vrata




API gateway implemented in PHP and Lumen. Currently only supports JSON format.
Preface
API gateway is an important component of microservices architectural pattern – it's a layer that sits in front of all your services. Read more
Overview
Vrata (Russian for 'gates') is a simple API gateway implemented in PHP7 with Lumen framework
Introductory blog post in English, in Russian
Requirements and dependencies
- PHP >= 7.0
- Lumen 5.3
- Guzzle 6
- Laravel Passport (with Lumen Passport)
- Memcached (for request throttling)
Running as a Docker container
Ideally, you want to run this as a stateless Docker container configured entirely by environment variables. Therefore, you don't even need to deploy this code anywhere yourself - just use our public Docker Hub image.
Deploying it is as easy as:
$ docker run -d -e GATEWAY_SERVICES=... -e GATEWAY_GLOBAL=... -e GATEWAY_ROUTES=... pwred/vrataWhere environment variables are JSON encoded settings (see configuration options below).
Configuration via environment variables
Ideally you won't need to touch any code at all. You could just snap the latest Docker image, set environment variables and done. API gateway is not a place to hold any business logic, API gateway is a smart proxy that can discover microservices, query them and process their responses with minimal adjustments.
Terminology and structure
Internal structure of a typical API gateway - microservices setup is as follows:
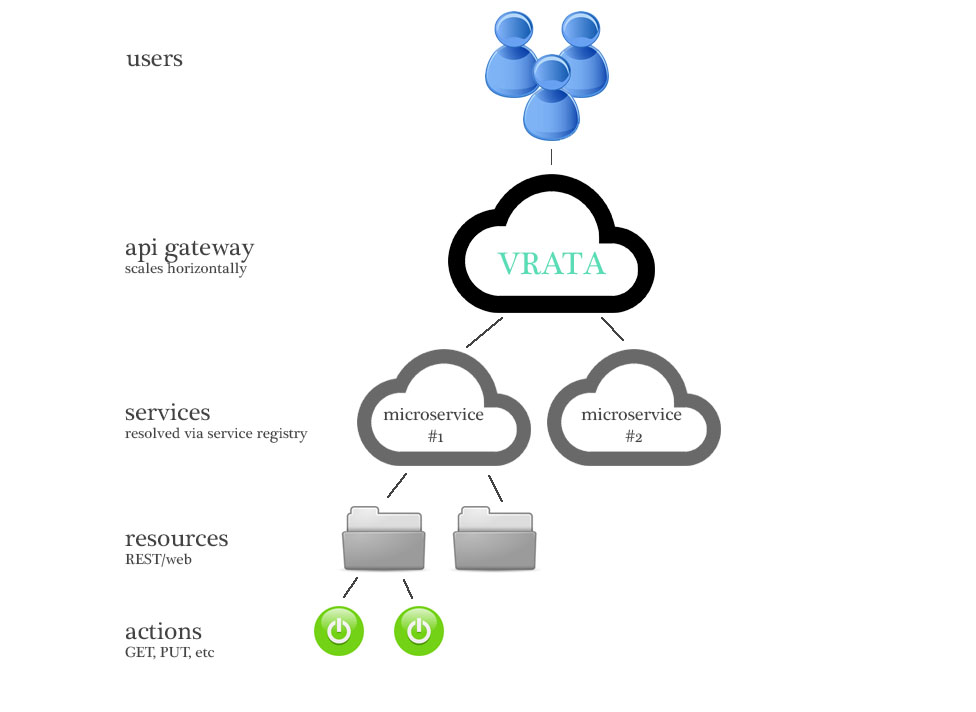
Since API gateway doesn't have any state really it scales horizontally very well.
Lumen variables
CACHE_DRIVER
It's recommended to set this to 'memcached' or another shared cache supported by Lumen if you are running multiple instances of API gateway. API rate limitting relies on cache.
DB_DATABASE, DB_HOST, DB_PASSWORD, DB_USERNAME, DB_CONNECTION
Standard Lumen variables for your database credentials. Use if you keep users in database. See Laravel/Lumen documentation for the list of supported databases.
