RAG-Book
本项目为书籍《大模型RAG实战》的代码以及资料汇总。
项目介绍
-
adavanced rag(一些常见的高级RAG技巧)
-
query_enhancement (包含问题改写,step_back,子问题等)
-
chunk_enhancement (包括压缩,问题猜测等)
-
retrieval_enhancement (混搜等,metadata filter等,待更新~)
-
generation_enhancement (溯源等,待更新~)
-
-
agentic rag (将LLM当作驱动agent的引擎,召回函数当作工具,可以完成单步或者多步规划)
-
graphrag (对nano-graphrag进行了一些修改,主要修改prompt为中文,以及一些因为模型输出能力上的bug,生成模型向量模型替换成私有的模型)
-
rag blog (近期的一些rag博客)
-
chapter 7
- 71_72_code(langchain demo)
-
chapter 8
-
make_qa_data (构造训练数据)
-
train_embedding_model (思域向量模型训练)
-
finetune_qwen_llm (大模型微调)
-
rag_end2end(联合训练)
-
宣传文稿:RAG的范式变迁
ChatGPT爆火之后,以ChatPDF为首的产品组合掀起了知识库问答的热潮。
在过去一整年中,大多数人都在完成RAG系统到高级RAG系统的迭代升级。但是技术发展是迅速的,如何深入了解RAG的发展,做出更好的RAG系统,其实还是非常困难的。

大模型爆火后的RAG系统发展,大体可以将其分为3个阶段,初级、高级、超级。初级阶段更多的是搭建起系统的pipeline;高级阶段是在召回生成测修修补补,根据badcase反推流程上的优化技巧;超级对应了从Agentic RAG、RAG不存在了、多模态RAG、结构化RAG、GraphRAG、MemoryRAG等技术飞速发展的阶段。
S1 初级RAG
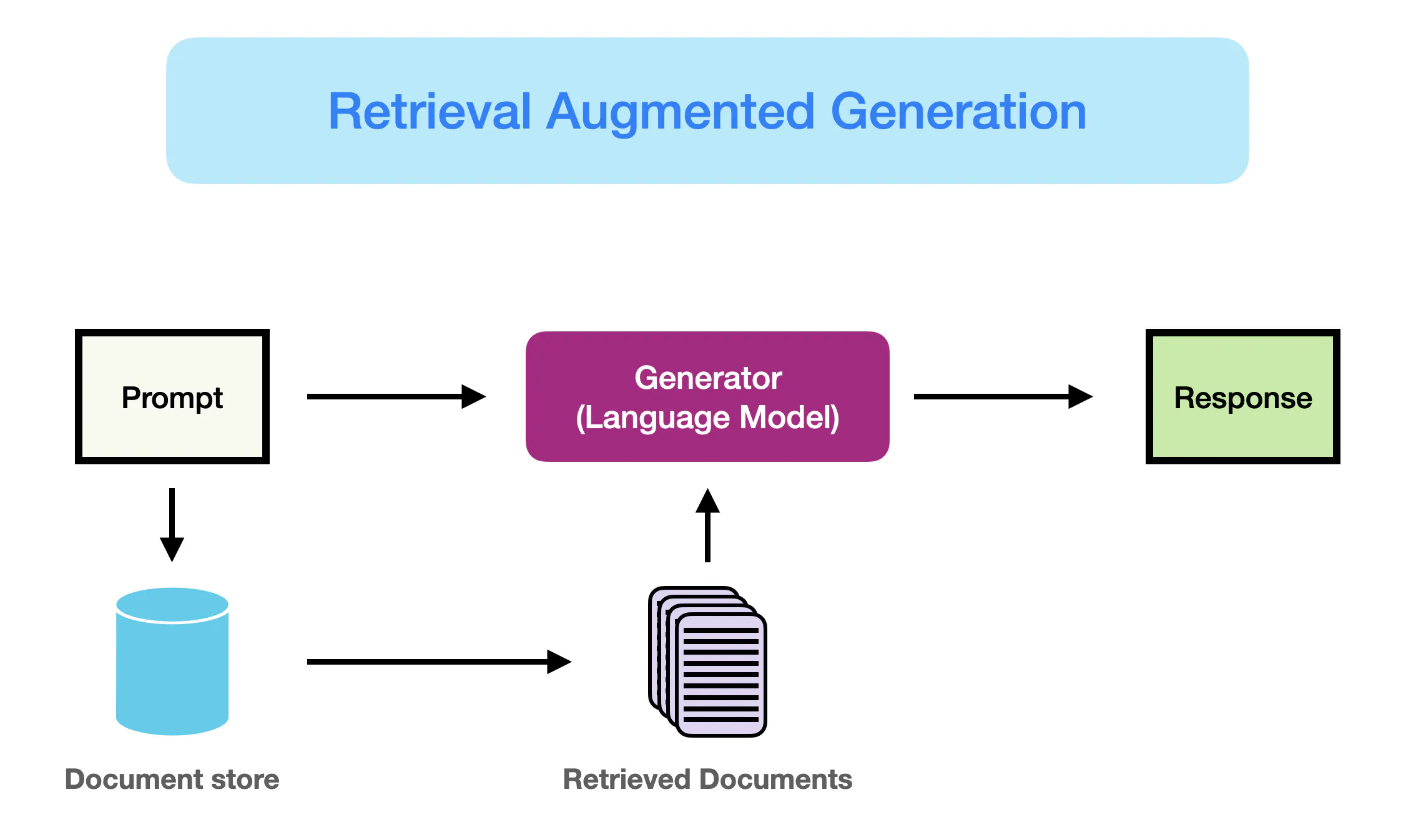
S1阶段处于23年元旦前后,最先在Github出现了一批尝试去复现chatpdf的项目,他们通过对知识库文档进行定长分块建立索引。然后使用用户query去索引中召回相关的文档片段,结合预定义的prompt模板,让LLM生成问题相关的答案。
其中用到的向量和LLM模型,闭源一般使用openai ada 002 + chatgpt。开源中文测的则比较稀缺,常见的如simbert/text2vec + chatglm v1 6b等。
大体的一个流程图如下:
S2 高级RAG
S2阶段横跨23年整年的时间,大体上可以分为模型测和策略测。
模型测
召回模型测:开源社区现在项链模型发力,一些针对QA分布的向量模型开源,如M3E,BGE等。
