Tensorflow chatbot
(with seq2seq + attention + dict-compress + beam search + anti-LM + facebook messenger server)
[Update 2017-03-14]
- Upgrade to tensorflow v1.0.0, no backward compatible since tensorflow have changed so much.
- A pre-trained model with twitter corpus is added, just
./go_exampleto chat! (or preview my chat example)- You could start from tracing this
go_examplescript to know how things work!
Briefing
This is a seq2seq model modified from tensorflow example.
- The original tensorflow seq2seq has attention mechanism implemented out-of-box.
- And speedup training by dictionary space compressing, then decompressed by projection the embedding while decoding.
- This work add option to do beam search in decoding procedure, which usually find better, more interesting response.
- Added anti-language model to suppress the generic response problem of intrinsic seq2seq model.
- Imeplemented this deep reinforcement learning architecture as an option to enhence semantic coherence and perplexity of response.
- A light weight Flask server
app.pyis included to be the Facebook Messenger App backend.
In Layman's terms
I explained some detail about the features and some implementation tricks here.
Just tell me how it works
Clone the repository
git clone github.com/Marsan-Ma/tf_chatbot_seq2seq_antilm.gitPrepare for Corpus
You may find corpus such as twitter chat, open movie subtitle, or ptt forums from my chat corpus repository. You need to put it under path like:
tf_chatbot_seq2seq_antilm/works/<YOUR_MODEL_NAME>/data/train/chat.txtAnd hand craft some testing sentences (each sentence per line) in:
tf_chatbot_seq2seq_antilm/works/<YOUR_MODEL_NAME>/data/test/test_set.txtTrain the model
python3 main.py --mode train --model_name <MODEL_NAME>Run some test example and see the bot response
after you trained your model until perplexity under 50 or so, you could do:
python3 main.py --mode test --model_name <MODEL_NAME>[Note!!!] if you put any parameter overwrite in this main.py commmand, be sure to apply both to train and test, or just modify in lib/config.py for failsafe.
Start your Facebook Messenger backend server
python3 app.py --model_name <MODEL_NAME>You may see this minimum fb_messenger example for more details like setting up SSL, webhook, and work-arounds for known bug.
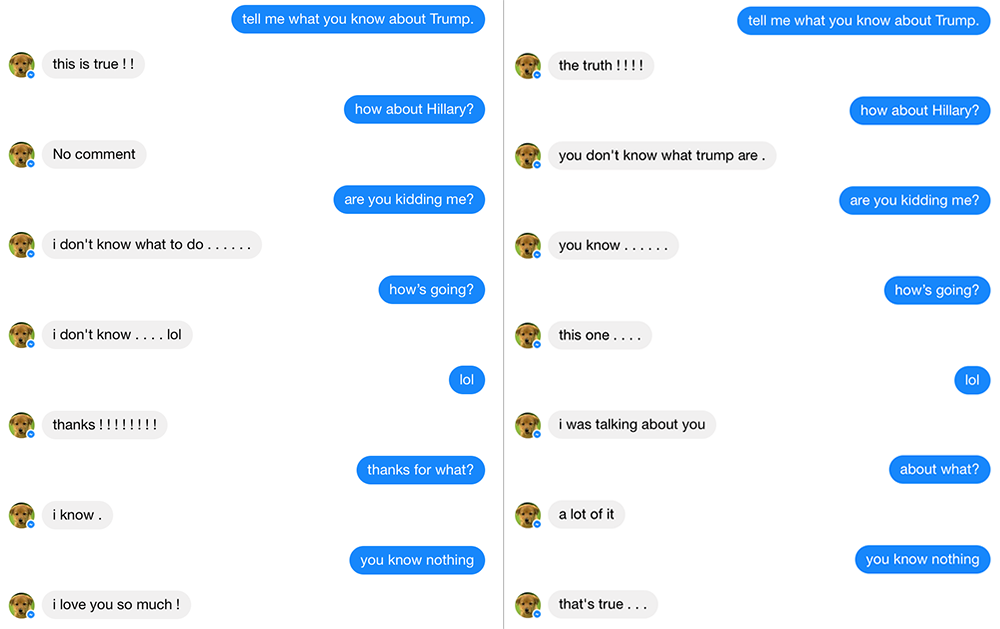
Here's an interesting comparison: The left conversation enabled beam search with beam = 10, the response is barely better than always "i don't know". The right conversation also used beam search and additionally, enabled anti-language model. This supposed to suppress generic response, and the response do seems better.
Deep reinforcement learning
[Update 2017-03-09] Reinforcement learning does not work now, wait for fix.
If you want some chance to further improve your model, here I implemented a reinforcement learning architecture inspired by Li et al., 2016. Just enable the reinforce_learn option in config.py, you might want to add your own rule in step_rf() function in lib/seq2seq_mode.py.
