Python-crawler-grabs-China-Banking-Regulatory-Commission-statistical-information-report
本文仅用于学习参考:
项目下载链接:
初始url,即如下所示页面 目的:抓取网页中所有的文档标题以及doc,pdf下载链接,以及发布时间,发布日期等信息。
目的:抓取网页中所有的文档标题以及doc,pdf下载链接,以及发布时间,发布日期等信息。
分析流程: 【1】初始页面抓包得返回信息得json请求地址 【2】对数据进行提取过滤 【3】信息整合,构造下一页url,继续重复前三个步骤
本项目简单实现,就不多说了,可以拿去练手。
主要逻辑代码如下图所示: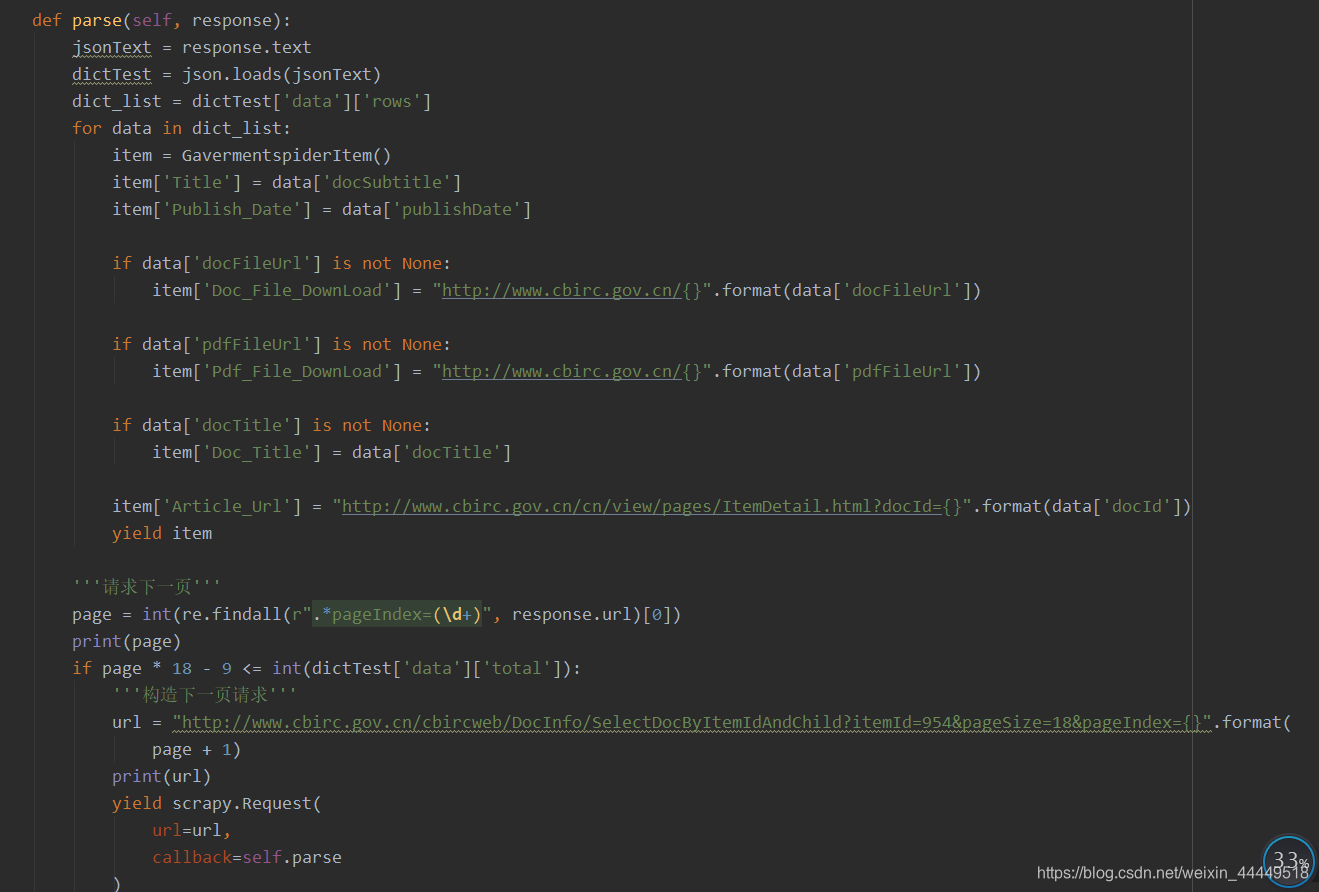 piplines:
piplines: 运行截图:
运行截图: 可以看到,速度还是不错的,大约13秒,抓取了55页信息,总计976条数据,并且看到信息也挺纯净的。
可以看到,速度还是不错的,大约13秒,抓取了55页信息,总计976条数据,并且看到信息也挺纯净的。