## Blazingly fast, distributed streaming of training data from any cloud storage
⚡ Welcome to LitData
With LitData, users can transform and optimize their data in cloud storage environments efficiently and intuitively, at any scale.
Once optimized, efficient distributed training becomes practical regardless of where the data is located, enabling users to seamlessly stream data of any size to one or multiple machines.
LitData supports images, text, video, audio, geo-spatial, and multimodal data types, is already adopted by frameworks such as LitGPT to pretrain LLMs and integrates smoothly with PyTorch Lightning, Lightning Fabric, and PyTorch.
Runnable templates published on the Lightning.AI Platform are available at the end, reproducible in 1-click.
Table of Contents
- Getting started
- Key Features
- Benchmarks
- Runnable Templates
- Infinite cloud data processing
- Contributors
Getting Started
Installation
Install LitData with pip
pip install litdataInstall LitData with the extras
pip install 'litdata[extras]'Quick Start
1. Prepare Your Data
Convert your raw dataset into LitData Optimized Streaming Format using the optimize operator.
Here is an example with some random images.
import numpy as np
from litdata import optimize
from PIL import Image
# Store random images into the data chunks
def random_images(index):
data = {
"index": index, # int data type
"image": Image.fromarray(np.random.randint(0, 256, (32, 32, 3), np.uint8)), # PIL image data type
"class": np.random.randint(10), # numpy array data type
}
# The data is serialized into bytes and stored into data chunks by the optimize operator.
return data # The data is serialized into bytes and stored into data chunks by the optimize operator.
if __name__ == "__main__":
optimize(
fn=random_images, # The function applied over each input.
inputs=list(range(1000)), # Provide any inputs. The fn is applied on each item.
output_dir="my_optimized_dataset", # The directory where the optimized data are stored.
num_workers=4, # The number of workers. The inputs are distributed among them.
chunk_bytes="64MB" # The maximum number of bytes to write into a data chunk.
)
The optimize operator supports any data structures and types. Serialize whatever you want. The optimized data is stored under the output directory my_optimized_dataset.
2. Upload your Data to Cloud Storage
Cloud providers such as AWS, Google Cloud, Azure provide command line clients to upload your data to their storage solutions.
Here is how to upload the optimized dataset using the AWS CLI to AWS S3.
⚡ aws s3 cp --recursive my_optimized_dataset s3://my-bucket/my_optimized_dataset3. Use StreamingDataset
Then, the Streaming Dataset can read the data directly from AWS S3.
from litdata import StreamingDataset, StreamingDataLoader
# Remote path where full dataset is stored
input_dir = 's3://my-bucket/my_optimized_dataset'
# Create the Streaming Dataset
dataset = StreamingDataset(input_dir, shuffle=True)
# Access any elements of the dataset
sample = dataset[50]
img = sample['image']
cls = sample['class']
# Create dataLoader and iterate over it to train your AI models.
dataloader = StreamingDataLoader(dataset)Key Features
- Multi-GPU / Multi-Node Support
- Subsample and split your datasets
- Append or Overwrite optimized datasets
- Access any item
- Use any data transforms
- The Map Operator
- Easy Data Mixing with the Combined Streaming Dataset
- Pause & Resume Made simple
- Support Profiling
- Reduce your memory footprint
- Configure Cache Size Limit
- On-Prem Optimizations
- Support S3-Compatible Object Storage
Multi-GPU / Multi-Node Support
The StreamingDataset and StreamingDataLoader automatically make sure each rank receives the same quantity of varied batches of data, so it works out of the box with your favorite frameworks (PyTorch Lightning, Lightning Fabric, or PyTorch) to do distributed training.
Here you can see an illustration showing how the Streaming Dataset works with multi node / multi gpu under the hood.