Note that you should train in normal mode to get a decent model first!, since the reinforcement learning will explore the brave new world with this pre-trained model. It will end up taking forever to improve itself if you start with a bad model.
Introduction
Seq2seq is a great model released by Cho et al., 2014. At first it's used to do machine translation, and soon people find that anything about mapping something to another thing could be also achieved by seq2seq model. Chatbot is one of these miracles, where we consider consecutive dialog as some kind of "mapping" relationship.
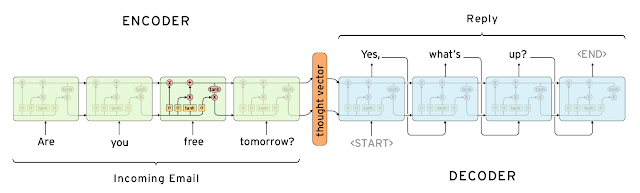
Here is the classic intro picture show the seq2seq model architecture, quote from this blogpost about gmail auto-reply feature.
The problem is, so far we haven't find a better objective function for chatbot. We are still using MLE (maximum likelyhood estimation), which is doing good for machine translation, but always generate generic response like "me too", "I think so", "I love you" while doing chat.
These responses are not informative, but they do have large probability --- since they tend to appear many times in training corpus. We don't won't our chatbot always replying these noncense, so we need to find some way to make our bot more "interesting", technically speaking, to increase the "perplexity" of reponse.
Here we reproduce the work of Li. et al., 2016 try to solve this problem. The main idea is using the same seq2seq model as a language model, to get the candidate words with high probability in each decoding timestamp as a anti-model, then we penalize these words always being high probability for any input. By this anti-model, we could get more special, non-generic, informative response.
The original work of Li. et al use MERT (Och, 2003) with BLEU as metrics to find the best probability weighting (the λ and γ in Score(T) = p(T|S) − λU(T) + γNt) of the corresponding anti-language model. But I find that BLEU score in chat corpus tend to always being zero, thus can't get meaningful result here. If anyone has any idea about this, drop me a message, thanks!
Parameters
There are some options to for model training and predicting in lib/config.py. Basically they are self-explained and could work with default value for most of cases. Here we only list something you need to config:
About environment
| name | type | Description |
|---|---|---|
| mode | string | work mode: train/test/chat |
| model_name | string | model name, affects your working path (storing the data, nn_model, result folders) |
| scope_name | string | In tensorflow if you need to load two graph at the same time, you need to save/load them in different namespace. (If you need only one seq2seq model, leave it as default) |
| vocab_size | integer | depends on your corpus language: for english, 60000 is good enough. For chinese you need at least 100000 or 200000. |
| gpu_usage | float | tensorflow gpu memory fraction used, default is 1 and tensorflow will occupy 100% of your GPU. If you have multi jobs sharing your GPU resource, make it 0.5 or 0.3, for 2 or 3 jobs. |
| reinforce_learn | int | set 1 to enable reinforcement learning mode |
About decoding
| name | type | default | Description |
|---|---|---|---|
| beam_size | int | 10 | beam search size, setting 1 equals to greedy search |
| antilm | float | 0 (disabled) | punish weight of anti-language model |
| n_bonus | float | 0 (disabled) | reward weight of sentence length |
The anti-LM functin is disabled by default, you may start from setting antilm=0.5~0.7 and n_bonus=0.05 to see if you like the difference in results.
Requirements
-
For training, GPU is recommended since seq2seq is a large model, you need certain computing power to do the training and predicting efficiently, especially when you set a large beam-search size.
-
DRAM requirement is not strict as CPU/GPU, since we are doing stochastic gradient decent.
-
If you are new to deep-learning, setting-up things like GPU, python environment is annoying to you, here are dockers of my machine learning environment:
(non-gpu version docker) / (gpu version docker)
References
Seq2seq is a model with many preliminaries, I've been spend quite some time surveying and here are some best materials which benefit me a lot:
-
The best blogpost explaining RNN, LSTM, GRU and seq2seq model: Understanding LSTM Networks by Christopher Olah.
-
This work sherjilozair/char-rnn-tensorflow helps me learn a lot about language model and implementation graph in tensorflow.
-
If you are interested in more magic about RNN, here is a MUST-READ blogpost: The Unreasonable Effectiveness of Recurrent Neural Networks by Andrej Karpathy.
-
The vanilla version seq2seq+attention: nicolas-ivanov/tf_seq2seq_chatbot. This will help you figure out the main flow of vanilla seq2seq model, and I build this repository based on this work.
TODOs
-
Currently I build beam-search out of graph, which means --- it's very slow. There are discussions about build it in-graph here and there. But unfortunately if you want add something more than beam-search, like this anti-LM work, you need much more than just beam search to be in-graph.
-
I haven't figure out how the MERT with BLEU can optimize weight of anti-LM model, since currently the BLEU is often being zero.