Gaussian Deja-vu 🐈⬛
🚀 Project Homepage
- Author: Peizhi Yan
- Date Updated: 11-10-2024
📺 Demo Videos (Click to Watch)

Notations: ⭐ Important ❓ Question
⭐ We suggest shallow copy our repo:
git clone --depth 1 https://github.com/PeizhiYan/gaussian-dejavu✨ Milestones
11-06-2024: Code and avatar viewer demo released.
💚 Citation
This is the official code repo for our "Gaussian Deja-vu" (accepted for WACV 2025 in Round 1).
Please consider citing our work if you find this code useful.
@article{yan2024gaussian,
title={Gaussian Deja-vu: Creating Controllable 3D Gaussian Head-Avatars with Enhanced Generalization and Personalization Abilities},
author={Yan, Peizhi and Ward, Rabab and Tang, Qiang and Du, Shan},
journal={arXiv preprint arXiv:2409.16147},
year={2024}
}🌱 Todos
- [x] Avatar viewer demo.
- [ ] Test on another computer with Ubuntu system.
- [x] Convert Mediapipe's blendshapes to FLAME's expression and poses.
- [x] Video head avatar driving demo.
- [x] Test on Windows system.
🧸 How to Use
⭐ Note that, please set the working directory in the Python code before running it.
For example:
import os, sys
os.environ['CUDA_VISIBLE_DEVICES'] = '0' # Set the visible CUDA, here we use the second GPU
WORKING_DIR = '/home/peizhi/Documents/gaussian-dejavu/'
os.chdir(WORKING_DIR) # change the working directory to the project's absolute pathPrepare Training Data
Please follow https://github.com/PeizhiYan/flame-head-tracker and our example ./examples/Personal-Video-Precessing.ipynb to pre-process your video.
When collecting your video, please consider following this guidance to achieve good reconstruction results ./assets/personal_video_collection_procedure.pdf
Personalize Head Avatar
Please follow our example to train the personalized head avatar model:
Avatar Viewer Demo
python run_avatar_viewer.pyWe have prepared some head avatar models in the folder ./saved_avatars/. Please note that, imavatar models were trained on the IMAvatar dataset (https://github.com/zhengyuf/IMavatar).
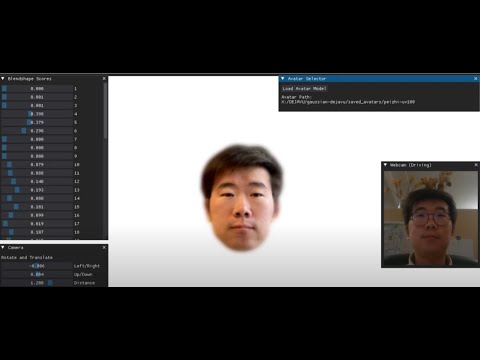
Realtime Avatar Webcam-Driving Demo
python run_avatar_driver.pyPipeline Diagram:
We use Mediapipe's face blendshape scores to drive our avatar. We use pre-calculated mappings (https://github.com/PeizhiYan/mediapipe-blendshapes-to-flame) to derive the blendshape scores to FLAME's expression coefficients, jaw pose and eye pose.

🟠 Environment Setup
Prerequisites:
- GPU:
- Nvidia GPU with >= 6GB memory (recommend > 8GB).
- Training needs better GPU, >= 24GB memory is recommended. We tested the code on Nvidia A6000 (48GB) GPU.
- We tested inference on RTX3070.
- OS:
- Ubuntu Linux is highly recommended (we tested on 22.04 LTS and 24.04 LTS).
- We also tested running the inference code on Windows system. However, setting up the environment might be a bit more complex.