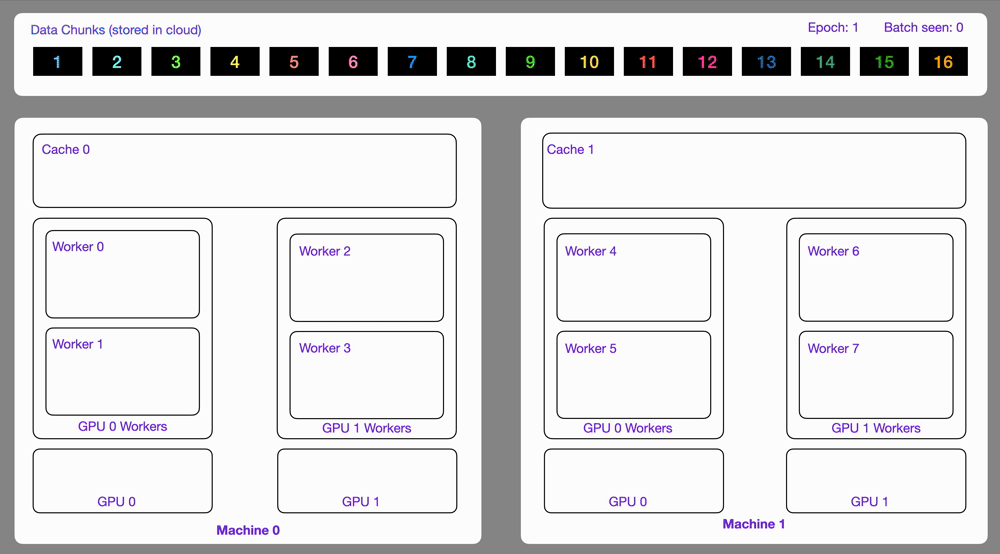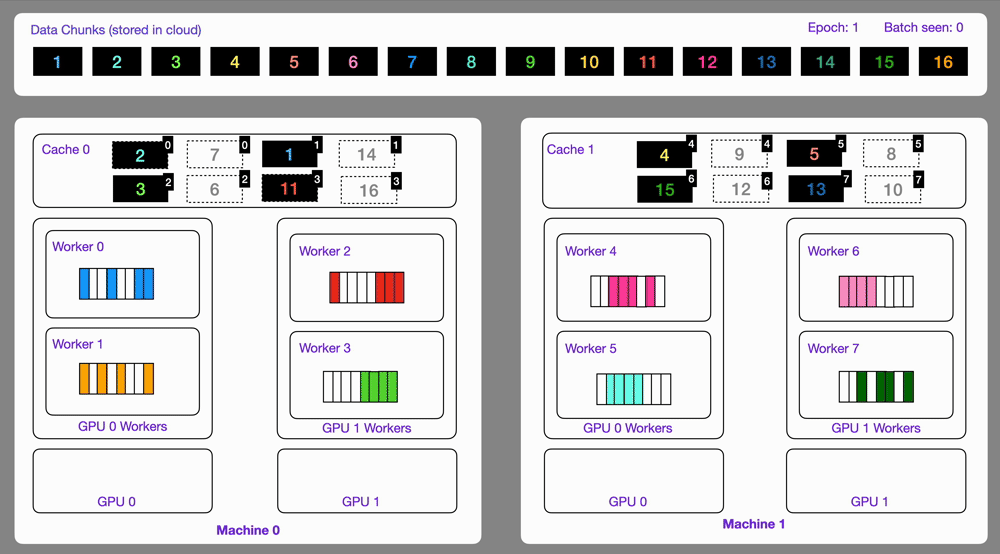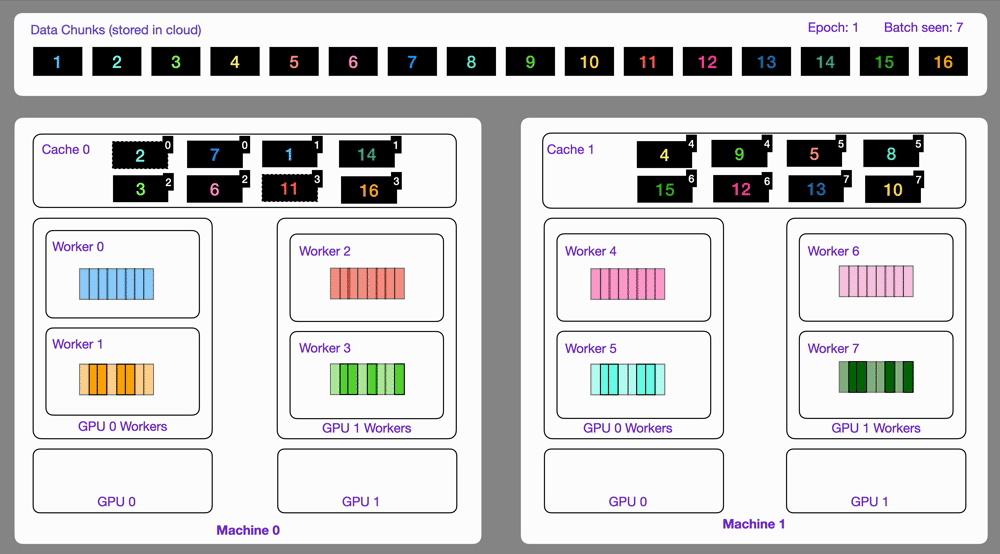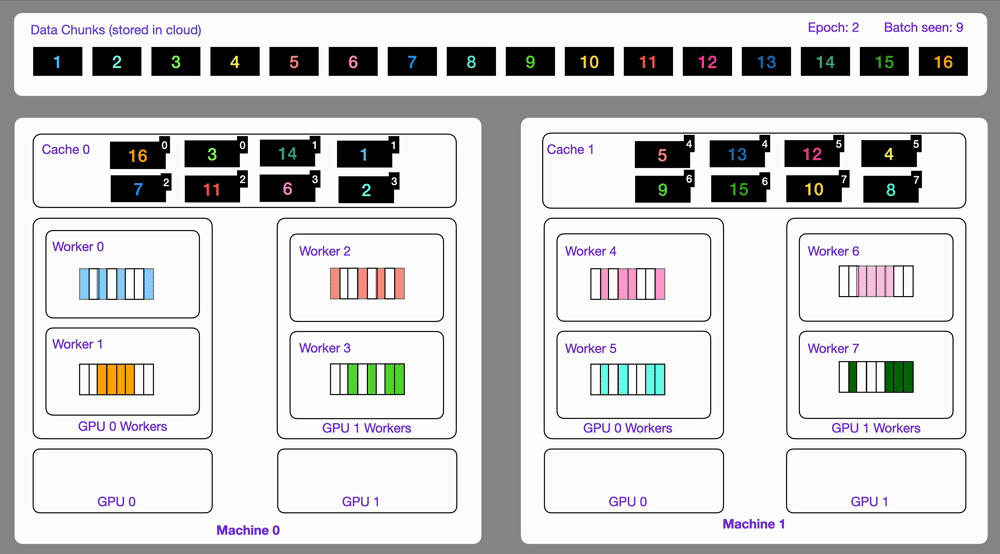
Subsample and split your datasets
You can split your dataset with more ease with train_test_split.
from litdata import StreamingDataset, train_test_split
dataset = StreamingDataset("s3://my-bucket/my-data") # data are stored in the cloud
print(len(dataset)) # display the length of your data
# out: 100,000
train_dataset, val_dataset, test_dataset = train_test_split(dataset, splits=[0.3, 0.2, 0.5])
print(train_dataset)
# out: 30,000
print(val_dataset)
# out: 20,000
print(test_dataset)
# out: 50,000Or simply subsample them
from litdata import StreamingDataset, train_test_split
dataset = StreamingDataset("s3://my-bucket/my-data", subsample=0.01) # data are stored in the cloud
print(len(dataset)) # display the length of your data
# out: 1000Or simply subsample them
from litdata import StreamingDataset, train_test_split
dataset = StreamingDataset("s3://my-bucket/my-data", subsample=0.01) # data are stored in the cloud
print(len(dataset)) # display the length of your data
# out: 1000Append or overwrite optimized datasets
LitData optimized datasets are assumed to be immutable. However, you can make the decision to modify them by changing the mode to either append or overwrite.