APP_KEY
Lumen application key
Gateway variables
PRIVATE_KEY
Put your private RSA key in this variable
You can generate the key with OpenSSL:
$ openssl genrsa -out private.key 4096Replace new line characters with \n:
awk 1 ORS='\\n' private.keyPUBLIC_KEY
Put your public RSA key in this variable
Extract public key using OpenSSL:
$ openssl rsa -in private.key -pubout > public.keyReplace new line characters with \n:
awk 1 ORS='\\n' public.keyGATEWAY_SERVICES
JSON array of microservices behind the API gateway
GATEWAY_ROUTES
JSON array of extra routes including any aggregate routes
GATEWAY_GLOBAL
JSON object with global settings
Logging
Currently only LogEntries is supported out of the box. To send nginx and Lumen logs to LE, simply set two environmetn variables:
LOGGING_ID
Identification string for this app
LOGGING_LOGENTRIES
Your user key with LogEntries
Features
- Built-in OAuth2 server to handle authentication for all incoming requests
- Aggregate queries (combine output from 2+ APIs)
- Output restructuring
- Aggregate Swagger documentation (combine Swagger docs from underlying services) *
- Automatic mount of routes based on Swagger JSON
- Sync and async outgoing requests
- DNS service discovery
Installation
You can either do a git clone or use composer (Packagist):
$ composer create-project poweredlocal/vrataFeatures
Auto-import of Swagger-compliant endpoints
You can define URL(s) of Swagger documentation endpoints - a default URL and custom per-service URLs if necessary.
Imagine you have a Symfony2 microservice with Nelmio ApiDoc plugin running on /api/doc. Your microservice
returns something like:
$ curl -v http://localhost:8000/api/doc
{
"swaggerVersion": "1.2",
"apis": [{
"path": "\/uploads",
"description": "Operations on file uploads."
}],
"apiVersion": "0.1",
"info": {
"title": "Symfony2",
"description": "My awesome Symfony2 app!"
},
"authorizations": []
}
$ curl -v http://localhost:8000/api/doc/uploads
{
"swaggerVersion": "1.2",
"apiVersion": "0.1",
"basePath": "\/api",
"resourcePath": "\/uploads",
"apis": [{
"path": "\/uploads",
"operations": [{
"method": "GET",
"summary": "Retrieve list of files",
"nickname": "get_uploads",
"parameters": [],
"responseMessages": [{
"code": 200,
"message": "Returned when successful",
"responseModel": "AppBundle.Entity.Upload[items]"
}, {
"code": 500,
"message": "Authorization error or any other problem"
}],
"type": "AppBundle.Entity.Upload[items]"
}
},
"produces": [],
"consumes": [],
"authorizations": []
}This endpoint may be auto-imported to API gateway during container start (or whenever you see it fit).
Assuming this microservice is listed in GATEWAY_SERVICES, we can now run auto-import:
$ php artisan gateway:parse
** Parsing service1
Processing API action: http://localhost:8000/uploads
Dumping route data to JSON file
Finished! That's it - Vrata will now "proxy" all requests for /uploads to this microservice.
OAuth2 authentication
Vrata ships with Laravel Passport - a fully featured OAuth2 server. JSON Web Tokens are used to authenticate all API requests, and currently only local persistence (database) is supported. However, it's trivial to move OAuth2 server outside and rely on JWT token verification using public keys.
If incoming bearer token is invalid, Vrata will return 401 Non Authorized error. If the token is valid, Vrata will add two extra headers when making requests to underlying microservices:
X-User
Numeric subject Id extracted from the JSON Web Token. Your microservices can always assume the authentication part is done already and trust this user Id. If you want to implement authorization, you may base it on this Id or on token scopes (see below).
X-Token-Scopes
Token scopes extracted from the JSON web token. Comma separated (eg. read,write)
Your microservice may use these for authorization purposes (restrict certain actions, etc).
X-Client-Ip
Original user IP address.
Basic output mutation
You can do basic JSON output mutation using output property of an action. Eg.
[
'service' => 'service1',
'method' => 'GET',
'path' => '/pages/{page}',
'sequence' => 0,
'output_key' => 'data'
];Response from service1 will be included in the final output under data key.
output_key can be an array to allow further mutation:
[
'service' => 'service1',
'method' => 'GET',
'path' => '/pages/{page}',
'sequence' => 0,
'output_key' => [
'id' => 'service_id',
'title' => 'service_title',
'*' => 'service_more'
]
];This will assign contents of id property to garbage_id, title to service_title and the rest of the content will be inside of service_more property of the output JSON.
Performance
Performance is one of the key indicators of an API gateway and that's why we chose Lumen – bootstrap only takes ~25ms on a basic machine.
See an example of an aggregate request. First let's do separate requests to underlying microservices:
$ time curl http://service1.local/devices/5
{"id":5,"network_id":2,...}
real 0m0.025s
$ time curl http://service1.local/networks/2
{"id":2,...}
real 0m0.025s
$ time curl http://service2.local/visits/2
[{"id":1,...},{...}]
real 0m0.041sSo that's 91ms of real OS time – including all the web-server-related overhead. Let's now make a single aggregate request to the API gateway which behind the scenes will make the same 3 requests:
$ time curl http://gateway.local/devices/5/details
{"data":{"device":{...},"network":{"settings":{...},"visits":[]}}}
real 0m0.056sAnd it's just 56ms for all 3 requests! Second and third requests were executed in parallel (in async mode).
This is pretty decent, we think!
Examples
Example 1: Single, simple microservice
Let's say we have a very simple setup: API Gateway + one microservice behind it.
First, we need to let the gateway know about this microservice by adding it to GATEWAY_SERVICES environment variable.
{
"service": []
}Where service is the nickname we chose for our microservice. The array is empty because we will rely on default settings.
Our service has a valid Swagger documentation endpoint running on api/doc URL.
Next, we provide global settings on GATEWAY_GLOBAL environment variable:
{
"prefix": "/v1",
"timeout": 3.0,
"doc_point": "/api/doc",
"domain": "supercompany.io"
}This tells the gateway that services that don't have explicit URLs provided, will be communicated at
{serviceId}.{domain}, therefore our service will be contacted at service.supercompany.io, request timeout will be 3 seconds,
Swagger documentation will be loaded from /api/doc and all routes will be prefixed with "v1".
We could however specify service's hostname explicitly using "hostname" key in the GATEWAY_SERVICES array.
Now we can run php artisan gateway:parse to force Vrata to parse Swagger documentation
provided by this service. All documented routes will be exposed in this API gateway.
If you use our Docker image, this command will be executed every time you start a container.
Now, if your service had a route GET http://service.supercompany.io/users, it will be available as
GET http://api-gateway.supercompany.io/v1/users and all requests will be subject to JSON Web Token check and rate limiting.
Don't forget to set PRIVATE_KEY and PUBLIC_KEY environment variables, they are necessary for authentication to work.
Example 2: Multiple microservices with aggregate requests
This time we are going to add two services behind our API gateway - one with Swagger 1 documentation and another with Swagger 2 documentation. Vrata detects Swagger version automatically, so we don't have to specify this anywhere. Let's first define GATEWAY_SERVICES environment variable:
{
"core": [],
"service1": []
}So we have two services - "core" and "service1", Vrata will assume that DNS hostnames will match these.
Let's define GATEWAY_GLOBAL variable now - this variable contains global settings of the API gateway:
{
"prefix": "/v1",
"timeout": 10.0,
"doc_point": "/api/doc",
"domain": "live.vrata.io"
}All routes imported from Swagger will be prefixed with "/v1" because of the first setting. 10 seconds is the timeout we give our API gateway for internal requests to microservices behind it. "doc_point" is the URI of Swagger documentation, and "domain" is the DNS domain that will be added to every service name.
Therefore, when Vrata tries to load Swagger documentation for "core" service, it will hit http://core.live.vrata.io/api/doc URL. If you have unique Swagger URIs per microservice - you can define "doc_point" for every service individually.
Setting these two variables is enough to start working with Vrata - it will import all routes from "core" and "service1" and start proxying requests to them.
However, if we need something more sophisticated - eg. an aggregated request that involves multiple microservices at the same time, we need to define a third environment variable - GATEWAY_ROUTES.
Consider this example:
[{
"aggregate": true,
"method": "GET",
"path": "/v1/connections/{id}",
"actions": {
"venue": {
"service": "core",
"method": "GET",
"path": "venues/{id}",
"sequence": 0,
"critical": true,
"output_key": "venue"
},
"connections": {
"service": "service1",
"method": "GET",
"path": "connections/{venue%data.id}",
"sequence": 1,
"critical": false,
"output_key": {
"data": "venue.clients"
}
},
"access-lists": {
"service": "service1",
"method": "GET",
"path": "/metadata/{venue%data.id}",
"sequence": 1,
"critical": false,
"output_key": {
"data": "venue.metadata"
}
}
}
}, {
"method": "GET",
"path": "/v1/about",
"public": true,
"actions": [{
"service": "service1",
"method": "GET",
"path": "static/about",
"sequence": 0,
"critical": true
}]
}, {
"method": "GET",
"path": "/v1/history",
"raw": true,
"actions": [{
"method": "GET",
"service": "core",
"path": "/connections/history"
}]
}]The config above defines 3 routes - two regular requests with custom settings and one aggregate request. Let's start with simple requests:
{
"method": "GET",
"path": "/v1/about",
"public": true,
"actions": [{
"service": "service1",
"method": "GET",
"path": "static/about",
"sequence": 0,
"critical": true
}]
}This definition will add a "/v1/about" route to the API gateway that will be public - it won't require any access token at all, authentication will be bypassed. It will proxy request to http://service1.live.vrata.io/static/about and pass back whatever was returned.
Another simple route:
{
"method": "GET",
"path": "/v1/history",
"raw": true,
"actions": [{
"method": "GET",
"service": "core",
"path": "/connections/history"
}]
}This will add a "/v1/history" endpoint that will request data from http://core.live.vrata.io/connections/history. Notice the "raw" flag - this means Vrata won't do any JSON parsing at all (and therefore you won't be able to mutate output as result). This is important for performance - PHP may choke if you json_decode() and then json_encode() a huge string
- arrays and objects are very memory expensive in PHP.
And finally our aggregate route:
{
"aggregate": true,
"method": "GET",
"path": "/v1/connections/{id}",
"actions": {
"venue": {
"service": "core",
"method": "GET",
"path": "venues/{id}",
"sequence": 0,
"critical": true,
"output_key": "venue"
},
"connections": {
"service": "service1",
"method": "GET",
"path": "connections/{venue%data.id}",
"sequence": 1,
"critical": false,
"output_key": {
"data": "venue.clients"
}
},
"access-lists": {
"service": "service1",
"method": "GET",
"path": "/metadata/{venue%data.id}",
"sequence": 1,
"critical": false,
"output_key": {
"data": "venue.metadata"
}
}
}
}First property marks it as an aggregate route - that's self explanatory. The route will be mounted as "/v1/connections/{id}" where "id" will be any string or number. Then, this route involves 3 requests to microservices and two of them can be made in parallel - because they have the same sequence number of 1.
Vrata will first make a request to http://core.live.vrata.io/venues/{id} where {id} is the parameter from request. This route action is marked as critical - therefore, if it fails the whole request is abandoned. All output from this action will be presented in the final JSON output as "venue" property.
Then, two requests will be launched simultaneously - to http://service1.live.vrata.io/connections/{id} and another to http://service1.live.vrata.io/metadata/{id}. This time, {id} is taken from the output of the previous action. Vrata will collect all outputs from all requests and make them available to all following requests.
Since these two requests always happen later than the first one (because of the sequence setting), they can have access to its output. Notice {venue%data.id} in the paths - this refers to "venue" (name of the previous action) and "id" property of "data" object ("data.id" in dot notation).
Both actions are set to non-critical - if they fail, user will still receive a response, but corresponding fields will be empty.
We only take "data" JSON property from both responses and we inject it to the final response as "venue.clients" and "venue.metadata".
Example 3: Multiple microservices with aggregate POST / PUT / DELETE requests
Initial body of your POST, PUT or DELETE request come with origin tag usable in your json. You can use in your actions an optionnal body parameters for each requests. You can use origin tag to use the body sent in your initial request. You can also use the response of each actions in the body param like in a GET aggregate request.
{
"aggregate": true,
"method": "PUT",
"path": "/v1/unregister/sendaccess",
"actions": {
"contact": {
"service": "contact",
"method": "PUT",
"path": "unregister/newsletter",
"sequence": 0,
"critical": true,
"body": {
"email": "{origin%email}"
},
"output_key": "register"
},
"template": {
"service": "notice",
"method": "POST",
"path": "notice/email/generate",
"sequence": 1,
"critical": true,
"body": {
"validationToken": "{contact%validationToken}",
"noticeTypeId": "{contact%validationType}"
},
"output_key": "notice"
},
"check": {
"service": "email",
"method": "POST",
"path": "email/send",
"sequence": 2,
"critical": true,
"body": {
"to": "{origin%email}",
"sujet": "Email object",
"queue_name": "urgent",
"message_html": "{template%htmlTemplate}",
"message_text": "text version",
"from": "support@example.org",
"nom": "Sender name"
},
"output_key": "result"
}
}
}License
The MIT License (MIT)
Copyright (c) 2017-2018 PoweredLocal
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.