⭐ We also suggest you to follow this repo https://github.com/ShenhanQian/GaussianAvatars to setup the environment. Otherwise, you can follow the following steps:
Click to expand ⬇️
### Step 1: Create a conda environment. ``` conda create --name dejavu -y python=3.10 conda activate dejavu ``` ### Step 2: Install necessary libraries. #### Nvidia CUDA compiler (11.7) ``` conda install -c "nvidia/label/cuda-11.7.1" cuda-toolkit ninja # (Linux only) ---------- ln -s "$CONDA_PREFIX/lib" "$CONDA_PREFIX/lib64" # to avoid error "/usr/bin/ld: cannot find -lcudart" # Install NVCC (optional, if the NVCC is not installed successfully try this) conda install -c conda-forge cudatoolkit=11.7 cudatoolkit-dev=11.7 ``` After install, check NVCC version (should be 11.7): ``` nvcc --version ``` #### PyTorch (2.0 with CUDA) ``` pip install torch==2.0.1 torchvision --index-url https://download.pytorch.org/whl/cu117 ``` Now let's test if PyTorch is able to access CUDA device, the result should be ```True```: ``` python -c "import torch; print(torch.cuda.is_available())" ``` #### Some Python packages ``` pip install -r requirements.txt ``` **Note that**, by this time we have tested the following versions of ```nvdiffrast``` and ```pytorch3d```: - nvdiffrast == **0.3.1** - pytorch3d == **0.7.8** #### Troubleshoot (Linux) Note that the NVCC needs g++ < 12: ``` sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-11 50 sudo update-alternatives --install /usr/bin/g++ g++ /usr/bin/g++-11 50 sudo update-alternatives --install /usr/bin/c++ c++ /usr/bin/g++-11 50 ``` If there is problem with **nvdiffrast**, check whether it is related to the EGL header file in the error message. If it is, install the EGL Development Libraries (for Ubuntu/Debian-based systems): ```bash sudo apt-get update sudo apt-get install libegl1-mesa-dev ``` Then, uninstall nvdiffrast and reinstall it.⭐ Download some necessary model files.
Because of copyright concerns, we cannot re-share any of the following model files. Please follow the instructions to download the necessary model file.
-
Download
FLAME 2020 (fixed mouth, improved expressions, more data)from https://flame.is.tue.mpg.de/ and extract to./models/FLAME2020- Note that, the
./models/head_template.objis the FLAME's template head mesh with some modifications we made. Because it is an edited version, we have to put it here. But remember to request the FLAME model from their official website before using it! The copyright (besides the modifications we made) belongs to the original FLAME copyright owners https://flame.is.tue.mpg.de
- Note that, the
-
Download
face_landmarker.taskfrom https://storage.googleapis.com/mediapipe-models/face_landmarker/face_landmarker/float16/1/face_landmarker.task, rename asface_landmarker_v2_with_blendshapes.task, and save at./models/ -
Download our network weights and save to
./models/dejavu_network.pt- Option 1 (from UBC ECE's server): https://people.ece.ubc.ca/yanpz/DEJAVU/dejavu_network.pt
- Option 2 (from Github): https://github.com/PeizhiYan/models_repo/blob/main/gaussian_dejavu/dejavu_network.pt
-
(Optional: for demo) Download pre-trained avatars and extract to
./saved_avatars/- Option 1 (from UBC ECE's server): https://people.ece.ubc.ca/yanpz/DEJAVU/example_avatars.zip
- Option 2 (from Github): https://github.com/PeizhiYan/models_repo/blob/main/gaussian_dejavu/
The structure of ./models should be:
./models/
├── dejavu_network.pt
├── face_landmarker_v2_with_blendshapes.task
├── FLAME2020
│ ├── female_model.pkl
│ ├── generic_model.pkl
│ ├── male_model.pkl
│ └── Readme.pdf
├── head_template.obj
├── landmark_embedding.npy
├── mediapipe_to_flame
│ ├── mappings
│ │ ├── bs2exp.npy
│ │ ├── bs2eye.npy
│ │ └── bs2pose.npy
│ ├── MP2FLAME.py
│ └── README.md
├── uv_face_weights.npy
├── uv_init_opacity_weights.npy
├── uv_llip_mask.jpg
└── uv_position_weights.npy⚖️ Disclaimer
This code is provided for research use only. All models, datasets, and external code used in this project are the property of their respective owners and are subject to their individual copyright and licensing terms. Please strictly adhere to these copyright requirements.
For commercial use, you are required to collect your own dataset and train the model independently. Additionally, you must obtain the necessary commercial licenses for any third-party dependencies included in this project.
This code and the weights are provided "as-is" without any express or implied warranties, including, but not limited to, implied warranties of merchantability and fitness for a particular purpose. We make no guarantees regarding the accuracy, reliability, or fitness of the code and weights for any specific use. Use of this code and weights is entirely at your own risk, and we shall not be liable for any claims, damages, or liabilities arising from their use.