![]()
A Flexible Deep Neural Network Approach to Fuzzy String Matching

![]()
![]()
![]()
DeezyMatch can be used in the following tasks:
- Fuzzy string matching
- Candidate ranking/selection
- Query expansion
- Toponym matching
Or as a component in tasks requiring fuzzy string matching and candidate ranking, such as:
- Record linkage
- Entity linking
Table of contents
- Installation and setup
- Data and directory structure in tutorials
- Run DeezyMatch: the quick tour
- Run DeezyMatch: the complete tour
- Examples on how to run DeezyMatch on Jupyter notebooks
- How to cite DeezyMatch
- Credits
Installation
We strongly recommend installation via Anaconda (refer to Anaconda website and follow the instructions).
- Create a new environment for DeezyMatch
conda create -n py39deezy python=3.9- Activate the environment:
conda activate py39deezy-
DeezyMatch can be installed in different ways:
-
Install DeezyMatch via PyPi (which tends to be the most user-friendly option):
- Install DeezyMatch:
pip install DeezyMatch -
Install DeezyMatch from the source code:
- Clone DeezyMatch source code:
git clone https://github.com/Living-with-machines/DeezyMatch.git- Install DeezyMatch dependencies:
cd /path/to/my/DeezyMatch pip install -r requirements.txt:warning: If you get
ModuleNotFoundError: No module named '_swigfaiss'error when runningcandidateRanker.py, one way to solve this issue is by:pip install faiss-cpu --no-cacheRefer to this page.
-
DeezyMatch can be installed using one of the following two options:
-
Install DeezyMatch in non-editable mode:
cd /path/to/my/DeezyMatch python setup.py install -
Install DeezyMatch in editable mode:
cd /path/to/my/DeezyMatch pip install -v -e .
-
-
We have provided some Jupyter Notebooks to show how different components in DeezyMatch can be run. To allow the newly created
py39deezyenvironment to show up in the notebooks:python -m ipykernel install --user --name py39deezy --display-name "Python (py39deezy)"
Data and directory structure in tutorials
You can create a new directory for your experiments. Note that this directory can be created outside of the DeezyMarch source code (after installation, DeezyMatch command lines and modules are accessible from anywhere on your local machine).
In the tutorials, we assume the following directory structure (i.e. we assume the commands are run from the main DeezyMatch directory):
DeezyMatch
├── dataset
│ ├── characters_v001.vocab
│ ├── dataset-string-matching_train.txt
│ ├── dataset-string-matching_finetune.txt
│ ├── dataset-string-matching_test.txt
│ ├── dataset-candidates.txt
│ └── dataset-queries.txt
└── inputs
├── characters_v001.vocab
└── input_dfm.yamlThe input file
The input file (input_dfm.yaml) allows the user to specify a series of parameters that will define the behaviour of DeezyMatch, without requiring the user to modify the code. The input file allows you to configure the following:
- Type of normalization and preprocessing that is to be applied to the input string, and tokenization mode (char, ngram, word).
- Neural network architecture (RNN, GRU, or LSTM) and its hyperparameters (number of layers and directions in the recurrent units, the dimensionality of the hidden layer, learning rate, number of epochs, batch size, early stopping, dropout probability), pooling mode and layers to freeze during fine-tuning.
- Proportion of data used for training, validation and test.
See the sample input file for a complete list of the DeezyMatch options that can be configured from the input file.
The vocabulary file
The vocabulary file (./inputs/characters_v001.vocab) file combines all characters from the different datasets we have used in our experiments (see DeezyMatch's paper and this paper for a detailed description of the datasets). It consists of 7,540 characters from multiple alphabets, containing special characters. You will only need to change the vocabulary file in certain fine-tuning settings.
The datasets
We provide the following minimal sample datasets to showcase the functionality of DeezyMatch. Please note that these are very small files that have been provided just for illustration purposes.
-
String matching datasets: The
dataset-string-matching_xxx.txtfiles are small subsets from a larger toponym matching dataset. We provide:dataset-string-matching_train.txt: data used for training a DeezyMatch model from scratch [5000 string pairs].dataset-string-matching_finetune.txt: data used for fine-tuning an existing DeezyMatch model (this is an optional step) [2500 string pairs].dataset-string-matching_test.txt: data used for assessing the performance of the DeezyMatch model (this is an optional step, as the training step already produces an intrinsic evaluation) [2495 string pairs].
The string matching datasets are composed of an equal number of positive and negative string matches, where:
- A positive string match is a pair of strings that can refer to the same entity (e.g. "Wādī Qānī" and "Uàdi Gani" are different variations of the same place name).
- A negative string match is a pair of strings that do not refer to the same entity (e.g. "Liufangwan" and "Wangjiawo" are not variations of the same place name).
The string matching datasets consist of at least three columns (tab-separated), where the first and second columns contain the two comparing strings, and the third column contain the label (i.e.
TRUEfor a positive match,FALSEfor a negative match). The dataset can have a number of additional columns, which DeezyMatch will ignore (e.g. the last six columns in the sample datasets). -
Candidates dataset: The
dataset-candidates.txtlists the potential candidates to which we want to match a query. The dataset we provide lists only 40 candidates (just for illustration purposes), with one candidate per line.In real case experiments, the candidates file is usually a large file, as it contains all possible name variations of the potential entities in a knowledge base (for example, supposing we want to find the Wikidata entity that corresponds to a certain query, the candidates would be all potential Wikidata names). This dataset lists one candidate per line. Additional tab-separated columns are allowed (they may be useful to keep information related to the candidate, such as the identifier in the knowledge base, but this additional information will be ignored by DeezyMatch).
-
Queries dataset: The
dataset-queries.txtlists the set of queries that we want to match with the candidates: 30 queries, with one query per line. The queries dataset is not required if you use DeezyMatch on-the-fly (see more about this below).
Run DeezyMatch: the quick tour
:warning: Refer to installation section to set up DeezyMatch on your local machine. In the following tutorials, we assume a directory structure specified in this section. The outputs of DeezyMatch will be created in the directory from which you are running it, unless otherwise explicitly specified.
