![]()
## Oryx MLLM: On-Demand Spatial-Temporal Understanding at Arbitrary Resolution
Zuyan Liu*,1,2 Yuhao Dong*,2,3 Ziwei Liu3 Winston Hu2 Jiwen Lu1,✉ Yongming Rao2,1,✉
1Tsinghua University 2Tencent 3S-Lab, NTU
* Equal Contribution ✉ Corresponding Author
--- **Project Page:** [](https://oryx-mllm.github.io) **arXiv Paper:** [](https://arxiv.org/abs/2409.12961) **Model Checkpoints**: [](https://huggingface.co/collections/THUdyh/oryx-66ebe5d0cfb61a2837a103ff) **Oryx SFT Data**: Collected from open-source datasets, prepared data comming soon ## 📢 News - [20/09/2024] 🔥 **🚀Introducing [Oryx](https://oryx-mllm.github.io)!** The Oryx models (7B/34B) support **on-demand visual perception**, achieve new state-of-the-art performance across image, video and 3D benchmarks, even surpassing advanced commercial models on some benchmarks. * [[Paper]](https://arxiv.org/abs/2409.12961): Detailed introduction of on-demand visual perception, including **native resolution perception** and **dynamic compressor**! * [[Checkpoints]](https://huggingface.co/collections/THUdyh/oryx-66ebe5d0cfb61a2837a103ff): Try our advanced model on your own. * [[Scripts]](https://github.com/Oryx-mllm/oryx/blob/main/scripts): Start training models with customized data. ## Introducing Oryx **Oryx is a unified multimodal architecture for the spatial-temporal understanding of images, videos, and multi-view 3D scenes. Oryx offers an on-demand solution to seamlessly and efficiently process visual inputs with arbitrary spatial sizes and temporal lengths. Our model achieve strong capabilities in image, video, and 3D multimodal understanding simultaneously.** ### Main idea of On-Demand Multimodal Understanding

### Overview of Oryx Architecture
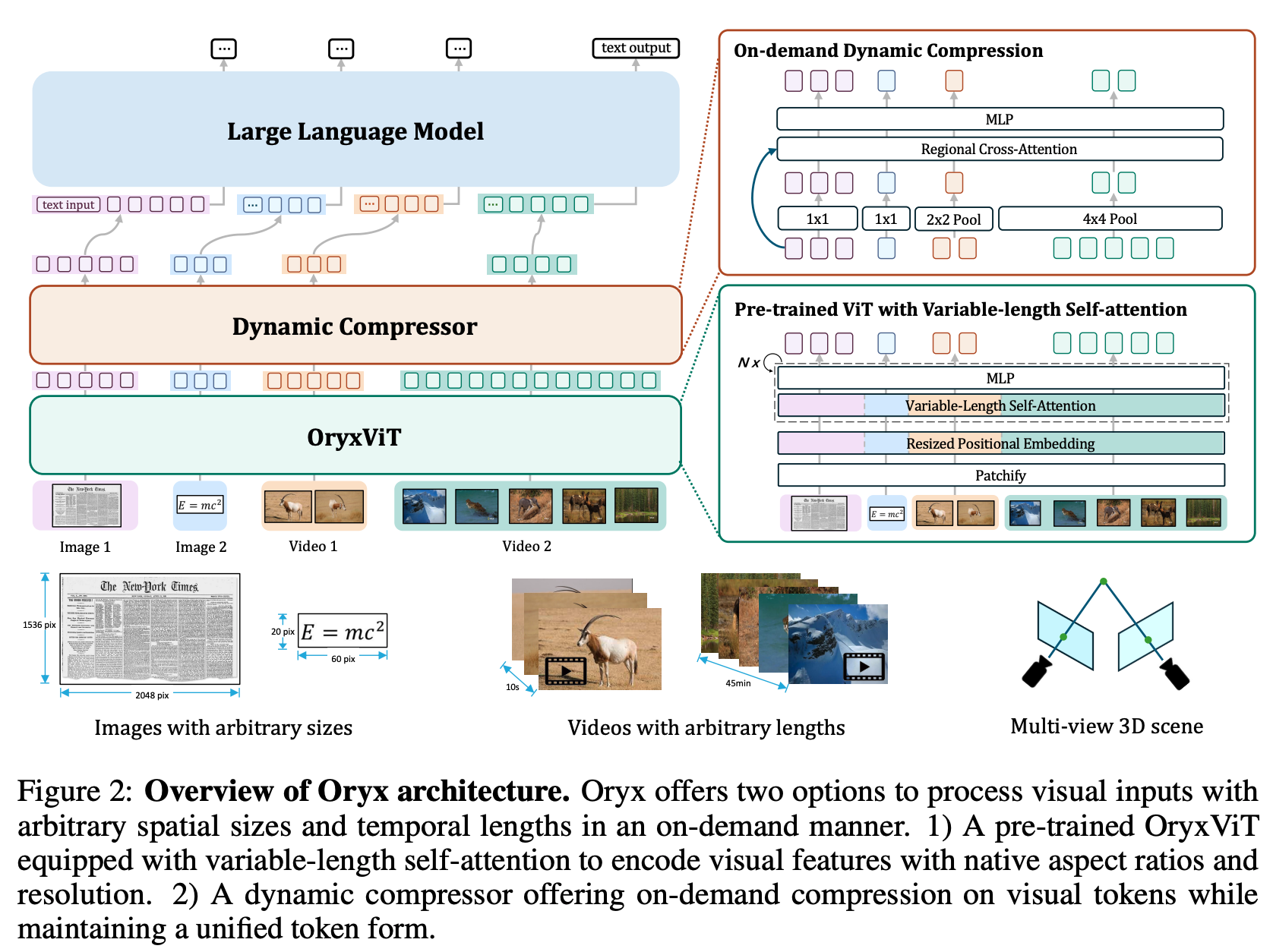
## TODO List
- [x] Release all the model weights.
- [x] Release OryxViT model.
- [x] Demo code for generation.
- [x] All the training and inference code.
- [ ] Evaluation code for image, video and 3D multi-modal benchmark.
- [ ] Oryx SFT Data.
- [ ] Oryx chatbox.
- [ ] Enhanced Oryx model with latest LLM base models and better SFT data.
- [ ] Introducing our explorations for OryxViT.