from litdata import optimize, StreamingDataset
def compress(index):
return index, index**2
if __name__ == "__main__":
# Add some data
optimize(
fn=compress,
inputs=list(range(100)),
output_dir="./my_optimized_dataset",
chunk_bytes="64MB",
)
# Later on, you add more data
optimize(
fn=compress,
inputs=list(range(100, 200)),
output_dir="./my_optimized_dataset",
chunk_bytes="64MB",
mode="append",
)
ds = StreamingDataset("./my_optimized_dataset")
assert len(ds) == 200
assert ds[:] == [(i, i**2) for i in range(200)]The overwrite mode will delete the existing data and start from fresh.
Access any item
Access the data you need, whenever you need it, regardless of where it is stored.
from litdata import StreamingDataset
dataset = StreamingDataset("s3://my-bucket/my-data") # data are stored in the cloud
print(len(dataset)) # display the length of your data
print(dataset[42]) # show the 42th element of the datasetUse any data transforms
Subclass the StreamingDataset and override its __getitem__ method to add any extra data transformations.
from litdata import StreamingDataset, StreamingDataLoader
import torchvision.transforms.v2.functional as F
class ImagenetStreamingDataset(StreamingDataset):
def __getitem__(self, index):
image = super().__getitem__(index)
return F.resize(image, (224, 224))
dataset = ImagenetStreamingDataset(...)
dataloader = StreamingDataLoader(dataset, batch_size=4)
for batch in dataloader:
print(batch.shape)
# Out: (4, 3, 224, 224)The Map Operator
The map operator can be used to apply a function over a list of inputs.
Here is an example where the map operator is used to apply a resize_image function over a folder of large images.
from litdata import map
from PIL import Image
# Note: Inputs could also refer to files on s3 directly.
input_dir = "my_large_images"
inputs = [os.path.join(input_dir, f) for f in os.listdir(input_dir)]
# The resize image takes one of the input (image_path) and the output directory.
# Files written to output_dir are persisted.
def resize_image(image_path, output_dir):
output_image_path = os.path.join(output_dir, os.path.basename(image_path))
Image.open(image_path).resize((224, 224)).save(output_image_path)
map(
fn=resize_image,
inputs=inputs,
output_dir="s3://my-bucket/my_resized_images",
)Easy Data Mixing with the Combined Streaming Dataset
Easily experiment with dataset mixtures using the CombinedStreamingDataset class.
As an example, this mixture of Slimpajama & StarCoder was used in the TinyLLAMA project to pretrain a 1.1B Llama model on 3 trillion tokens.
from litdata import StreamingDataset, CombinedStreamingDataset, StreamingDataLoader, TokensLoader
from tqdm import tqdm
import os
train_datasets = [
StreamingDataset(
input_dir="s3://tinyllama-template/slimpajama/train/",
item_loader=TokensLoader(block_size=2048 + 1), # Optimized loader for tokens used by LLMs
shuffle=True,
drop_last=True,
),
StreamingDataset(
input_dir="s3://tinyllama-template/starcoder/",
item_loader=TokensLoader(block_size=2048 + 1), # Optimized loader for tokens used by LLMs
shuffle=True,
drop_last=True,
),
]
# Mix SlimPajama data and Starcoder data with these proportions:
weights = (0.693584, 0.306416)
combined_dataset = CombinedStreamingDataset(datasets=train_datasets, seed=42, weights=weights)
train_dataloader = StreamingDataLoader(combined_dataset, batch_size=8, pin_memory=True, num_workers=os.cpu_count())
# Iterate over the combined datasets
for batch in tqdm(train_dataloader):
passPause & Resume Made Simple
LitData provides a stateful Streaming DataLoader e.g. you can pause and resume your training whenever you want.