Written in the Python programming language, DeezyMatch can be used as a stand-alone command-line tool or can be integrated as a module with other Python codes. In what follows, we describe DeezyMatch's functionalities in different examples and by providing both command lines and python modules syntaxes.
In this "quick tour", we go through all the DeezyMatch main functionalities with minimal explanations. Note that we provide basic examples using the DeezyMatch python modules here. If you want to know more about each module or run DeezyMatch via command line, refer to the relevant part of README (also referenced in this section):
from DeezyMatch import train as dm_train
# train a new model
dm_train(input_file_path="./inputs/input_dfm.yaml",
dataset_path="dataset/dataset-string-matching_train.txt",
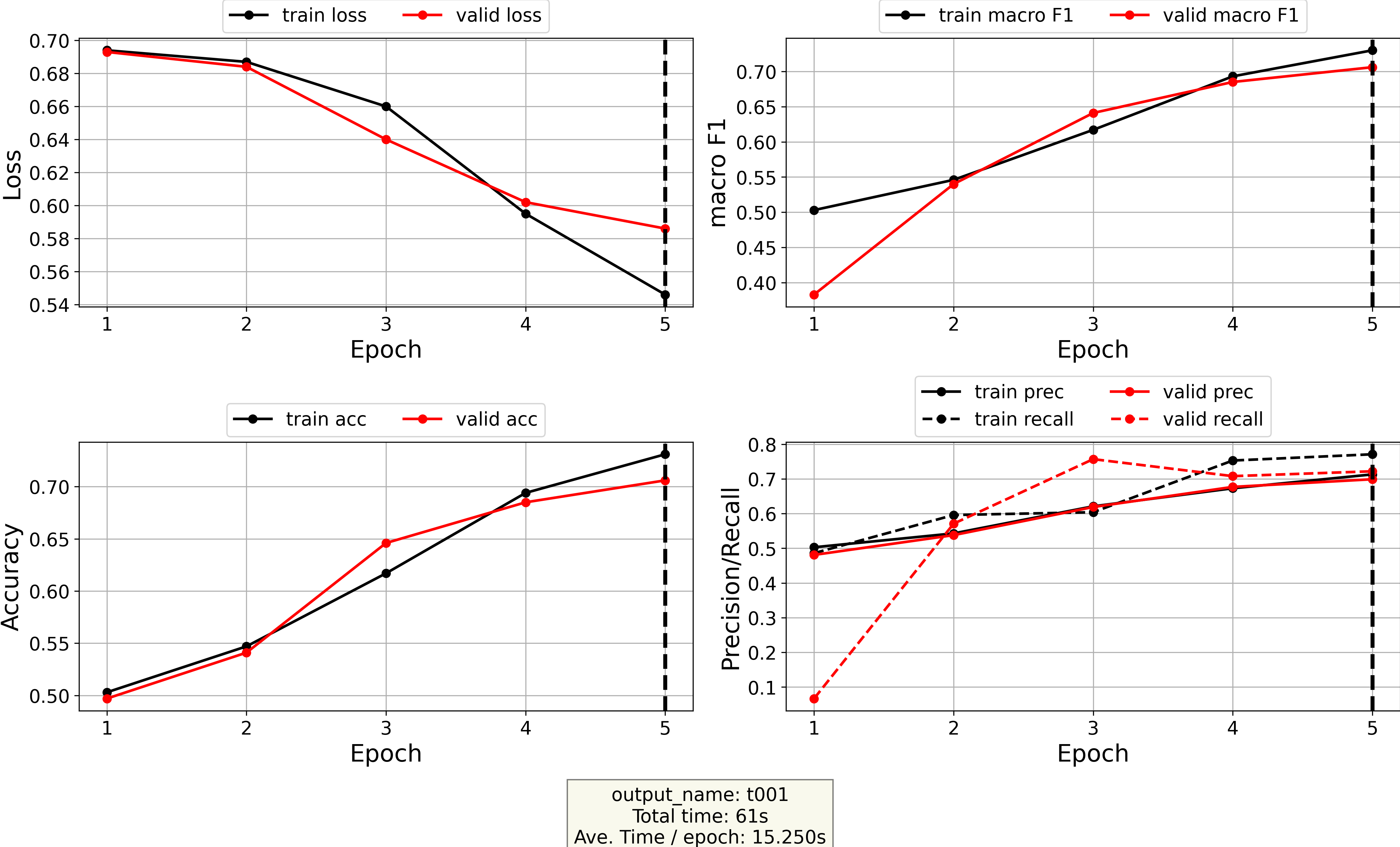
model_name="test001")- Plot the log file (stored at
./models/test001/log.txtand contains loss/accuracy/recall/F1-scores as a function of epoch):
from DeezyMatch import plot_log
# plot log file
plot_log(path2log="./models/test001/log.txt",
output_name="t001")from DeezyMatch import finetune as dm_finetune
# fine-tune a pretrained model stored at pretrained_model_path and pretrained_vocab_path
dm_finetune(input_file_path="./inputs/input_dfm.yaml",
dataset_path="dataset/dataset-string-matching_finetune.txt",
model_name="finetuned_test001",
pretrained_model_path="./models/test001/test001.model",
pretrained_vocab_path="./models/test001/test001.vocab")from DeezyMatch import inference as dm_inference
# model inference using a model stored at pretrained_model_path and pretrained_vocab_path (in this case, the model we have just finetuned)
dm_inference(input_file_path="./inputs/input_dfm.yaml",
dataset_path="dataset/dataset-string-matching_test.txt",
pretrained_model_path="./models/finetuned_test001/finetuned_test001.model",
pretrained_vocab_path="./models/finetuned_test001/finetuned_test001.vocab")from DeezyMatch import inference as dm_inference
# generate vectors for candidates (specified in dataset_path)
# using a model stored at pretrained_model_path and pretrained_vocab_path
dm_inference(input_file_path="./inputs/input_dfm.yaml",
dataset_path="dataset/dataset-candidates.txt",
pretrained_model_path="./models/finetuned_test001/finetuned_test001.model",
pretrained_vocab_path="./models/finetuned_test001/finetuned_test001.vocab",
inference_mode="vect",
scenario="candidates/test")from DeezyMatch import combine_vecs
# combine vectors stored in candidates/test and save them in combined/candidates_test
combine_vecs(rnn_passes=['fwd', 'bwd'],
input_scenario='candidates/test',
output_scenario='combined/candidates_test',
print_every=10)- Generate query vectors (not required for on-the-fly DeezyMatch):
from DeezyMatch import inference as dm_inference
# generate vectors for queries (specified in dataset_path)
# using a model stored at pretrained_model_path and pretrained_vocab_path
dm_inference(input_file_path="./inputs/input_dfm.yaml",
dataset_path="dataset/dataset-queries.txt",
pretrained_model_path="./models/finetuned_test001/finetuned_test001.model",
pretrained_vocab_path="./models/finetuned_test001/finetuned_test001.vocab",
inference_mode="vect",
scenario="queries/test")- Assembling queries vector representations (not required for on-the-fly DeezyMatch):
from DeezyMatch import combine_vecs
# combine vectors stored in queries/test and save them in combined/queries_test
combine_vecs(rnn_passes=['fwd', 'bwd'],
input_scenario='queries/test',
output_scenario='combined/queries_test',
print_every=10)from DeezyMatch import candidate_ranker
# Select candidates based on L2-norm distance (aka faiss distance):
# find candidates from candidate_scenario
# for queries specified in query_scenario
candidates_pd = \
candidate_ranker(query_scenario="./combined/queries_test",
candidate_scenario="./combined/candidates_test",
ranking_metric="faiss",
selection_threshold=5.,
num_candidates=2,
search_size=2,
output_path="ranker_results/test_candidates_deezymatch",
pretrained_model_path="./models/finetuned_test001/finetuned_test001.model",
pretrained_vocab_path="./models/finetuned_test001/finetuned_test001.vocab",
number_test_rows=20)from DeezyMatch import candidate_ranker
