janpawlowskiof
commented
1 year ago
janpawlowskiof
commented
1 year ago I'd be willing to try and add this, provided that someone else approves that this would be a good addition.
Open janpawlowskiof opened 1 year ago
janpawlowskiof
commented
1 year ago I'd be willing to try and add this, provided that someone else approves that this would be a good addition.
janpawlowskiof
commented
1 year ago Writing here since this got no response yet.
@carmocca (I see that you are set to be autotagged to model checkpoint and logger issues), what is the course of action here? Should I do something with this issue that I perhaps missed or should this issue simply wait for triage?
 Borda
commented
1 year ago
Borda
commented
1 year ago @awaelchli what do you think about this case? :rabbit:
 awaelchli
commented
1 year ago
awaelchli
commented
1 year ago Adding the hook makes sense to me. I take it that it would be similar to the existing after_save_checkpoint hook for the loggers. Changing the meaning of log_model is probably not possible due to backward compatibility.
janpawlowskiof
commented
1 year ago Somewhat yes, but when calling after_save_checkpoint you do not specify directly which checkpoint was saved, (ModelCheckpoint has attribute last_model_path). With after_remove_checkpoint I think that you'd have to specify which checkpoint was removed.
Also I see that NeptuneLogger does in fact delete checkpoints that are no longer in top_k and it does that in after_save_checkpoint. It might be possible to add a similar solution to WandbLogger. I am not yet sure though.
awaelchli
commented
1 year ago @janpawlowskiof Then I think we should definitely investigate that first. Good call. Either way, with or without a new hook, I unfortunately couldn't find an easy way from the wandb api docs to delete a single file (or even check if one exists with a given name). It would require a bit more digging, if anyone wants to help.
 carmocca
commented
1 year ago
carmocca
commented
1 year ago I think this would fix https://github.com/Lightning-AI/lightning/issues/17147
 schmidt-ai
commented
1 year ago
schmidt-ai
commented
1 year ago +1 to this feature; I'd be willing to help out.
janpawlowskiof
commented
1 year ago Cool! I just want to say that I'm sorry that this went super stale, but I was focused on my Master Thesis, which I finished writing literally yesterday (yay!). I will probably submit a draft any day now, but I need to do some more testing.
janpawlowskiof
commented
1 year ago I just asked the guys at wandb for some input here on how to delete an Artifact that might be uploading without waiting for it to finish uploading. If this is not possible, we'd have to figure out some workaround.
Although even if you tried to wait() for an artifact for example in _scan_and_log_checkpoints and delete it (which you can do), something goes wrong down the line and I get:
wandb: ERROR Error while calling W&B API: base artifact QXJ0aWZhY3Q6NDk5OTE4NTEx is no longer committed (DELETED), rebase required (<Response [409]>)I hope that fixing this should be a matter of locating what tries to reference the deleted Artifact.
@schmidt-ai feel free to give any suggestions and ideas that you might have.
 gisilvs
commented
6 months ago
gisilvs
commented
6 months ago Is there any update on this?
janpawlowskiof
commented
6 months ago Unfortunately, in the end I didn't locate what caused mentioned error, and I had to move on due to lack of free time, sorry :c
There was some weird update two weeks ago on the issue/question I posted on linked wandb's github, but I doubt any progress has happened on their side.
My guess is that this feature is very much doable with the current wandb API, but I never tracked down this error.
Edit:
Editing this to add slightly more context as this issue went slightly stale and this issue really handicaps the usability of WandbLogger.
Description & Motivation
When using
ModelCheckpoint(save_top_k=3)andWandbLogger(log_model="all")you end up with only top 3 models saved locally, but multiple models uploaded to wandb, which feels like a buggish behavior.This is because currently loggers are notified after a checkpoints is saved, but are NOT notified after a checkpoint is removed. This could be solved, by adding a callback so that a logger knows, when a checkpoint is removed.
Described behavior is obviously undesirable because it creates tons of unnecessary checkpoints stored in a cloud. Using
log_model=Trueis not really a solution to this problem, because it defers uploading model until the training is complete and works ONLY when the training succeeds, so no checkpoints if your training crashes at any point.Pitch
Add a callback to loggers that is called after a checkpoint is removed to allow for removal of uploaded artifacts by a logger. This callback would presumably require a path to deleted checkpoint to be passed as an argument, but it seems like a reasonable aporoach.
