dataset-config indosum \ # dataset config
--input-column-name input \ # input column (text passage) name in dataset
--target-column-name target \ # target column (summary) name in dataset
--input-max-length 512 \
--target-max-length 512 \
--num-beams 5 \ # beam width during beam search
--output-dir outputs/indo-nanot5-indosum \
--num-train-epochs 5 \
--optim adamw_torch_fused \ # any optimizer supported in Hugging Face 🤗 transformers
--learning-rate 1e-3 \
--weight-decay 0.01 \
--per-device-train-batch-size 8 \
--per-device-eval-batch-size 16 \
--hub-model-id LazarusNLP/IndoNanoT5-base-IndoSum # Hugging Face 🤗 Hub repo nameIndoNLG summarization recipes are provided here.
Question-Answering
To fine-tune for question-answering, run the following command and modify accordingly:
python scripts/run_qa.py \
--model-checkpoint LazarusNLP/IndoNanoT5-base \
--dataset-name LazarusNLP/indonlg \
--dataset-config question_answering \
--context-column-name context \ # context/passage column name
--question-column-name input \ # question column name
--answer-column-name references \ # answer column name, must be list
--id-column-name gem_id \ # question-answer pair id
--input-max-length 512 \
--target-max-length 512 \
--num-beams 5 \
--output-dir outputs/indo-nanot5-tydiqa \
--num-train-epochs 50 \
--optim adamw_torch_fused \
--learning-rate 1e-5 \
--weight-decay 0.01 \
--per-device-train-batch-size 8 \
--per-device-eval-batch-size 16 \
--hub-model-id LazarusNLP/IndoNanoT5-base-TyDiQAIndoNLG question-answering recipe is provided here.
Chit-chat
To fine-tune for chit-chat, run the following command and modify accordingly:
python scripts/run_chitchat.py \
--model-checkpoint LazarusNLP/IndoNanoT5-base \
--dataset-name LazarusNLP/indonlg \
--dataset-config xpersona \
--context-column-name context \ # context/persona column name
--question-column-name input \ # conversation history/dialogues column name
--answer-column-name references \ # response column name
--use-persona \ # whether to use persona or not
--input-max-length 512 \
--target-max-length 512 \
--num-beams 5 \
--output-dir outputs/indo-nanot5-xpersona \
--num-train-epochs 50 \
--optim adamw_torch_fused \
--learning-rate 1e-5 \
--weight-decay 0.01 \
--per-device-train-batch-size 8 \
--per-device-eval-batch-size 16 \
--hub-model-id LazarusNLP/IndoNanoT5-base-XPersonaAcknowledgements
Thanks to @PiotrNawrot and @Birch-san for the engaging discussion and ideas.
References
@article{Nawrot2023nanoT5AP,
title={nanoT5: A PyTorch Framework for Pre-training and Fine-tuning T5-style Models with Limited Resources},
author={Piotr Nawrot},
journal={ArXiv},
year={2023},
volume={abs/2309.02373},
}Credits
IndoT5 is developed with love by:



