Court Transcript Pipeline
Problem Statement
The National Archives release transcripts of real court hearings every day in plain text format. However, the sheer volume and format of these transcripts make them challenging for the average person to consume and analyse effectively. Key questions about court proceedings, such as judge behaviour and case outcomes, remain unanswered due to limited accessibility and resources. Additionally, the decline in journalism leads to the lack of public understanding of court judgments.
Elevator Pitch
Our project aims to bridge the gap between court proceedings and public understanding by developing a data pipeline to automate the enhancement, discoverability, and analysis of real courtroom documents.
Data Sources
- All Case Law Files: Updates approximately 12 times per day.
- All Judges in the UK: Updates irregularly.
Proposed Solution & Functionality
Our automated data pipeline will:
- Monitor for new court transcripts and process them accordingly.
- Parse text to extract key information and store it in a structured format.
- Utilise GPT-4 API for summarising transcripts in various ways, including categorisation, argument summaries, and event detection.
- Create a searchable dashboard to access and analyse extracted data.
- Deploy infrastructure using Terraform for scalability and manageability.
- Include thorough unit tests for critical code components.
Deliverables:
Data Pipeline
- Extract both judge data and case data from the given data sources.
- Transform the data by cleaning and standardising it.
- Summarise using GPT-4 API and give a verdict on each case.
- Deploy onto a dashboard to view all metrics.
- Create an API that allows for anyone to view court cases and judge information.
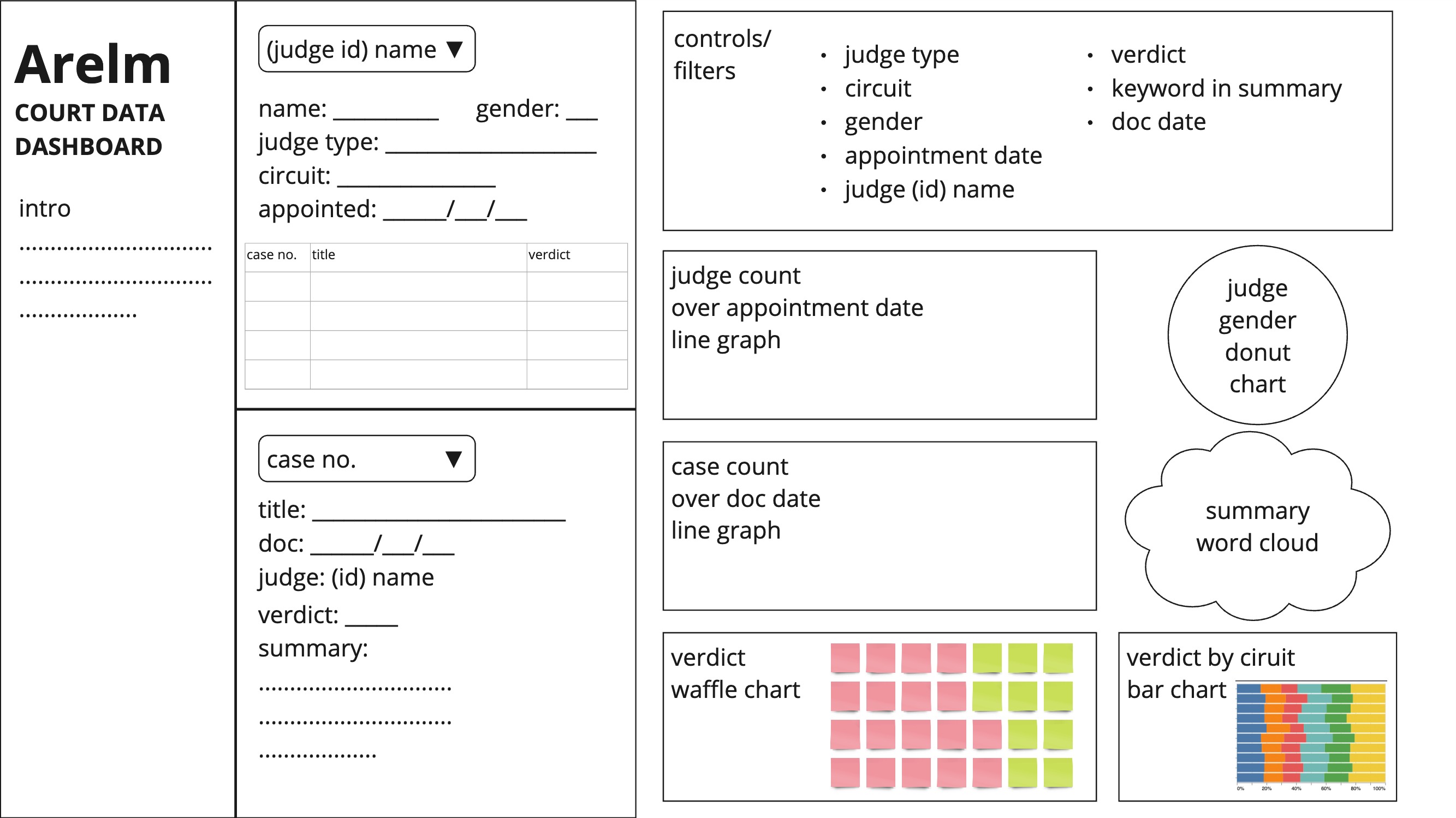
Visualization (Dashboard)
- Can view a wordcloud of the key words from the summary of the case
- Can see judges appointment over time
- Can view the judges and their cases through the search dropdown
API
- View multiple end points, that allow for the general public to view the case information and judge information
- Users are able to query the API, and take data and query it with however they want.
Overview
The pipeline script consists of several steps:
-
Extract: Connects to DB and scrapes the websites to access the URLs of each case, then return the PDF of the given case. We then extract the key information from the PDF and parse it using multiple regex statements and create a dataframe.
-
Transform: Applying GPT queries to all the cases conclusions and introductions to gain both a summary and a verdict. Cleans the retrieved data, standardising all the dates and the names of both the judges and court cases.
-
Load: Inserts the cleaned data into a Relational Database in this case we used PSQL. All data is inserted into the correct tables that can be viewed by running the bash scripts (See Bash Database Scripts Below):
ENV Variables
| ENV Variable Name | Description |
|---|---|
| DB_USER | Database User |
| DB_PASSWORD | Database Password |
| DB_HOST | Database Host |
| DB_PORT | Database Port |
| DB_NAME | Database Name |
| BASE_URL | Website URL |
| COMM_QUERY_EXTENSION | Commercial Court Query |
| STORAGE_FOLDER | Storage Folder Name |
| OPENAI_API_KEY | GPT API Key |
Pipeline Testing
We have also ensured to test each part of the pipeline to ensure that they work and these can be viewed below:
test_extract.py-> | Tests dataframe creation | Tests the URL with the cases | Tests the index to infinity function |test_transform.py-> | Tests date returns correct bool | Tests date formats correctly w/ Parametrisation | Tests if judge titles are stripped | Tests if case numbers have been standardised w/ Parametrisationtest_load.py-> xxxxxx
How to Test
In order to test the files, you firstly must make sure that you pip install -r requirements.txt in order to have access to pytest. Once this has been done you can run:
pytest test_xxxx-> This will run the pytest on the specific file itself.pytest-> This will run pytest on every test file within the directory you are currently in.pytest --cov . --cov-report term-missing-> This will show overall test coverage of the system, as well as whats missing and needs to be tested.
Data Cleaning
After fetching the data, the script performs cleaning operations to ensure consistency and data integrity. It standardises judges names and fixes the multiple different date\time formats when extracted from the PDFs to keep consistency within our database.
Database Interaction
The script establishes a database connection using the provided environment variables and inserts the cleaned data into the Database. It constructs SQL query strings dynamically based on the cleaned data and executes them to insert the data into the database.