Info: The Streaming DataLoader was used by Lit-GPT to pretrain LLMs. Restarting from an older checkpoint was critical to get to pretrain the full model due to several failures (network, CUDA Errors, etc..).
import os
import torch
from litdata import StreamingDataset, StreamingDataLoader
dataset = StreamingDataset("s3://my-bucket/my-data", shuffle=True)
dataloader = StreamingDataLoader(dataset, num_workers=os.cpu_count(), batch_size=64)
# Restore the dataLoader state if it exists
if os.path.isfile("dataloader_state.pt"):
state_dict = torch.load("dataloader_state.pt")
dataloader.load_state_dict(state_dict)
# Iterate over the data
for batch_idx, batch in enumerate(dataloader):
# Store the state every 1000 batches
if batch_idx % 1000 == 0:
torch.save(dataloader.state_dict(), "dataloader_state.pt")Support Profiling
The StreamingDataLoader supports profiling of your data loading process. Simply use the profile_batches argument to specify the number of batches you want to profile:
from litdata import StreamingDataset, StreamingDataLoader
StreamingDataLoader(..., profile_batches=5)This generates a Chrome trace called result.json. Then, visualize this trace by opening Chrome browser at the chrome://tracing URL and load the trace inside.
Reduce your memory footprint
When processing large files like compressed parquet files, use the Python yield keyword to process and store one item at the time, reducing the memory footprint of the entire program.
from pathlib import Path
import pyarrow.parquet as pq
from litdata import optimize
from tokenizer import Tokenizer
from functools import partial
# 1. Define a function to convert the text within the parquet files into tokens
def tokenize_fn(filepath, tokenizer=None):
parquet_file = pq.ParquetFile(filepath)
# Process per batch to reduce RAM usage
for batch in parquet_file.iter_batches(batch_size=8192, columns=["content"]):
for text in batch.to_pandas()["content"]:
yield tokenizer.encode(text, bos=False, eos=True)
# 2. Generate the inputs
input_dir = "/teamspace/s3_connections/tinyllama-template"
inputs = [str(file) for file in Path(f"{input_dir}/starcoderdata").rglob("*.parquet")]
# 3. Store the optimized data wherever you want under "/teamspace/datasets" or "/teamspace/s3_connections"
outputs = optimize(
fn=partial(tokenize_fn, tokenizer=Tokenizer(f"{input_dir}/checkpoints/Llama-2-7b-hf")), # Note: Use HF tokenizer or any others
inputs=inputs,
output_dir="/teamspace/datasets/starcoderdata",
chunk_size=(2049 * 8012), # Number of tokens to store by chunks. This is roughly 64MB of tokens per chunk.
)Configure Cache Size Limit
Adapt the local caching limit of the StreamingDataset. This is useful to make sure the downloaded data chunks are deleted when used and the disk usage stays low.
from litdata import StreamingDataset
dataset = StreamingDataset(..., max_cache_size="10GB")On-Prem Optimizations
On-prem compute nodes can mount and use a network drive. A network drive is a shared storage device on a local area network. In order to reduce their network overload, the StreamingDataset supports caching the data chunks.
from litdata import StreamingDataset
dataset = StreamingDataset(input_dir="local:/data/shared-drive/some-data")Support S3-Compatible Object Storage
Integrate S3-compatible object storage servers like MinIO with litdata, ideal for on-premises infrastructure setups. Configure the endpoint and credentials using environment variables or configuration files.