生产模型测:国产大模型百花齐放,百川、书生、千问、智谱等。
策略测
策略测在卷3大块的内容
- 如何保证更好的文档切分?这里诞生了很多的解析,切分,索引构建技巧。
- 解析测,简单的从纯文本识别,到后来更复杂的借助版式识别+OCR的方式,还要针对表格,图片等单独处理
- 切分方面,从滑动窗口定长切分到语义,模块化切分等。
- 索引构建的一些技巧主要是为了应对chunk切分后的信息丢失问题,常见的比如,保留前后块的索引,文档级别的索引构建等。
- 如何召回的更好?召回测的一个出发点是,用来召回的query并非一定是用户的输入query。对此我们可以一下子想起来如query改写,hyde,子问题,step-back等常见策略。当然也有混合搜索这类不属于这个范畴的技巧。
- 如何生成的更好?生成测的一个出发点是,用来生成的内容并非一定是召回的query。从这一点我们也可以想起来如召回内容压缩,内容rerank,溯源,map-reduce等一些策略。

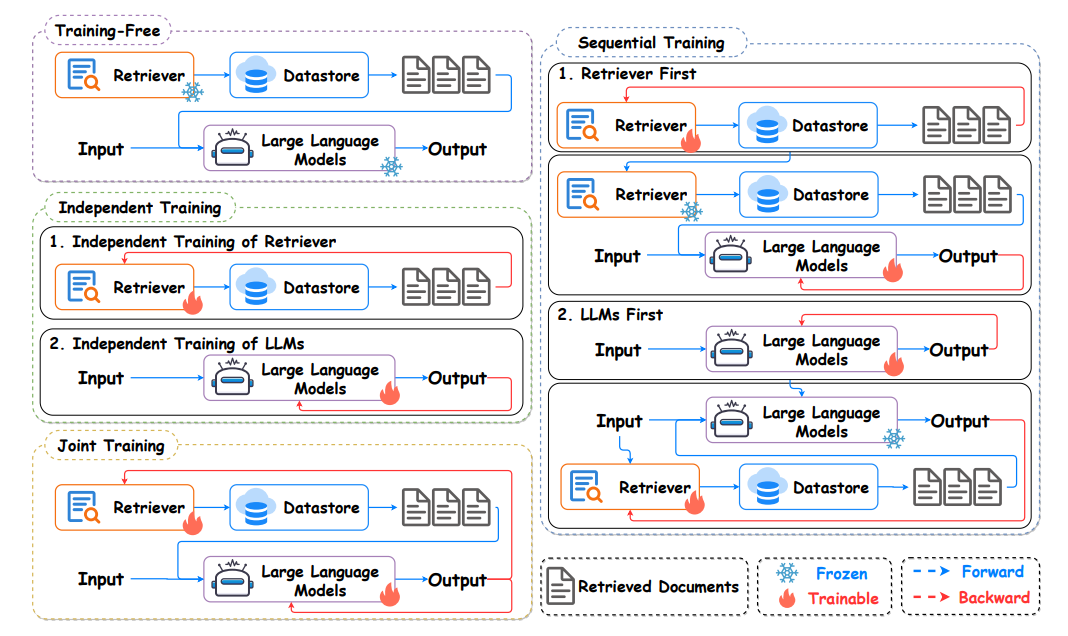
模型微调测
RAG系统的主要模型还是嵌入模型+生成模型。因此二者的训练方式,也产生了几个不同的大类别。最简单的二者直接使用开源模型,称为Traning free的方式;如果是针对私有化的数据进行训练这2个模型,产生3种训练方式:
- 方式一:分别独立训练 (Independent Training)