Then modify WandbLogger to remove deprecated uploaded artifacts from the could. Then
log_model="all"mode could be replaced withlog_model="immediate", and possiblylog_model=Truewithlog_model="end", as that would be more appropriate naming, and more in-line with the description in the docs.Alternatives
WandbLogger could scan for local checkpoints and remove non-existent ones from the cloud without the need to actually add another callback method. This however seems like a slightly hacky solution.
Additional context
I'd be willing to write a PR for this if given an approval that is makes sense.
cc @borda @tchaton @justusschock @awaelchli @morganmcg1 @borisdayma @scottire @parambharat
Example
Given code:
You get: 3 checkpoints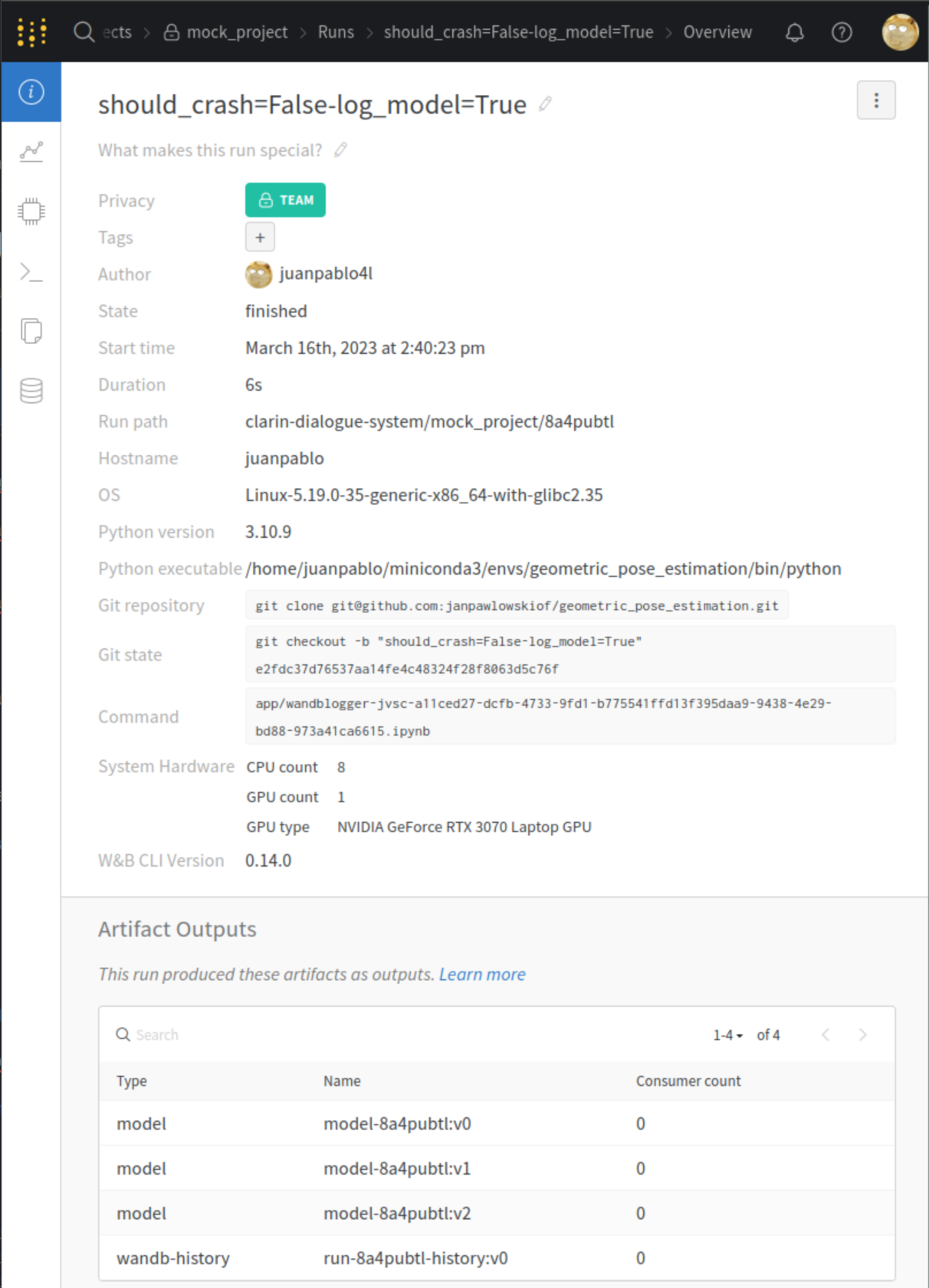
10 checkpoints: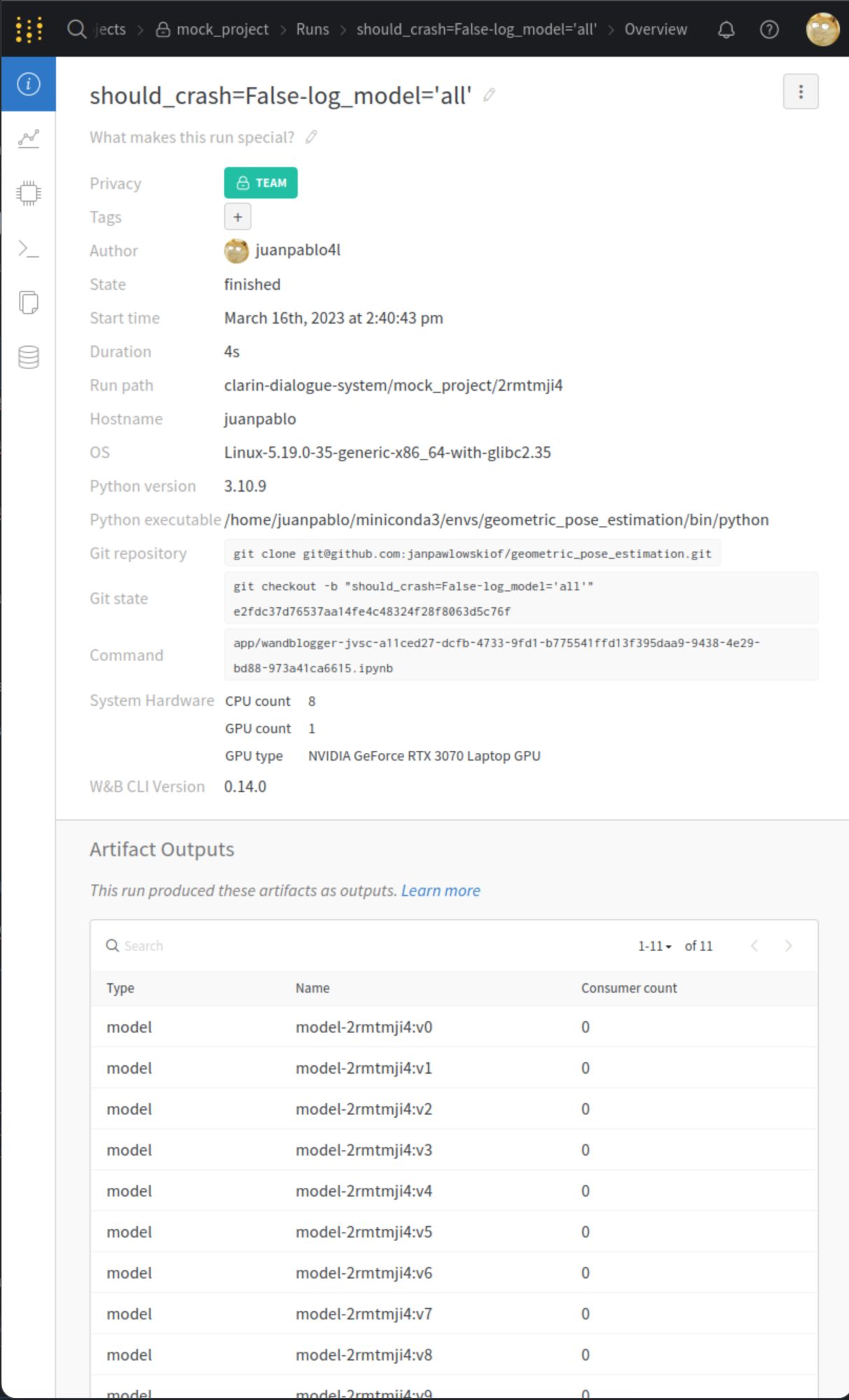
0 checkpoints: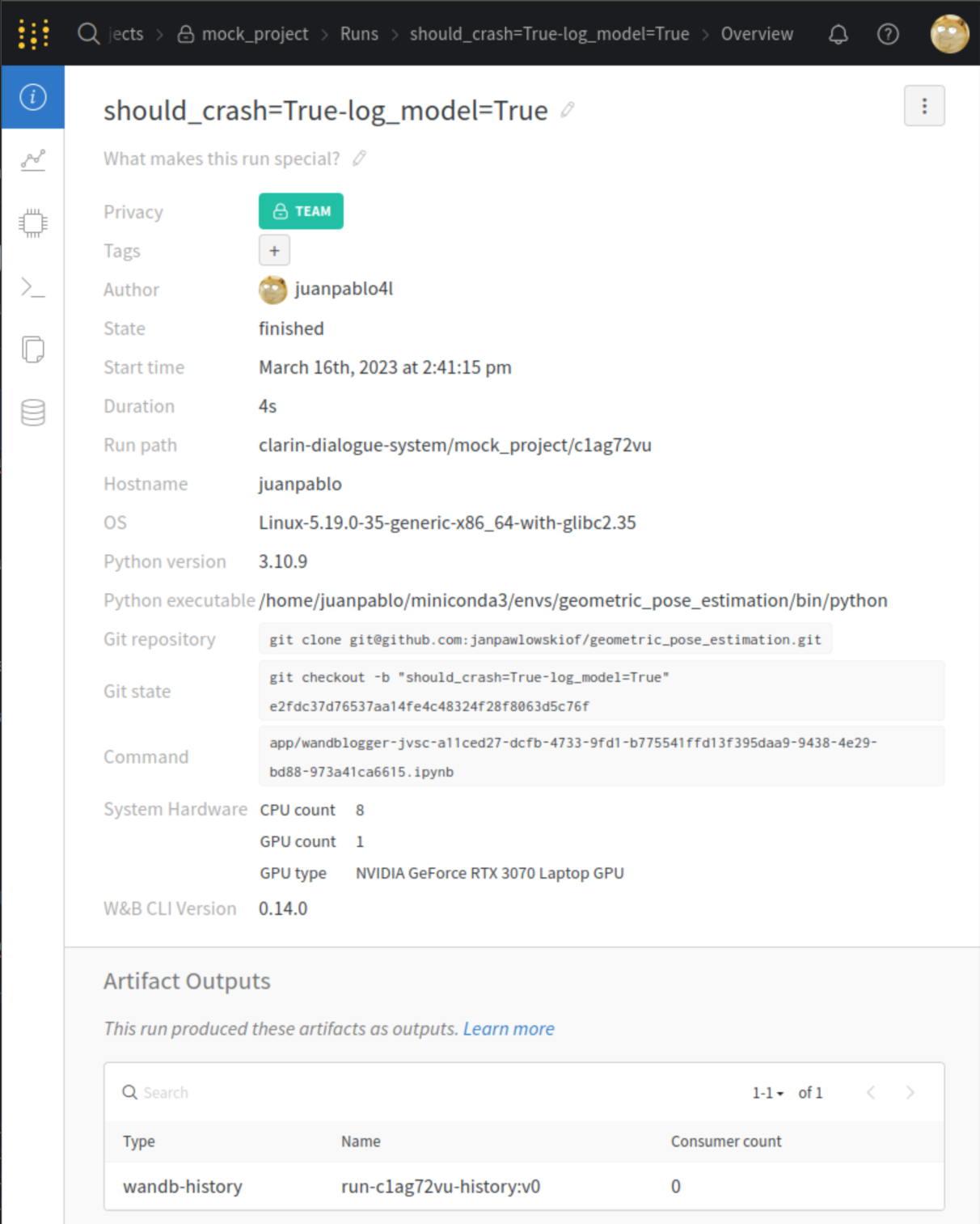
10 checkpoints: