 st-pasha
commented
6 years ago
st-pasha
commented
6 years ago The warning message says
Stopped early on line 138986. Expected 67 fields but found 22. Consider fill=TRUE.
First discarded non-empty line:
...First thing I'd suggest to do is to open your file in a text editor and look at line 138986 (the counter may be slightly off, so might be better to search for the line shown).
If you don't have a way to open a 2GB text file, try fread-ing it with sep=NULL (this is equivalent to readLines()). Then extract the relevant lines (e.g. DT[138980:138990]) and see what the problem is with line 138986
 msummersgill
msummersgill mihcis
mihcis mattdowle
mattdowle jangorecki
jangorecki miderxi
miderxi{kind=link}
{kind=link}
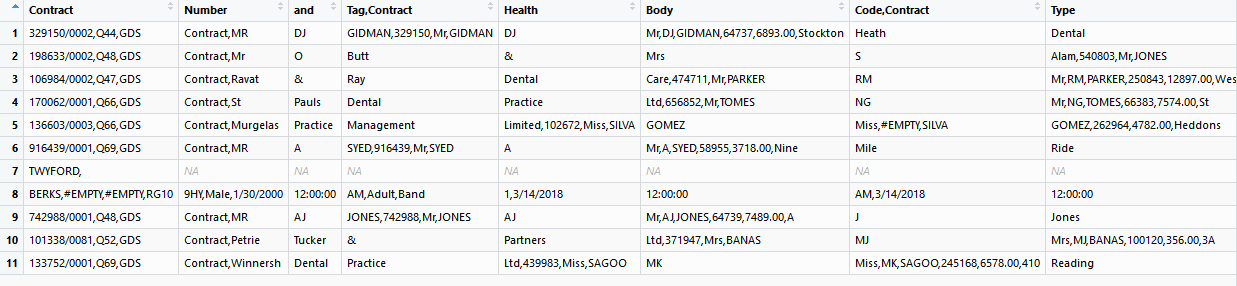
I've encountered a possible bug in the newer versions of data.table. I have a 2GB .csv file with c. 3 million rows and 67 columns. I can use fread() to read it all fine from data.table v.1.10.4-3, but v.1.11.0+ terminates at a row somewhere in the middle.
The base read.csv() also hits the same problem, while fread() from v.1.10.4-3 worked perfectly.
I really like data.table and want to help troubleshoot this, but obviously I can't upload the 2GB data file anywhere as it is too big and private.
I can upload a few rows though, but I don't know a way of splicing the .csv without reading it into R. I am keen to get any help though in order to create a reproducible example.
The verbose output is here.
The sessionInfo() is here.