Logging and Error Handling
The script utilises the logging module to log important events and errors during the execution process. This helps in debugging and monitoring the pipeline's performance.
BASH Database Scripts
We have also implemented bash scripts to simplify and automate connection and manipulation of the database. These scripts depend on environmental variables. Ensure you have a .env file with the correct values for each variable. To run these scripts in the terminal, execute bash [.sh script].
Connection
For this, we have a connect_db.sh which connects directly to the PSQL database without needing a password.
Table Creation
For this, we have a insert_schema.sh that runs the schema.sql into the database itself and adds all the tables with their corresponding keys.
Seeding Data
For this, we have a seed.sh which runs the seeds.sql script into the database, inserting all the static data into the tables within the database as well.
Deployment
Dashboard
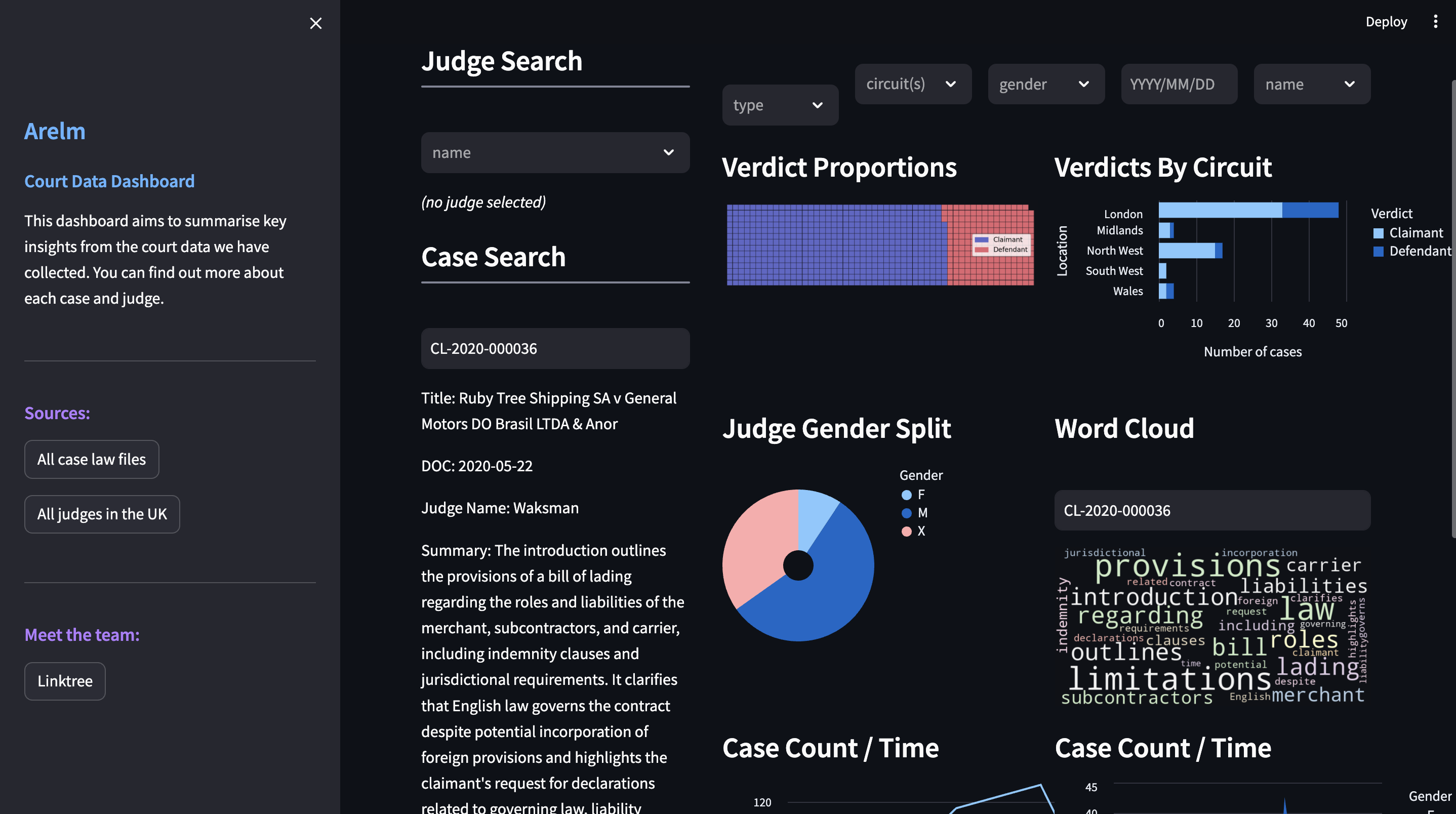
Access Our Dashboard via: http://c10-court-dashboard-alb-559509706.eu-west-2.elb.amazonaws.com/
You can also run it locally: streamlit run streamlit_app.py
Features
- View Judges & Their Cases: Can use the dropdown to view all the judges and the case information they are working on.