# Ranking on-the-fly
# find candidates from candidate_scenario
# for queries specified by the `query` argument
candidates_pd = \
candidate_ranker(candidate_scenario="./combined/candidates_test",
query=["DeezyMatch", "kasra", "fede", "mariona"],
ranking_metric="faiss",
selection_threshold=5.,
num_candidates=1,
search_size=100,
output_path="ranker_results/test_candidates_deezymatch_on_the_fly",
pretrained_model_path="./models/finetuned_test001/finetuned_test001.model",
pretrained_vocab_path="./models/finetuned_test001/finetuned_test001.vocab",
number_test_rows=20)The candidate ranker can be initialised, to be used multiple times, by running:
from DeezyMatch import candidate_ranker_init
# initializing candidate_ranker via candidate_ranker_init
myranker = candidate_ranker_init(candidate_scenario="./combined/candidates_test",
query=["DeezyMatch", "kasra", "fede", "mariona"],
ranking_metric="faiss",
selection_threshold=5.,
num_candidates=1,
search_size=100,
output_path="ranker_results/test_candidates_deezymatch_on_the_fly",
pretrained_model_path="./models/finetuned_test001/finetuned_test001.model",
pretrained_vocab_path="./models/finetuned_test001/finetuned_test001.vocab",
number_test_rows=20)
# print the content of myranker by:
print(myranker)
# To rank the queries:
myranker.rank()
#The results are stored in:
myranker.outputRun DeezyMatch: the complete tour
:warning: Refer to installation section to set up DeezyMatch on your local machine. In the following tutorials, we assume a directory structure specified in this section. The outputs of DeezyMatch will be created in the directory from which you are running it, unless otherwise explicitly specified.
Written in the Python programming language, DeezyMatch can be used as a stand-alone command-line tool or can be integrated as a module with other Python codes. In what follows, we describe DeezyMatch's functionalities in different examples and by providing both command lines and python modules syntaxes.
In this "complete tour", we go through all the DeezyMatch main functionalities in more detail.
Train a new model
DeezyMatch train module can be used to train a new model:
from DeezyMatch import train as dm_train
# train a new model
dm_train(input_file_path="./inputs/input_dfm.yaml",
dataset_path="dataset/dataset-string-matching_train.txt",
model_name="test001")The same model can be trained via command line:
DeezyMatch -i ./inputs/input_dfm.yaml -d dataset/dataset-string-matching_train.txt -m test001Summary of the arguments/flags:
| Func. argument | Command-line flag | Description |
|---|---|---|
| input_file_path | -i | path to the input file |
| dataset_path | -d | path to the dataset |
| model_name | -m | name of the new model |
| n_train_examples | -n | number of training examples to be used (optional) |
A new model directory called test001 will be created in models directory (as specified in the input file, see models_dir in ./inputs/input_dfm.yaml).
:warning: Dataset (e.g., dataset/dataset-string-matching_train.txt in the above command)
- The third column (label column) should be one of (case-insensitive): ["true", "false", "1", "0"]
- Delimiter is fixed to
\tfor now.
DeezyMatch keeps track of some evaluation metrics (e.g., loss/accuracy/precision/recall/F1) at each epoch.
DeezyMatch stores models, vocabularies, input file, log file and checkpoints (for each epoch) in the following directory structure (unless validation option in the input file is not equal to 1). When DeezyMatch finishes the last epoch, it will save the model with least validation loss as well (test001.model in the following directory structure).
models/
└── test001
├── checkpoint00001.model
├── checkpoint00001.model_state_dict
├── checkpoint00002.model
├── checkpoint00002.model_state_dict
├── checkpoint00003.model
├── checkpoint00003.model_state_dict
├── checkpoint00004.model
├── checkpoint00004.model_state_dict
├── checkpoint00005.model
├── checkpoint00005.model_state_dict
├── input_dfm.yaml
├── log_t001.png
├── log.txt
├── test001.model
├── test001.model_state_dict
└── test001.vocabDeezyMatch has an early stopping functionality, which can be activated by setting the early_stopping_patience option in the input file. This option specifies the number of epochs with no improvement after which training will be stopped and the model with the least validation loss will be saved.