- 方式二:顺序训练 (Sequential Training),又因为模块的先后,分为LLM First / Retriever First 2种
- 方式三:联合训练(Joint Training)
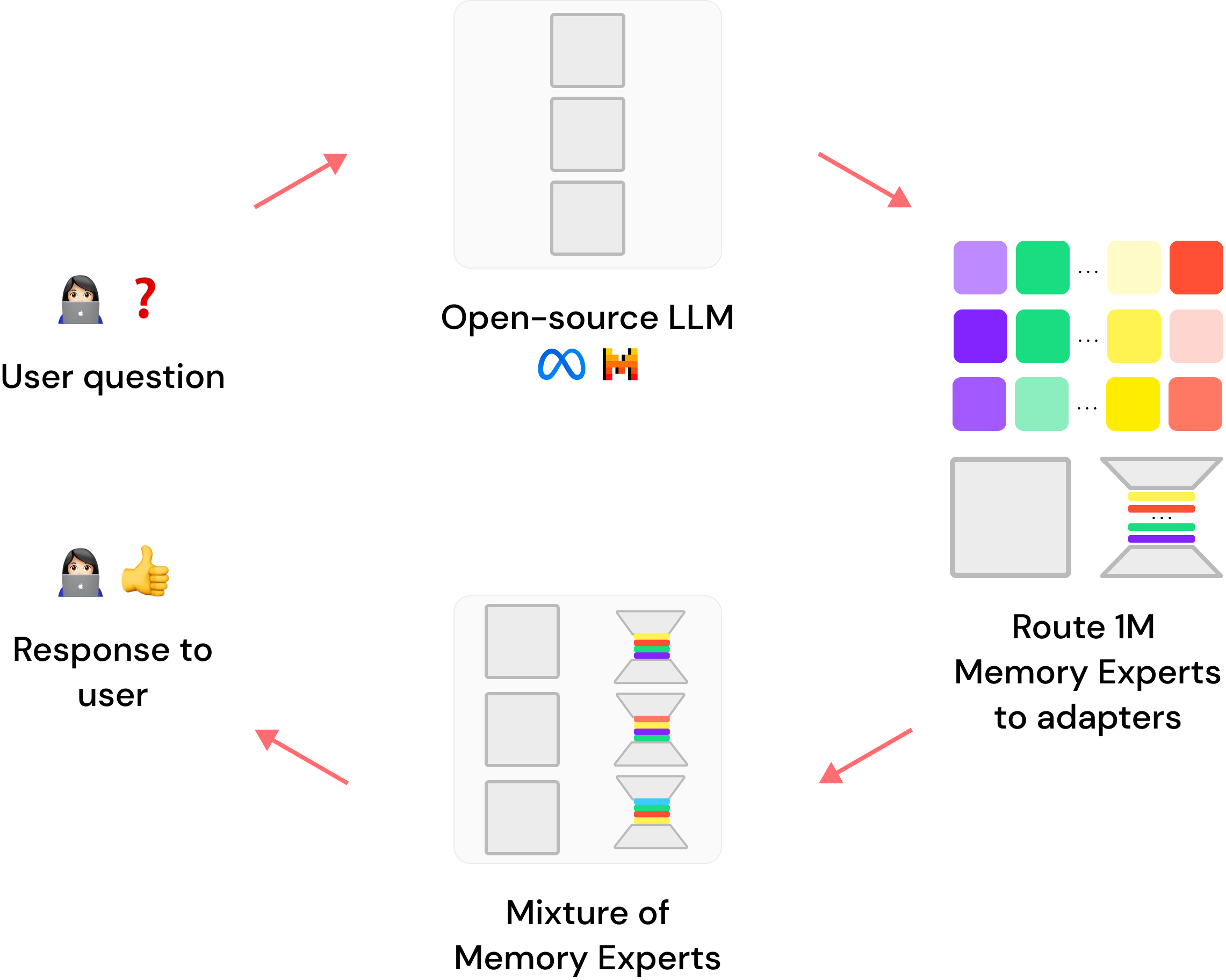
S3 超级RAG
S3阶段处于23年底一直到现在,这个阶段RAG的概念几乎是2个月变一次。
23年底,24年初,开源的大模型已经出现了如Yi-34B,Qwen-72B等具备长上下文能力且效果优异的大模型。RAG的发展注定需要往当时火热的Agent测靠拢。
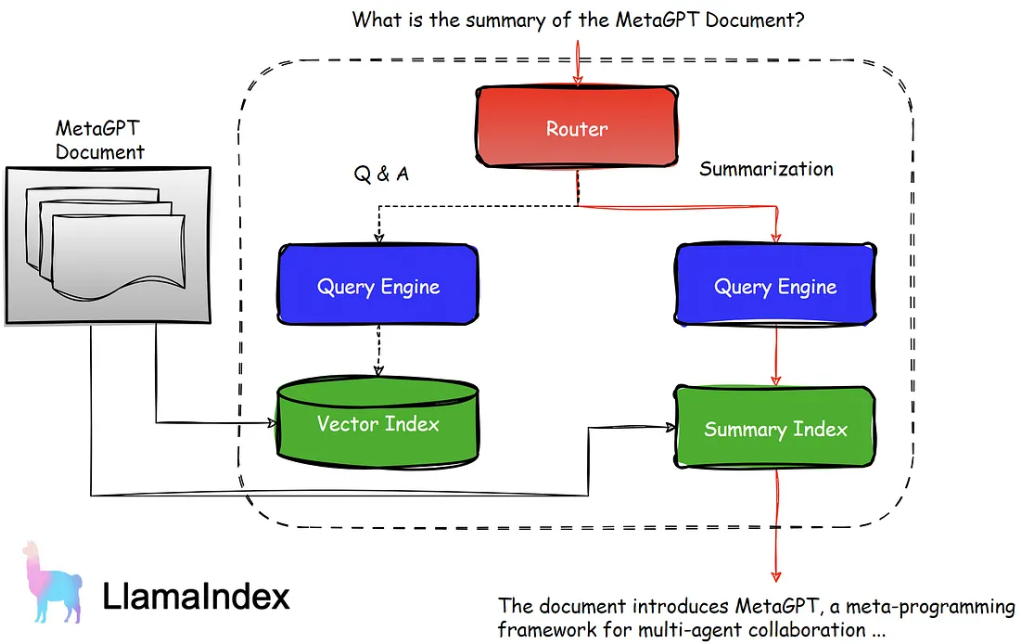
Agent的核心为引擎+工具。引擎对整个流程做出决策,如是否调用某个知识库搜索知识,是否需要对结果进行反思重新迭 代等。一个简单的Agentic RAG系统如下图:
多模态RAG,结构化RAG,属于小而美的范畴。可能一方面是多模态还没有完全进入工业界,结构化RAG属于NL2SQL的范畴。对于这2个整体上与传统的RAG差异不大,区别在于,多模态流转的中间形态可能是图片,使用clip之类的图文检索模型召回,VL模型进行答案生成。结构化RAG的差异仅在召回测,使用sql、dsl等方式进行结构化数据库的召回。