Set up the environment variables to connect to MinIO:
export AWS_ACCESS_KEY_ID=access_key
export AWS_SECRET_ACCESS_KEY=secret_key
export AWS_ENDPOINT_URL=http://localhost:9000 # MinIO endpointAlternatively, configure credentials and endpoint in ~/.aws/{credentials,config}:
mkdir -p ~/.aws && \
cat <<EOL >> ~/.aws/credentials
[default]
aws_access_key_id = access_key
aws_secret_access_key = secret_key
EOL
cat <<EOL >> ~/.aws/config
[default]
endpoint_url = http://localhost:9000 # MinIO endpoint
EOLExplore an example setup of litdata with MinIO in the LitData with MinIO repository for practical implementation details.
Benchmarks
In order to measure the effectiveness of LitData, we used a commonly used dataset for benchmarks: Imagenet-1.2M where the training set contains 1,281,167 images.
To align with other benchmarks, we measured the streaming speed (images per second) loaded from AWS S3 for several frameworks.
Reproduce our benchmark by running this Studio.
Imagenet-1.2M Streaming from AWS S3
We can observe LitData is up to 85 % faster than the second best. Higher is better in the table below.
| Framework | Images / sec 1st Epoch (float32) | Images / sec 2nd Epoch (float32) | Images / sec 1st Epoch (torch16) | Images / sec 2nd Epoch (torch16) |
|---|---|---|---|---|
| PL Data | 5800.34 | 6589.98 | 6282.17 | 7221.88 |
| Web Dataset | 3134.42 | 3924.95 | 3343.40 | 4424.62 |
| Mosaic ML | 2898.61 | 5099.93 | 2809.69 | 5158.98 |
Imagenet-1.2M Conversion
We measured how fast the 1.2 million images can converted into a streamable format. Faster is better in the table below.
| Framework | Train Conversion Time | Val Conversion Time | Dataset Size | # Files |
|---|---|---|---|---|
| PL Data | 10:05 min | 00:30 min | 143.1 GB | 2.339 |
| Web Dataset | 32:36 min | 01:22 min | 147.8 GB | 1.144 |
| Mosaic ML | 49:49 min | 01:04 min | 143.1 GB | 2.298 |
Runnable Templates
Fastest way to learn is with Studios.
Studios are reproducible cloud IDE with data, code, dependencies, e.g. so redo everything yourself with ease!
We've published public templates that demonstrates how best to use the LitData framework at scale and with several data types.
Sign up here and run your first Studio for free.
| Studio | Data type | Dataset |
|---|---|---|
| Use or explore LAION-400MILLION dataset | Image & Text | LAION-400M |
| Convert GeoSpatial data to Lightning Streaming | Image & Mask | Chesapeake Roads Spatial Context |
| Benchmark cloud data-loading libraries | Image & Label | Imagenet 1M |
| Prepare the TinyLlama 1T token dataset | Text | SlimPajama & StarCoder |
| Tokenize 2M Swedish Wikipedia Articles | Text | Swedish Wikipedia |
| Embed English Wikipedia under 5 dollars | Text | English Wikipedia |
| Convert parquets to Lightning Streaming | Parquet Files | Randomly Generated data |
Infinite cloud data processing
If you want to scale data processing, you typically need more machines and if you do this yourself, this becomes very tedious and can take a long time to get there.
Instead, create a free account on the Lightning.ai platform and use as many machines as you need from code.
On the platform, simply specify the number of nodes and the machine type you need as follows:
from litdata import map, Machine
map(
...
num_nodes=32,
machine=Machine.DATA_PREP, # Select between dozens of optimized machines
)Also, the optimize operator can do the same to make immense datasets streamable as follows:
from litdata import optimize, Machine
optimize(
...