Plot the log file
As said, DeezyMatch keeps track of some evaluation metrics (e.g., loss/accuracy/precision/recall/F1) at each epoch. It is possible to plot the log-file by:
from DeezyMatch import plot_log
# plot log file
plot_log(path2log="./models/test001/log.txt",
output_name="t001")or:
DeezyMatch -lp ./models/test001/log.txt -lo t001Summary of the arguments/flags:
| Func. argument | Command-line flag | Description |
|---|---|---|
| path2log | -lp | path to the log file |
| output_name | -lo | output name |
This command generates a figure log_t001.png and stores it in models/test001 directory.
Finetune a pretrained model
The finetune module can be used to fine-tune a pretrained model:
from DeezyMatch import finetune as dm_finetune
# fine-tune a pretrained model stored at pretrained_model_path and pretrained_vocab_path
dm_finetune(input_file_path="./inputs/input_dfm.yaml",
dataset_path="dataset/dataset-string-matching_finetune.txt",
model_name="finetuned_test001",
pretrained_model_path="./models/test001/test001.model",
pretrained_vocab_path="./models/test001/test001.vocab")dataset_path specifies the dataset to be used for finetuning. The paths to model and vocabulary of the pretrained model are specified in pretrained_model_path and pretrained_vocab_path, respectively.
It is also possible to fine-tune a model on a specified number of examples/rows from dataset_path (see the n_train_examples argument):
from DeezyMatch import finetune as dm_finetune
# fine-tune a pretrained model stored at pretrained_model_path and pretrained_vocab_path
dm_finetune(input_file_path="./inputs/input_dfm.yaml",
dataset_path="dataset/dataset-string-matching_finetune.txt",
model_name="finetuned_test001",
pretrained_model_path="./models/test001/test001.model",
pretrained_vocab_path="./models/test001/test001.vocab",
n_train_examples=100)The same can be done via command line:
DeezyMatch -i ./inputs/input_dfm.yaml -d dataset/dataset-string-matching_finetune.txt -m finetuned_test001 -f ./models/test001/test001.model -v ./models/test001/test001.vocab -n 100 Summary of the arguments/flags:
| Func. argument | Command-line flag | Description |
|---|---|---|
| input_file_path | -i | path to the input file |
| dataset_path | -d | path to the dataset |
| model_name | -m | name of the new, fine-tuned model |
| pretrained_model_path | -f | path to the pretrained model |
| pretrained_vocab_path | -v | path to the pretrained vocabulary |
| --- | -pm | print all parameters in a model |
| n_train_examples | -n | number of training examples to be used (optional) |
:warning: If -n flag (or n_train_examples argument) is not specified, the train/valid/test proportions are read from the input file.
A new fine-tuned model called finetuned_test001 will be stored in models directory. In this example, two components in the neural network architecture were frozen, that is, not changed during fine-tuning (see layers_to_freeze in the input file). When running the above command, DeezyMatch lists the parameters in the model and whether or not they will be used in finetuning:
============================================================
List all parameters in the model
============================================================
emb.weight False
rnn_1.weight_ih_l0 False
rnn_1.weight_hh_l0 False
rnn_1.bias_ih_l0 False
rnn_1.bias_hh_l0 False
rnn_1.weight_ih_l0_reverse False
rnn_1.weight_hh_l0_reverse False
rnn_1.bias_ih_l0_reverse False
rnn_1.bias_hh_l0_reverse False
rnn_1.weight_ih_l1 False
rnn_1.weight_hh_l1 False
rnn_1.bias_ih_l1 False
rnn_1.bias_hh_l1 False
rnn_1.weight_ih_l1_reverse False
rnn_1.weight_hh_l1_reverse False
rnn_1.bias_ih_l1_reverse False
rnn_1.bias_hh_l1_reverse False
attn_step1.weight False
attn_step1.bias False
attn_step2.weight False
attn_step2.bias False
fc1.weight True
fc1.bias True
fc2.weight True
fc2.bias True
============================================================The first column lists the parameters in the model, and the second column specifies if those parameters will be used in the optimization or not. In our example, we set layers_to_freeze: ["emb", "rnn_1", "attn"], so all the parameters except for fc1 and fc2 will not be changed during the training.
It is possible to print all parameters in a model by:
DeezyMatch -pm models/finetuned_test001/finetuned_test001.modelwhich generates a similar output as above.
Model inference
When a model is trained/fine-tuned, inference module can be used for predictions/model-inference. Again, dataset_path specifies the dataset to be used for inference, and the paths to model and vocabulary of the pretrained model (the fine-tuned model, in this case) are specified in pretrained_model_path and pretrained_vocab_path, respectively.
from DeezyMatch import inference as dm_inference
# model inference using a model stored at pretrained_model_path and pretrained_vocab_path
dm_inference(input_file_path="./inputs/input_dfm.yaml",
dataset_path="dataset/dataset-string-matching_test.txt",
pretrained_model_path="./models/finetuned_test001/finetuned_test001.model",
pretrained_vocab_path="./models/finetuned_test001/finetuned_test001.vocab")Similarly via command line:
DeezyMatch --deezy_mode inference -i ./inputs/input_dfm.yaml -d dataset/dataset-string-matching_test.txt -m ./models/finetuned_test001/finetuned_test001.model -v ./models/finetuned_test001/finetuned_test001.vocab -mode testSummary of the arguments/flags:
| Func. argument | Command-line flag | Description |
|---|---|---|
| input_file_path | -i | path to the input file |
| dataset_path | -d | path to the dataset |
| pretrained_model_path | -m | path to the pretrained model |
| pretrained_vocab_path | -v | path to the pretrained vocabulary |
| inference_mode | -mode | two options: test (inference, default), vect (generate vector representations) |
| scenario | -sc, --scenario | name of the experiment top-directory (only for inference_mode='vect') |
| cutoff | -n | number of examples to be used (optional) |
The inference component creates a file: models/finetuned_test001/pred_results_dataset-string-matching_test.txt in which:
# s1 s2 prediction p0 p1 label
ge lan bo er da Грюиссан 0 0.5223 0.4777 0
Leirvikskjæret Leirvikskjeret 1 0.4902 0.5098 1
Shih-pa-li-p'u P'u-k'ou-chen 1 0.4954 0.5046 0
Topoli Topolinski 0 0.5248 0.4752 1p0 and p1 are the probabilities assigned to labels 0 and 1 respectively, prediction is the predicted label, and label is the true label.