- Various Graphs: Can look through the various graphs and read the metrics, this will allow the user to gauge a better idea of the cases.
- WordCloud: Can use the wordcloud to quickly view the keywords and ideas from the summary of the case, via its case id.
Usage
- Users can access the dashboard and view various metrics about different cases and judges.
Data Sources
- Database: The app retrieves real-time judge and court data from a database using SQL queries.
API

Access to API via ECS: : http://c10-court-api-alb-767841739.eu-west-2.elb.amazonaws.com/
Features
- View Endpoints: On the route page you are able to view all the endpoints and filters, as well as what each one does.
- Querying: Users are able to access our api and query it with howver they see fit.
- API Intergration: Users are able to integrate the api within their own code and have access to the entire database.
Usage
- Accessing the database via querying API.
- Filtering through cases and judges.
Data Sources
- Database: The app retrieves real-time judge and court data from a database using SQL queries.
Terraform
This repository contains Terraform scripts to provision Lambda functions on AWS for various purposes related to managing plant data.
- Lambda Functions for accessing AWS services
main.tf- This file will spin up the AWS services using the access and secret key.
- Lambda Functions for running the pipeline
pipeline.tf- This file will create a lambda function which will run the whole pipeline file itself.
- Lambda Functions for RDS Insertion
pipeline_eventbridge.tf- This file will create a lambda function that spins up the event bridges that connect itself to the lambda function.
- Lambda Functions for RDS Insertion
api.tf- This file will create a ECS service that will run the api python task as a constant service, that can be accessed anywhere.
- Lambda Functions for RDS Insertion
dashboard.tf- This file will create a ECS service that will run the dashboard python task as a constant service, that can be accessed anywhere.
- Lambda Functions for RDS Insertion
judges.tf- This file will create a lambda function for the judges.
- Lambda Functions for RDS Insertion
judges_eventbridge.tf- This file will create a lambda function that spins up the event bridges that connect itself to the lambda function.
- Lambda Functions for RDS Insertion
variables.tf- This file will contain all the important variables that are needed, in order for the program to run and these can be found in the dependencies below.
Dependencies
There is also a file called variables.tf. In order to create the terraformed functions you must make sure you have a terraform.tfvars that contains the values associated with the variables in order for the commands to run the terraform to work.
This will include all the .env files and both AWS Access and Security Keys.
| ENV Variable Name | Description |
|---|---|
| AWS_ACCESS_KEY_ID | AWS Access Key ID |
| AWS_SECRET_ACCESS_KEY | AWS Secret Access Key |
| DB_USER | Database User |
| DB_PASSWORD | Database Password |
| DB_HOST | Database Host |
| DB_PORT | Database Port |
| DB_NAME | Database Name |
| BASE_URL | Website URL |
| COMM_QUERY_EXTENSION | Commercial Court Query |
| STORAGE_FOLDER | Storage Folder Name |
| OPENAI_API_KEY | GPT API Key |
| SUBNET_GROUP | VPC Subnets |
| VPC_ID | The ID of the VPC |
| ECS_ROLE | ECS Execution Role |
| ECS_CLUSTER | Name of the cluster |
Prerequisites
-
Terraform Installed: Ensure Terraform is installed on your machine. Download it from Terraform's official website and follow the installation instructions.