## Generation Demo
You can try the generation results of our strong Oryx model with the following steps:
#### 1. Download the [Oryx](https://huggingface.co/collections/THUdyh/oryx-66ebe5d0cfb61a2837a103ff) model from our huggingface collections.
#### 2. Download the [Oryx-ViT](https://huggingface.co/THUdyh/Oryx-ViT) vision encoder.
#### 3. Replace the path for "mm_vision_tower" in the config.json with your local path for Oryx-ViT. (We will simplify step 1, 2 and 3 in an automatically manner soon.)
#### 4. Modify the model path and run the inference script with your own video to test our model.
```python
python inference.py
```
## Training Instructions
### Installation
#### 1. **Clone this repository:**
```bash
git clone https://github.com/Oryx-mllm/oryx
cd oryx
```
#### 2. **Install the required package:**
```bash
conda create -n oryx python=3.10 -y
conda activate oryx
pip install --upgrade pip
pip install -e
```
### Preparation
#### 3. **Prepare training data:**
🚧 We will release the instruction for collecting training data soon. We will also release our prepared data in patches.
### Training
#### 4. **Training your own model:**
Modify the following lines in the scripts at your own environments:
```bash
export PYTHONPATH=/PATH/TO/oryx:$PYTHONPATH
VISION_TOWER='oryx_vit:PATH/TO/oryx_vit_new.pth'
DATA="PATH/TO/DATA.json"
MODEL_NAME_OR_PATH="PATH/TO/7B_MODEL"
```
Scripts for training Oryx-7B
```bash
bash scripts/train_oryx_7b.sh
```
Scripts for training Oryx-34B
```bash
bash scripts/train_oryx_34b.sh
```
## Citation
If you find it useful for your research and applications, please cite our paper using this BibTeX:
```bibtex
@article{liu2024oryx,
title={Oryx MLLM: On-Demand Spatial-Temporal Understanding at Arbitrary Resolution},
author={Liu, Zuyan and Dong, Yuhao and Liu, Ziwei and Hu, Winston and Lu, Jiwen and Rao, Yongming},
journal={arXiv preprint arXiv:2409.12961},
year={2024}
}
```
## Acknowledgement
- Our codebase is conducted on [LLaVA](https://github.com/LLaVA-VL/LLaVA-NeXT)
- Thanks to [lmms-eval](https://github.com/EvolvingLMMs-Lab/lmms-eval) team, for building such a usefule evaluation system!