For example, in the first row ("ge lan bo er da" and "Грюиссан") the actual label is 0 and the predicted label is 0. The model confidence on the predicted label is p0=0.5223. In this example, DeezyMatch correctly predicts the label in the first two rows, and predicts it incorrectly in the last two rows.
:bangbang: It should be noted, in this example and for showcasing DeezyMatch's functionalities, the dataset used to train the above model was very small (~5000 rows for training, ~2500 rows for fine-tuning). In practice, we use larger datasets for training. Whereas the larger the better, the optimal minimum size of a dataset will depend on many factors. You can find some tips and recommendations in this document.
Generate query and candidate vectors
The inference module can also be used to generate vector representations for a set of strings in a dataset. This is a required step for candidate selection and ranking (which we will discuss later).
We first create vector representations for candidate mentions (we assume the candidate mentions are stored in dataset/dataset-candidates.txt):
from DeezyMatch import inference as dm_inference
# generate vectors for candidates (specified in dataset_path)
# using a model stored at pretrained_model_path and pretrained_vocab_path
dm_inference(input_file_path="./inputs/input_dfm.yaml",
dataset_path="dataset/dataset-candidates.txt",
pretrained_model_path="./models/finetuned_test001/finetuned_test001.model",
pretrained_vocab_path="./models/finetuned_test001/finetuned_test001.vocab",
inference_mode="vect",
scenario="candidates/test")Compared to the previous section, here we have two additional arguments:
inference_mode="vect": generate vector representations for the first column indataset_path.scenario: directory to store the vectors.
The same can be done via command line:
DeezyMatch --deezy_mode inference -i ./inputs/input_dfm.yaml -d dataset/dataset-candidates.txt -m ./models/finetuned_test001/finetuned_test001.model -v ./models/finetuned_test001/finetuned_test001.vocab -mode vect --scenario candidates/testFor summary of the arguments/flags, refer to the table in model inference.
The resulting directory structure is:
candidates/
└── test
├── dataframe.df
├── embeddings
│ ├── rnn_bwd_0
│ ├── rnn_fwd_0
│ ├── rnn_indxs_0
│ ├── rnn_bwd_1
│ ├── rnn_fwd_1
│ ├── rnn_indxs_1
│ └── ...
├── input_dfm.yaml
└── log.txtThe embeddings directory contains all the vector representations.
We can do the same for queries, using the dataset-queries.txt dataset:
from DeezyMatch import inference as dm_inference
# generate vectors for queries (specified in dataset_path)
# using a model stored at pretrained_model_path and pretrained_vocab_path
dm_inference(input_file_path="./inputs/input_dfm.yaml",
dataset_path="dataset/dataset-queries.txt",
pretrained_model_path="./models/finetuned_test001/finetuned_test001.model",
pretrained_vocab_path="./models/finetuned_test001/finetuned_test001.vocab",
inference_mode="vect",
scenario="queries/test")or via command line:
DeezyMatch --deezy_mode inference -i ./inputs/input_dfm.yaml -d dataset/dataset-queries.txt -m ./models/finetuned_test001/finetuned_test001.model -v ./models/finetuned_test001/finetuned_test001.vocab -mode vect --scenario queries/testFor summary of the arguments/flags, refer to the table in model inference.
The resulting directory structure is:
queries/
└── test
├── dataframe.df
├── embeddings
│ ├── rnn_bwd_0
│ ├── rnn_fwd_0
│ ├── rnn_indxs_0
│ ├── rnn_bwd_1
│ ├── rnn_fwd_1
│ ├── rnn_indxs_1
│ └── ...
├── input_dfm.yaml
└── log.txt:warning: Note that DeezyMatch's candidate ranker can be used on-the-fly, which means that we do not need to have a precomputed set of query vectors when ranking the candidates (they are generated on the spot). This previous last step (query vector generation) can therefore be skipped if DeezyMatch is used on-the-fly.
Combine vector representations
This step is required if the query or candidate vector representations are stored on several files (normally the case!). The combine_vecs module assembles those vectors and stores the results in output_scenario (see function below).
For candidate vectors:
from DeezyMatch import combine_vecs
# combine vectors stored in candidates/test and save them in combined/candidates_test
combine_vecs(rnn_passes=['fwd', 'bwd'],
input_scenario='candidates/test',
output_scenario='combined/candidates_test',
print_every=10)Similarly, for query vectors (this step should be skipped with on-the-fly ranking):
from DeezyMatch import combine_vecs
# combine vectors stored in queries/test and save them in combined/queries_test
combine_vecs(rnn_passes=['fwd', 'bwd'],
input_scenario='queries/test',
output_scenario='combined/queries_test',
print_every=10)Here, rnn_passes specifies that combine_vecs should assemble all vectors generated in the forward and backward RNN/GRU/LSTM passes (which are stored in the input_scenario directory).
NOTE: we have a backward pass only if bidirectional is set to True in the input file.