num_nodes=32,
machine=Machine.DATA_PREP, # Select between dozens of optimized machines
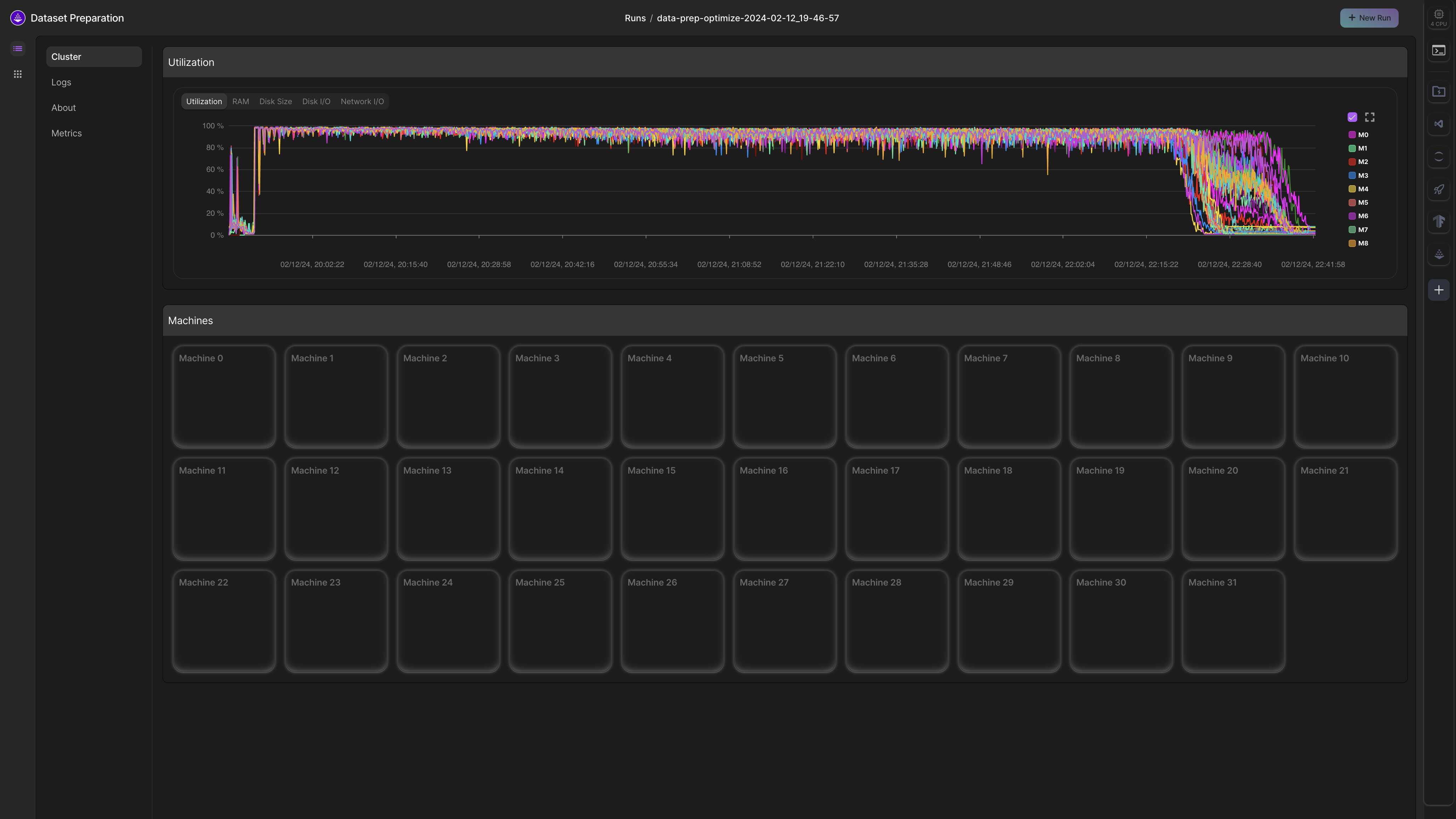
)Within the LAION 400 MILLION Studio, we utilized 32 machines, each equipped with 32 CPUs, to execute the optimize operator, enabling the download of 400 million images in just 2 hours. Below is a screenshot of that job within the Lightning.ai platform. You can execute it yourself here.
⚡ Contributors
We welcome any contributions, pull requests, or issues. If you use the Streaming Dataset for your own project, please reach out to us on Discord.