24年上半年,部分厂商的RAG系统,在探索新的方向。如contextual.ai发文介绍他们的RAG2.0系统,虽然介绍博客的内容主要是联合训练。斯坦福的大佬们发布了RAPTOR,尝试通过层次的聚类来让RAG索引具备更高级的信息。
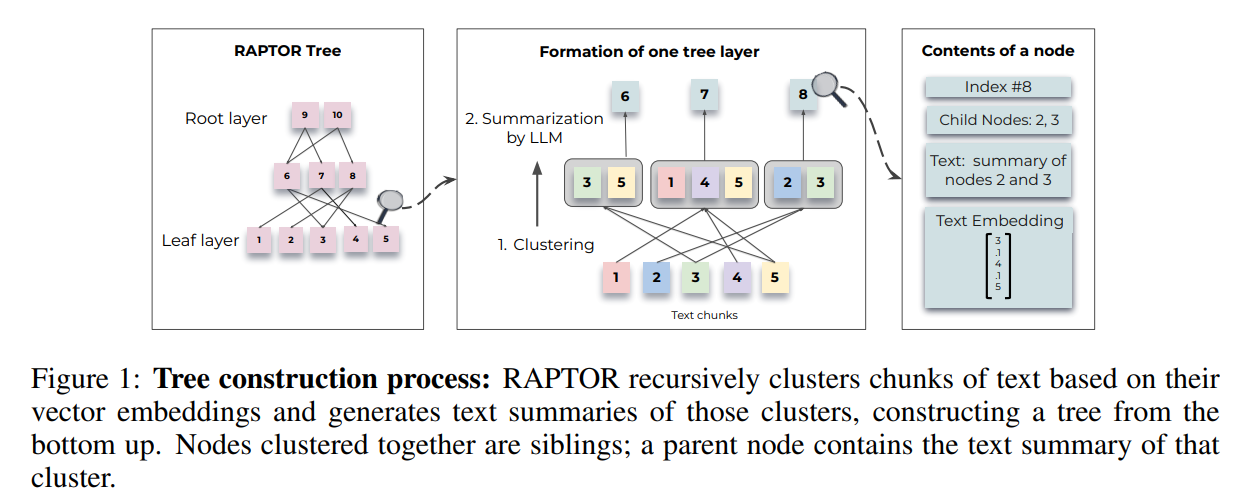
越来越多的开源框架,在往Agentic RAG方面发展,当然最常见的还是结合self-reflection,self-rag,crag的Agentic RAG系统。
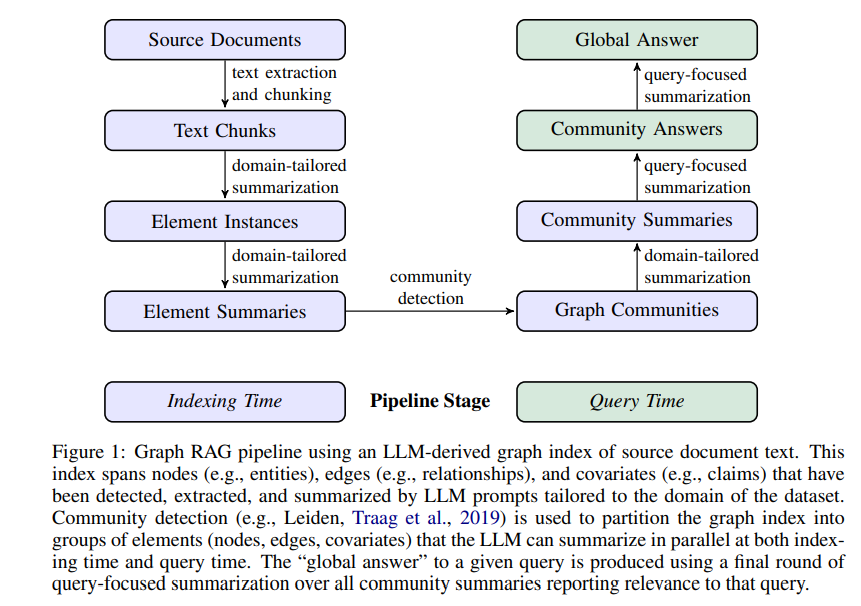
24年中,微软开源了GraphRAG的项目代码,无数的公众号在炒作这个图谱集合的RAG系统。相比于RAPTOR,GraphRAG在底层的chunk层更拉通,前者的聚类仅限于文档内,在逐级往上到文档间。而基于图谱的RAG在文档间的chunk之间可能会存在实体的连接,从而社区之类之后可以让聚类的社区信息,更好的跨不同的文档。整体上,确实能丰富RAG系统的索引构建,也可以结合传统的高级RAG,实现一个更好的hybird RAG系统。
当然24年也有很多RAG不存在的说法,如很多的论文在评估Long Context(LC)大模型与RAG系统准确率的高低之时,RAG系统都处于下风。同时还有一些特殊的开闭源产品,比较常见的就是将知识融合进外挂参数中,最早的如Lamini的Memory Tunning,最近的如智源的MemoRAG。