The results (for both query and candidate vectors) are stored in the output_scenario as follows:
combined/
├── candidates_test
│ ├── bwd_id.pt
│ ├── bwd_items.npy
│ ├── bwd.pt
│ ├── fwd_id.pt
│ ├── fwd_items.npy
│ ├── fwd.pt
│ └── input_dfm.yaml
└── queries_test
├── bwd_id.pt
├── bwd_items.npy
├── bwd.pt
├── fwd_id.pt
├── fwd_items.npy
├── fwd.pt
└── input_dfm.yamlThe above steps can be done via command line, for candidate vectors:
DeezyMatch --deezy_mode combine_vecs -p fwd,bwd -sc candidates/test -combs combined/candidates_testFor query vectors:
DeezyMatch --deezy_mode combine_vecs -p fwd,bwd -sc queries/test -combs combined/queries_testSummary of the arguments/flags:
| Func. argument | Command-line flag | Description |
|---|---|---|
| rnn_passes | -p | RNN/GRU/LSTM passes to be used in assembling vectors (fwd or bwd) |
| input_scenario | -sc | name of the input top-directory |
| output_scenario | -combs | name of the output top-directory |
| input_file_path | -i | path to the input file. "default": read input file in input_scenario |
| print_every | --- | interval to print the progress in assembling vectors |
| sel_device | --- | set the device (cpu, cuda, cuda:0, cuda:1, ...). if "default", the device will be read from the input file. |
| save_df | --- | save strings of the first column in queries/candidates files (default: True) |
Candidate ranking
Candidate ranker uses the vector representations, generated and assembled in the previous sections, to find a set of candidates (from a dataset or knowledge base) for a given set of queries.
In the following example, for queries stored in query_scenario, we want to find 2 candidates (specified by num_candidates) from the candidates stored in candidate_scenario (i.e. candidate_scenario and query_scenario point to the outputs from combining vector representations).
:warning: As mentioned, it is also possible to do candidate ranking on-the-fly in which query vectors are not read from a dataset (instead, they are generated on-the-fly). This is described in the next subsection.
from DeezyMatch import candidate_ranker
# Select candidates based on L2-norm distance (aka faiss distance):
# find candidates from candidate_scenario
# for queries specified in query_scenario
candidates_pd = \
candidate_ranker(query_scenario="./combined/queries_test",
candidate_scenario="./combined/candidates_test",
ranking_metric="faiss",
selection_threshold=5.,
num_candidates=2,
search_size=2,
output_path="ranker_results/test_candidates_deezymatch",
pretrained_model_path="./models/finetuned_test001/finetuned_test001.model",
pretrained_vocab_path="./models/finetuned_test001/finetuned_test001.vocab",
number_test_rows=20)In this example, query_scenario points to the directory that contains all the assembled query vectors (see previous section on combining vector representations) while candidate_scenario points to the directory that contains the assembled candidate vectors.
The retrieval of candidates is performed based on several parameters (ranking_metric, num_candidates, selection_threshold and search_size in the example), and using the DeezyMatch model specified in pretrained_model_path and using the vocabulary specified in pretrained_vocab_path. The output (a dataframe) is saved in the directory specified in output_path, but can also be accessed directly from the candidates_pd variable. The first few rows of the resulting dataframe are:
query pred_score 1-pred_score ... candidate_original_ids query_original_id num_all_searches
id ...
0 Lamdom Noi {'la dom nxy': 0.5271, 'Ouâdi ech Chalta': 0.5... {'la dom nxy': 0.4729, 'Ouâdi ech Chalta': 0.4... ... {'la dom nxy': 0, 'Ouâdi ech Chalta': 34} 0 2
1 Krutoi {'Krutoy': 0.5236, 'Engeskjæran': 0.4956} {'Krutoy': 0.47640000000000005, 'Engeskjæran':... ... {'Krutoy': 1, 'Engeskjæran': 6} 1 2
2 Sharuniata {'Sharunyata': 0.5296, 'Ndetach': 0.5272} {'Sharunyata': 0.47040000000000004, 'Ndetach':... ... {'Sharunyata': 2, 'Ndetach': 19} 2 2
3 Su Tang Cun {'Sutangcun': 0.5193, 'sthani xnamay ban hnxng... {'Sutangcun': 0.4807, 'sthani xnamay ban hnxng... ... {'Sutangcun': 3, 'sthani xnamay ban hnxngphi':... 3 2
4 Jowkare Shafi {'Anfijld': 0.5022, 'Ljublino': 0.5097} {'Anfijld': 0.4978, 'Ljublino': 0.490299999999... ... {'Anfijld': 10, 'Ljublino': 39} 4 2
5 Rongrian Ban Huai Huak Chom Thong {'rongreiyn ban hnxngbawdæng': 0.4975, 'rongre... {'rongreiyn ban hnxngbawdæng': 0.5025, 'rongre... ... {'rongreiyn ban hnxngbawdæng': 35, 'rongreiyn ... 5 2As mentioned, the retrieval of candidates is based on several parameters:
- Ranking metric (
ranking_metric): The metric used to rank the candidates based on their vectors. Choices are:faiss: L2-norm distance, as implemented in thefaisslibrary.cosine: cosine distance.conf: confidence as measured by DeezyMatch prediction outputs.
- Selection threshold (
threshold): Selection threshold, which changes according to the ranking metric that has been specified. A candidate will be selected in the following cases:faiss-distance <= selection_threshold cosine-distance <= selection_threshold prediction-confidence >= selection_threshold:bangbang: In
conf(i.e., prediction-confidence), the threshold corresponds to the minimum accepted value, while infaissandcosinemetrics, the threshold is the maximum accepted value. :bangbang: Thecosineandconfscores are between [0, 1] whilefaissdistance can take any values from [0, +∞). - Calculate prediction (
calc_predict): If the selected ranking metric isfaissorcosine, you can choose to skip prediction (by setting it toFalse), therefore speeding up the ranking significantly. - Search size (
search_size): Unlesscalc_predictis set toFalse(and therefore the prediction step is skipped during ranking), for a given query, DeezyMatch searches for candidates iteratively. At each iteration, the selected ranking metric between a query and candidates (with the size ofsearch_size) is computed, and if the number of desired candidates (specified bynum_candidates) is not reached, a new batch of candidates with the size ofsearch_sizeis tested in the next iteration. This continues until candidates with the size ofnum_candidatesare found or all the candidates are tested. If the role ofsearch_sizeargument is not clear, refer to Tips / Suggestions on DeezyMatch functionalities. - Maximum length difference (
length_diff): Finally, you can also specify the maximum length difference allowed between the query and the retrieved candidate strings, which may be a useful feature for certain applications.
Finally, only for testing, you can use number_test_rows. It specifies the number of queries to be used for testing.