-
AWS Credentials: Have your AWS access key ID and secret access key ready. These credentials will be used by Terraform to authenticate with AWS.
Running Terraform
-
Navigate to Directory: Open a terminal and navigate to the directory where your Terraform scripts are located.
-
Initialize Terraform: Run
terraform initto initialize Terraform in the directory. This will download any necessary plugins and modules. -
Review Terraform Plan: Run
terraform planto see what changes Terraform will make to your infrastructure. Review the plan to ensure it aligns with your expectations. -
Apply Terraform Changes: If the plan looks good, apply the changes by running
terraform apply. Terraform will prompt you to confirm the changes before applying them. -
Monitor Progress: During the apply process, Terraform will display the progress and any errors encountered. Monitor the output closely.
Destroying Infrastructure
-
Navigate to Directory: Open a terminal and navigate to the directory where your Terraform scripts are located.
-
Run Terraform Destroy: Run
terraform destroyto destroy all resources managed by Terraform. Terraform will prompt you to confirm the destruction of resources. -
Confirm Destruction: Confirm the destruction by typing
yeswhen prompted. Terraform will begin destroying the infrastructure. -
Monitor Progress: During the destroy process, Terraform will display the progress and any errors encountered. Monitor the output closely.
Assumptions
- Assuming that all new cases will be on the first page of the government website.
- Assuming that there are going to be fewer than 10 cases per day (high court cases).
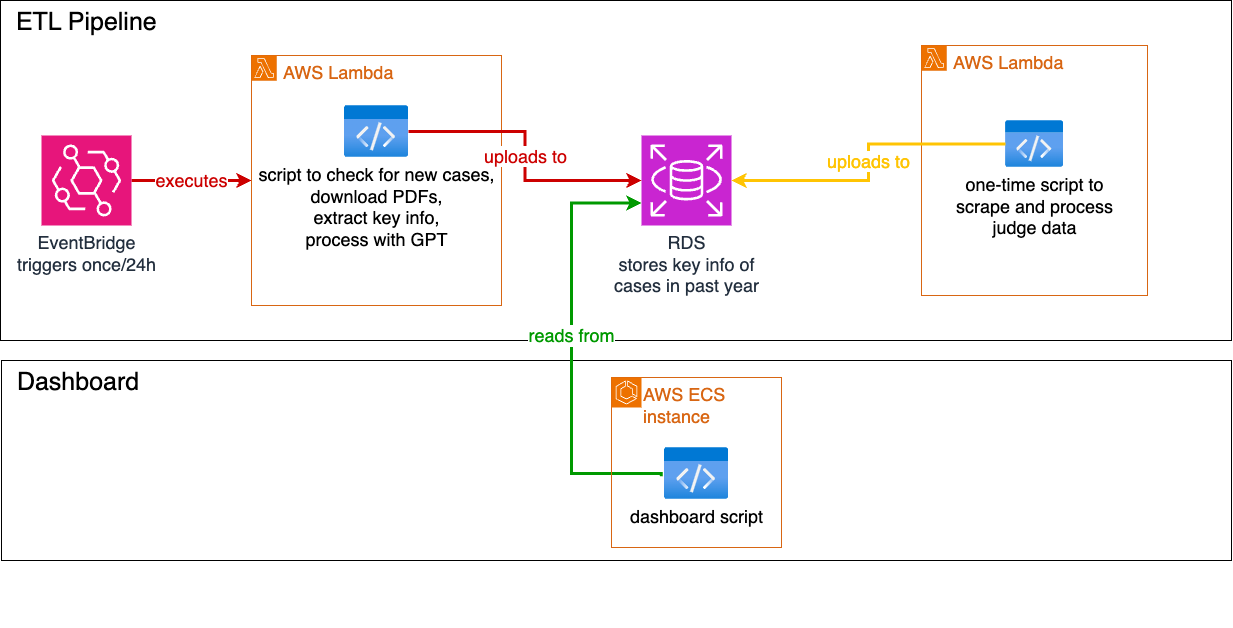
Diagrams
Architecture Diagram
Minimum Viable Product
Stretched Goal
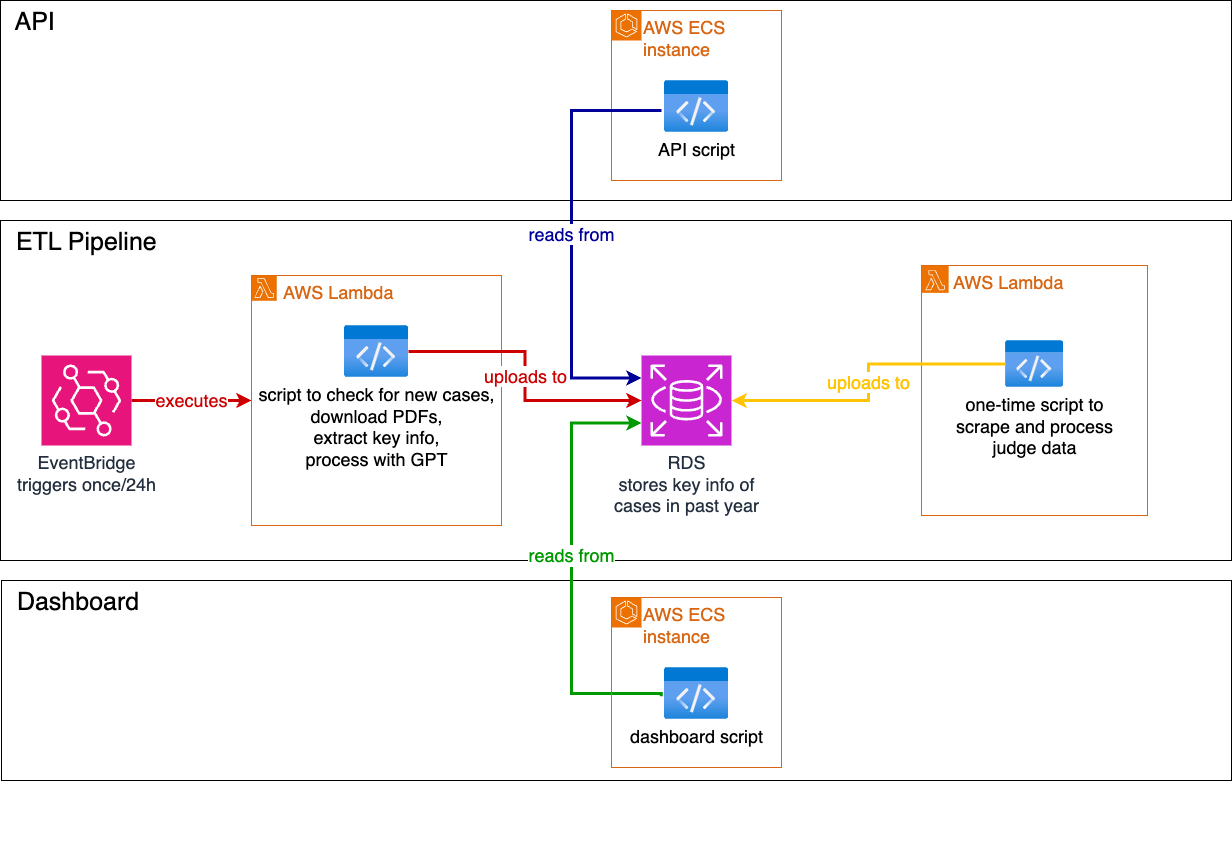
Above and Beyond

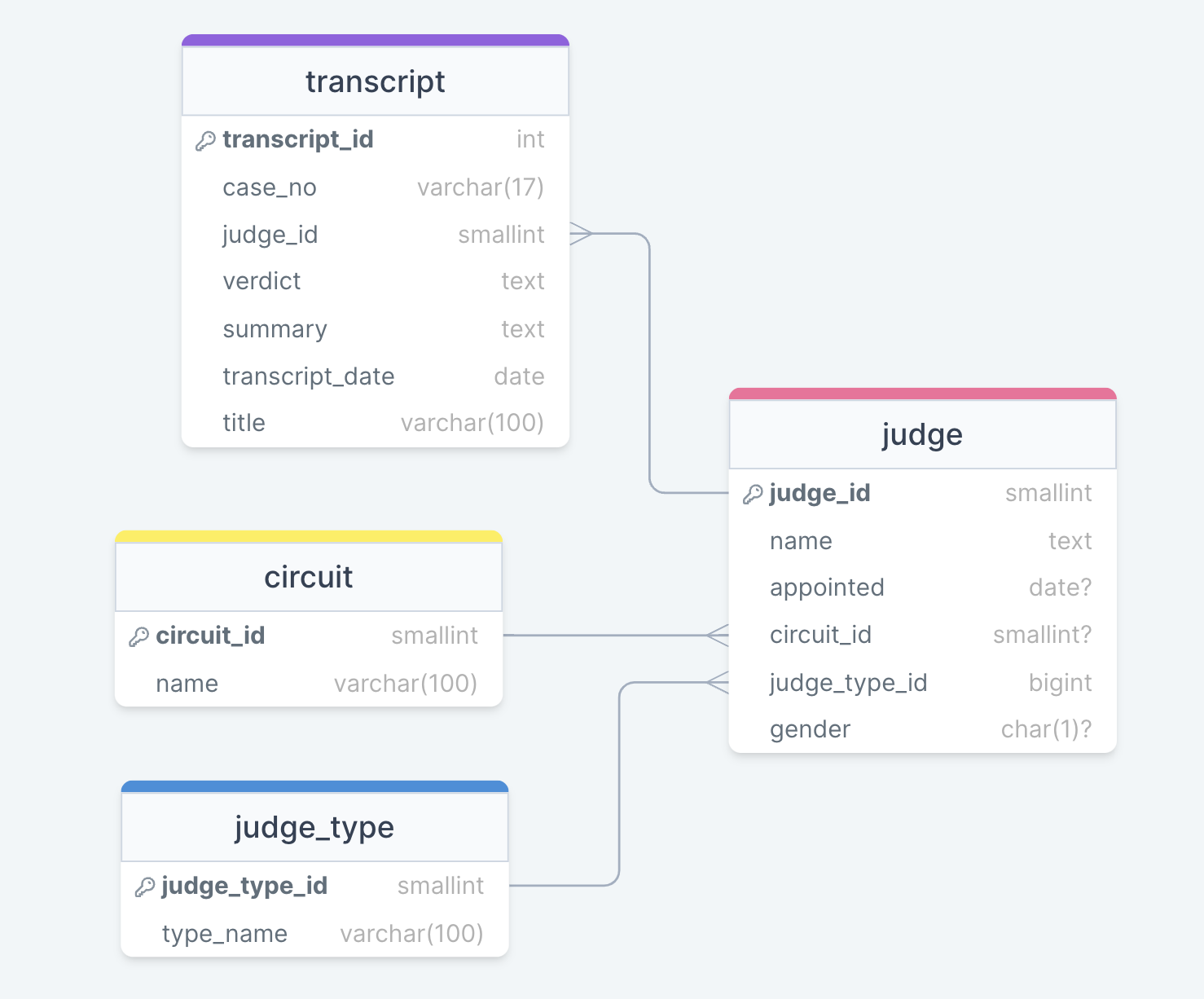
ERD
Dashboard Wireframe
Setup
To contribute to the project, follow these steps:
- Clone the repository.
- Set up the development environment as per the instructions in the
README.mdfile. - Start working on your assigned tasks or create a new one if needed.
- Submit a pull request once your changes are ready for review.