 Lukelluke
commented
3 years ago
Lukelluke
commented
3 years ago Do you get NAN result from the beginning?
In my personal operation, due to the GoogleDrive downloading problem, i get the CelebaA-64 separately, and put them in the same folder(./script/celeba_org/celeba), which contains (identity_CelebA.txt img_align_celeba.zip list_attr_celeba.txt list_bbox_celeba.txt list_eval_partition.txt list_landmarks_align_celeba.txt list_landmarks_celeba.txt)
then do as the instruction of README about preprocessing process `
-
python create_celeba64_lmdb.py --split train --img_path ./data1/datasets/celeba_org/celeba --lmdb_path ./data1/datasets/celeba_org/celeba64_lmdb
-
python create_celeba64_lmdb.py --split valid --img_path ./data1/datasets/celeba_org/celeba --lmdb_path ./data1/datasets/celeba_org/celeba64_lmdb
-
python create_celeba64_lmdb.py --split test --img_path ./data1/datasets/celeba_org/celeba --lmdb_path ./data1/datasets/celeba_org/celeba64_lmdb
`
No any other change.
And at training process: `
-
python train.py --data ./scripts/data1/datasets/celeba_org/celeba64_lmdb --root ./CHECKPOINT_DIR --save ./EXPR_ID --dataset celeba_64 \
--num_channels_enc 64 --num_channels_dec 64 --epochs 1000 --num_postprocess_cells 2 --num_preprocess_cells 2 \
--num_latent_scales 3 --num_latent_per_group 20 --num_cell_per_cond_enc 2 --num_cell_per_cond_dec 2 \
--num_preprocess_blocks 1 --num_postprocess_blocks 1 --weight_decay_norm 1e-1 --num_groups_per_scale 20 \
--batch_size 4 --num_nf 1 --ada_groups --num_process_per_node 1 --use_se --res_dist --fast_adamax `
Besides of the address of the data that I put change to the corresponding address, the only wrong I countered was the parameter --num_process_per_node 1 means the GPU number that available.
Here is some provisional result:

And for 1024*1024 pic:
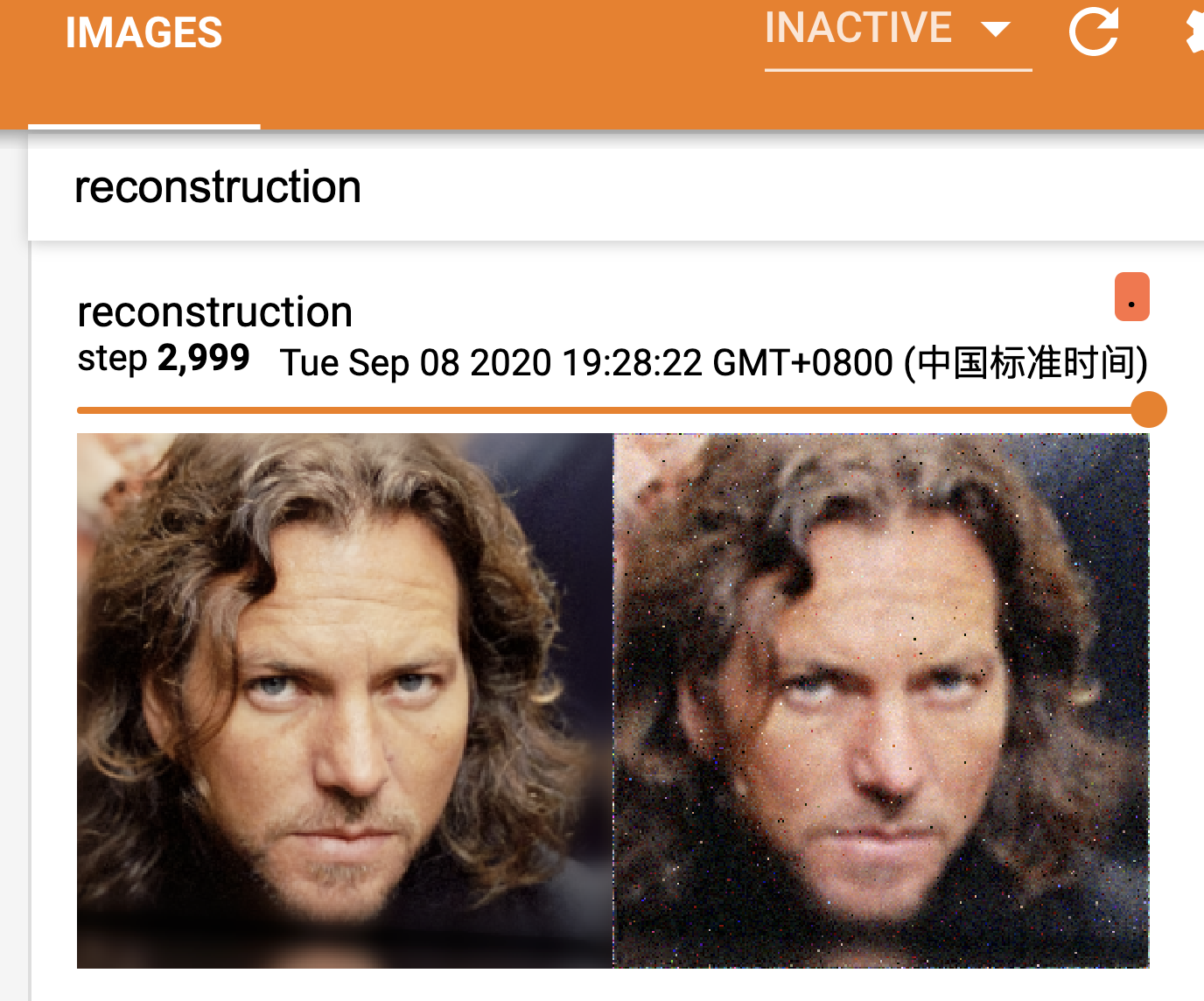

🌟 Hoping that my expression can do any help for you and any other counter problems!
 arash-vahdat
arash-vahdat kaushik333
kaushik333
Hello Dr. Vahdat,
This is indeed impressive work !!! However I am struggling with the training process.
Using Pytorch 1.6.0 with cuda 10.1
Training using 4 (Not V-100) GPUs of size ~12GB each. Reduced batch size to 8 to fit memory. No other changes apart from this. Followed the instructions exactly as given in Readme. But the training logs show that I am get "nan" losses
Is there any other pre-processing step I need to do for the dataset? Perhaps any other minor detail which you felt was irrelevant to mention in the readme? Any help you can provide is greatly appreciated.