The above results can be generated via command line as well:
DeezyMatch --deezy_mode candidate_ranker -qs ./combined/queries_test -cs ./combined/candidates_test -rm faiss -t 5 -n 2 -sz 2 -o ranker_results/test_candidates_deezymatch -mp ./models/finetuned_test001/finetuned_test001.model -v ./models/finetuned_test001/finetuned_test001.vocab -tn 20Summary of the arguments/flags:
| Func. argument | Command-line flag | Description |
|---|---|---|
| query_scenario | -qs | directory that contains all the assembled query vectors |
| candidate_scenario | -cs | directory that contains all the assembled candidate vectors |
| ranking_metric | -rm | choices arefaiss (used here, L2-norm distance),cosine (cosine distance),conf (confidence as measured by DeezyMatch prediction outputs) |
| selection_threshold | -t | changes according to the ranking_metric, a candidate will be selected if:faiss-distance <= selection_threshold, cosine-distance <= selection_threshold, prediction-confidence >= selection_threshold |
| query | -q | one string or a list of strings to be used in candidate ranking on-the-fly |
| num_candidates | -n | number of desired candidates |
| search_size | -sz | number of candidates to be tested at each iteration |
| length_diff | -ld | max length difference allowed between query and candidate strings |
| calc_predict | -up | whether to calculate prediction (i.e., model inference) or not |
| calc_cosine | -cc | whether to calculate cosine similarity or not |
| output_path | -o | path to the output file |
| pretrained_model_path | -mp | path to the pretrained model |
| pretrained_vocab_path | -v | path to the pretrained vocabulary |
| input_file_path | -i | path to the input file. "default": read input file in candidate_scenario |
| number_test_rows | -tn | number of examples to be used (optional, normally for testing) |
Other methods
- Select candidates based on cosine distance:
from DeezyMatch import candidate_ranker
# Select candidates based on cosine distance:
# find candidates from candidate_scenario
# for queries specified in query_scenario
candidates_pd = \
candidate_ranker(query_scenario="./combined/queries_test",
candidate_scenario="./combined/candidates_test",
ranking_metric="cosine",
selection_threshold=0.49,
num_candidates=2,
search_size=2,
output_path="ranker_results/test_candidates_deezymatch",
pretrained_model_path="./models/finetuned_test001/finetuned_test001.model",
pretrained_vocab_path="./models/finetuned_test001/finetuned_test001.vocab",
number_test_rows=20)Note that the only differences compared to the previous command are ranking_metric="cosine" and selection_threshold=0.49.
Candidate ranking on-the-fly
For a list of input strings (specified in query argument), DeezyMatch can rank candidates (stored in candidate_scenario) on-the-fly. Here, DeezyMatch generates and assembles the vector representations of strings in query on-the-fly.
from DeezyMatch import candidate_ranker
# Ranking on-the-fly
# find candidates from candidate_scenario
# for queries specified by the `query` argument
candidates_pd = \
candidate_ranker(candidate_scenario="./combined/candidates_test",
query=["DeezyMatch", "kasra", "fede", "mariona"],
ranking_metric="faiss",
selection_threshold=5.,
num_candidates=1,
search_size=100,
output_path="ranker_results/test_candidates_deezymatch_on_the_fly",
pretrained_model_path="./models/finetuned_test001/finetuned_test001.model",
pretrained_vocab_path="./models/finetuned_test001/finetuned_test001.vocab",
number_test_rows=20)The candidate ranker can be initialised, to be used multiple times, by running:
from DeezyMatch import candidate_ranker_init
# initializing candidate_ranker via candidate_ranker_init
myranker = candidate_ranker_init(candidate_scenario="./combined/candidates_test",
query=["DeezyMatch", "kasra", "fede", "mariona"],
ranking_metric="faiss",
selection_threshold=5.,
num_candidates=1,
search_size=100,
output_path="ranker_results/test_candidates_deezymatch_on_the_fly",
pretrained_model_path="./models/finetuned_test001/finetuned_test001.model",
pretrained_vocab_path="./models/finetuned_test001/finetuned_test001.vocab",
number_test_rows=20)The content of myranker can be printed by:
print(myranker)which results in:
-------------------------
* Candidate ranker params
-------------------------
Queries are based on the following list:
['DeezyMatch', 'kasra', 'fede', 'mariona']
candidate_scenario: ./combined/candidates_test
---Searching params---
num_candidates: 1
ranking_metric: faiss
selection_threshold: 5.0
search_size: 100
number_test_rows: 20
---I/O---
input_file_path: default (path: ./combined/candidates_test/input_dfm.yaml)
output_path: ranker_results/test_candidates_deezymatch_on_the_fly
pretrained_model_path: ./models/finetuned_test001/finetuned_test001.model
pretrained_vocab_path: ./models/finetuned_test001/finetuned_test001.vocabTo rank the queries:
myranker.rank()The results are stored in:
myranker.outputAll the query-related parameters can be changed via set_query method, for example:
myranker.set_query(query=["another_example"])other parameters include:
query
query_scenario
ranking_metric
selection_threshold
num_candidates
search_size
number_test_rows
output_pathAgain, we can rank the candidates for the new query by:
myranker.rank()
# to access output:
myranker.outputTips / Suggestions on DeezyMatch functionalities
Candidate ranker
-
As already mentioned, based on our experiments,
confis not a good metric for ranking candidates. Consider usingfaissorcosine. -
Adding prefix/suffix to input strings (see
prefix_suffixoption in the input file) can greatly enhance the ranking results. However, we recommend one-character-long prefix/suffix (for example '<' and '>'); otherwise, this may affect the computation time. -
In
candidate_ranker, the user specifies aranking_metricbased on which the candidates are selected and ranked. However, DeezyMatch also reports the values of other metrics for those candidates. For example, if the user selectsranking_metric="faiss", the candidates are selected based on thefaiss-distance metric. At the same time, the values ofcosineandconfmetrics for those candidates (ranked according to the selected metric, in this case faiss) are also reported. -
What is the role of
search_sizein candidate ranker?For a given query, DeezyMatch searches for candidates iteratively. If we set
search_sizeto five, at each iteration (i.e., one colored region in the figure below), the query vector is compared with five potential candidate vectors according to the selected ranking metric (ranking_metricargument). In step-1, the five closest candidate vectors, as measured by L2-norm distance, are examined. Four (out of five) candidate vectors passed the threshold (specified byselection_thresholdargument) in the figure (step-1). However, in this example, we assumenum_candidatesis 10. So, DeezyMatch examines the second batch of potential candidates, again five vectors (as specified bysearch_size). Three (out of five) candidates pass the threshold in step-2. Finally, in the third iteration, three more candidates are found. DeezyMatch collects the information of these ten candidates and go to the next query.This adaptive search algorithm significantly reduces the computation time to find and rank a set of candidates in a (large) dataset. Instead of searching the whole dataset, DeezyMatch iteratively compares a query vector with the "most-promising" candidates.
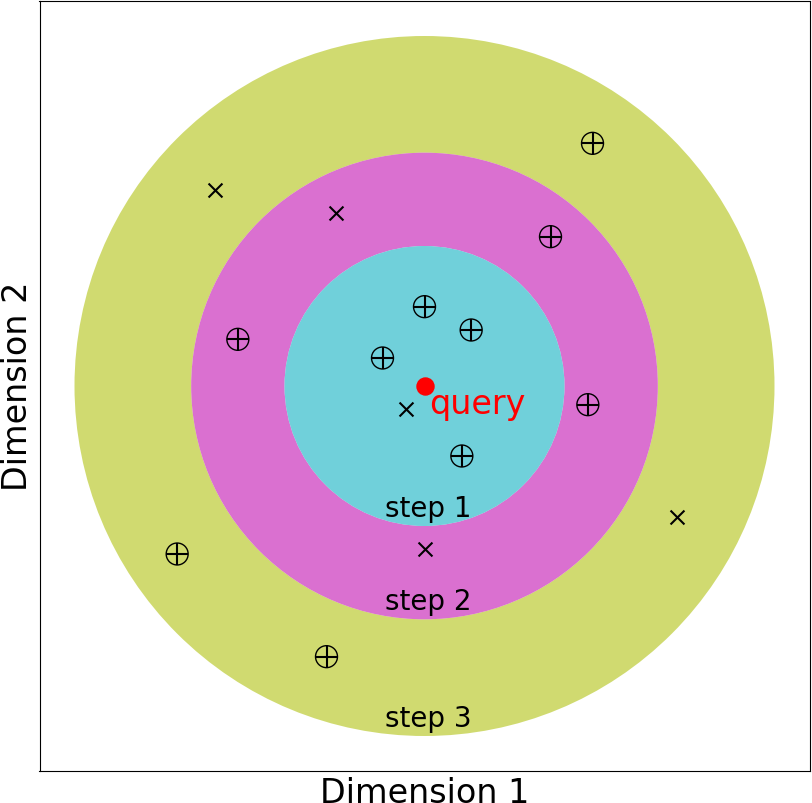
In most use cases,
search_sizecan be set>= num_candidates. However, ifnum_candidatesis very large, it is better to set thesearch_sizeto a lower value.Let's clarify this in an example. First, assume
num_candidates=4(number of desired candidates is 4 for each query). If we set thesearch_sizeto values less than 4, let's say, 2. DeezyMatch needs to do at least two iterations. In the first iteration, it looks at the closest 2 candidate vectors (assearch_sizeis 2). In the second iteration, candidate vectors 3 and 4 will be examined. So two iterations. Another choice issearch_size=4. Here, DeezyMatch looks at 4 candidates in the first iteration, if they pass the threshold, the process concludes. If not, it will seach candidates 5-8 in the next iteration. Now, let's assumenum_candidates=1001(i.e., number of desired candidates is 1001 for each query). If we set thesearch_size=1000, DeezyMatch has to search at least 2000 candidates (2 x 1000search_size). If we setsearch_size=100, this time, DeezyMatch has to search at least 1100 candidates (11 x 100search_size). So 900 vectors less. In the end, it is a trade-off between iterations andsearch_size.
How to cite DeezyMatch
Please consider acknowledging DeezyMatch if it helps you to obtain results and figures for publications or presentations, by citing:
ACL link: https://www.aclweb.org/anthology/2020.emnlp-demos.9/
Kasra Hosseini, Federico Nanni, and Mariona Coll Ardanuy (2020), DeezyMatch: A Flexible Deep Learning Approach to Fuzzy String Matching, In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 62–69. Association for Computational Linguistics.and in BibTeX:
@inproceedings{hosseini-etal-2020-deezymatch,
title = "{D}eezy{M}atch: A Flexible Deep Learning Approach to Fuzzy String Matching",
author = "Hosseini, Kasra and
Nanni, Federico and
Coll Ardanuy, Mariona",
booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations",
month = oct,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.emnlp-demos.9",
pages = "62--69",
abstract = "We present DeezyMatch, a free, open-source software library written in Python for fuzzy string matching and candidate ranking. Its pair classifier supports various deep neural network architectures for training new classifiers and for fine-tuning a pretrained model, which paves the way for transfer learning in fuzzy string matching. This approach is especially useful where only limited training examples are available. The learned DeezyMatch models can be used to generate rich vector representations from string inputs. The candidate ranker component in DeezyMatch uses these vector representations to find, for a given query, the best matching candidates in a knowledge base. It uses an adaptive searching algorithm applicable to large knowledge bases and query sets. We describe DeezyMatch{'}s functionality, design and implementation, accompanied by a use case in toponym matching and candidate ranking in realistic noisy datasets.",
}The results presented in this paper were generated by DeezyMatch v1.2.0 (Released: Sep 15, 2020).
You can reproduce Fig. 2 of DeezyMatch's paper, EMNLP2020, here.
Credits
This project extensively uses the ideas/neural-network-architecture published in https://github.com/ruipds/Toponym-Matching.
This work was supported by Living with Machines (AHRC grant AH/S01179X/1) and The Alan Turing Institute (EPSRC grant EP/ N510129/1).