ASP.NET Core Markdown Support



This small package provides Markdown support for your ASP.NET Core applications. It has the following features:
- Markdown Parsing
- Parse Markdown to HTML Strings
Markdown.Parse(markdown)
@Markdown.ParseHtmlString(markdown) - Parse Markdown from Files
Markdown.ParseFromFile("~/MarkdownPartial.md")
Markdown.ParseFromFileAsync("~/MarkdownPartial.md")
Markdown.ParseHtmlStringFromFile("~/MarkdownPartial.md") - Parse Markdown from Urls
Markdown.ParseFromUrl("https://github.com/RickStrahl/Westwind.AspNetCore.Markdown/raw/master/readme.md")
Markdown.ParseFromUrlAsync("https://github.com/RickStrahl/Westwind.AspNetCore.Markdown/raw/master/readme.md") - Configurable Markdown Parser
Plug in your own or customize the Markdown Parser viaIMarkdownParserFactoryandIMarkdownParser
- Parse Markdown to HTML Strings
- Markdown TagHelper
- Embed Markdown text into Views and Pages
- Databind Model data as Markdown text via markdown attribute
- Render Markdown from files via filename attribute
- Supports white space normalization
- Markdown Page Processor Middleware
- Serve
.mdfiles as Markdown - Serve mapped extensionless URLs as Markdown
- Configure a Razor template to customize Markdown Page Container UI
- Serve
- Configuration and Support Features
- Uses the awesome MarkDig Markdown Parser by default
- Customizable Markdown Parsing Pipeline for Markdig
- Pluggable Markdown Parser Support
- Basic HTML Sanitation support built in
- RenderExtensions to inject custom functionality
Related links:
Installing the NuGet Package
You can install the package from NuGet in Visual Studio or from the command line:
PM> install-package westwind.aspnetcore.markdownor the dotnet command line:
dotnet add package westwind.aspnetcore.markdownStartup Configuration
To use these components you need to add the following to your Startup class at minimum. The following is for ASP.NET Core 3.0 and later using endpoint routing:
public void ConfigureServices(IServiceCollection services)
{
services.AddMarkdown();
// We need to use MVC so we can use a Razor Configuration Template
services.AddMvc()
// have to let MVC know we have a controller
.AddApplicationPart(typeof(MarkdownPageProcessorMiddleware).Assembly);
}
public void Configure(IApplicationBuilder app)
{
// if you use default files make sure you do it before markdown middleware
app.UseDefaultFiles(new DefaultFilesOptions()
{
DefaultFileNames = new List<string> { "index.md", "index.html" }
});
app.UseMarkdown();
app.UseStaticFiles();
// the following enables MVC and Razor Pages
app.UseRouting();
app.UseEndpoints(endpoints =>
{
// endpoints.MapRazorPages(); // optional
// MVC routing is required
endpoints.MapDefaultControllerRoute();
});
}There are additional configuration options for the AddMarkdown() method available which are discussed in more detail later.
Configuration is optional Static
Markdownmethods or the TagHelperNote the above configuration is required only if you use the Markdown Middleware that processes loose Markdown pages. If you use the static Markdown functions or the TagHelper and you don't need custom Markdown configuration of the Markdown Parser, configuration is not required.
Markdown Parsing Helpers
At it's simplest this component provides Markdown parsing that you can use to convert Markdown text to HTML either inside of application code, or inside of Razor expressions.
Markdown to String
string html = Markdown.Parse(markdownText);Markdown to Razor Html String
<div>@Markdown.ParseHtmlString(Model.ProductInfoMarkdown)</div>Parse Markdown to String from a File
You can also convert Markdown using a file:
var html = Markdown.ParseFromFile("~/EmbeddedMarkdownContent.md");
// async
html = await Markdown.ParseFromFileAsync("~/EmbeddedMarkdownContent.md");To embed in Razor Views:
@Markdown.ParseHtmlStringFromFile("~/EmbeddedMarkdownContent.md")Parse Markdown to String from a Url
You can also load Markdown from a URL as long as it's openly accessible via a URL:
// sync
parsedHtml = Markdown.ParseFromUrl("https://github.com/RickStrahl/Westwind.AspNetCore.Markdown/raw/master/readme.md")
// async
parsedHtml = await Markdown.ParseFromUrlAsync("https://github.com/RickStrahl/Westwind.AspNetCore.Markdown/raw/master/readme.md");HtmlString versions are also available of this method.
SanitizeHtml in Parser Methods to mitigate XSS
Both of the above methods include a few optional parameters including a sanitizeHtml parameter which defaults to false. If set to true any <script> tags that are not embedded inside of inline or fenced code blocks are stripped. Additionally any reference to javascript: inside of a tag is replaced with unsupported: rendering the script non-functional.
string html = Markdown.Parse(markdownText, sanitizeHtml: true)MarkDig Pipeline Configuration
This component uses the MarkDig Markdown Parser which allows for explicit feature configuration via many of its built-in extensions. The default configuration enables the most commonly used Markdown features and defaults to Github Flavored Markdown for most settings.
If you need to customize what features are supported you can override the pipeline creation explicitly in the Startup.ConfigureServices() method:
services.AddMarkdown(config =>
{
// Create custom MarkdigPipeline
// using MarkDig; for extension methods
config.ConfigureMarkdigPipeline = builder =>
{
builder.UseEmphasisExtras(Markdig.Extensions.EmphasisExtras.EmphasisExtraOptions.Default)
.UsePipeTables()
.UseGridTables()
.UseAutoIdentifiers(AutoIdentifierOptions.GitHub) // Headers get id="name"
.UseAutoLinks() // URLs are parsed into anchors
.UseAbbreviations()
.UseYamlFrontMatter()
.UseEmojiAndSmiley(true)
.UseListExtras()
.UseFigures()
.UseTaskLists()
.UseCustomContainers()
.UseGenericAttributes();
//.DisableHtml(); // don't render HTML - encode as text
};
});When set this configuration is used every time the Markdown parser instance is created instead of the default behavior.
Markdown TagHelper
The Markdown TagHelper allows you to embed static Markdown content into a <markdown> tag. The TagHelper supports both embedded content, or an attribute based value assignment or model binding via the markdown attribute.
To get started with the Markdown TagHelper you need to do the following:
- Register TagHelper in
_ViewImports.cshtml - Place a
<markdown>TagHelper on the page - Use
Markdown.ParseHtmlString()in Razor Page expressions - Rock on!
After installing the NuGet package you have to register the tag helper so MVC can find it. The easiest way to do this is to add it to the _ViewImports.cshtml file in your Views\Shared folder for MVC or the root for your Pages folder.
@addTagHelper *, Westwind.AspNetCore.MarkdownLiteral Markdown Content
To use the literal content control you can simply place your Markdown text between the opening and closing <markdown> tags:
<markdown>
#### This is Markdown text inside of a Markdown block
* Item 1
* Item 2
### Dynamic Data is supported:
The current Time is: @DateTime.Now.ToString("HH:mm:ss")
```cs
// this c# is a code block
for (int i = 0; i < lines.Length; i++)
{
line1 = lines[i];
if (!string.IsNullOrEmpty(line1))
break;
}
The TagHelper turns the Markdown text into HTML, in place of the TagHelper content.
> ##### Razor Expression Evaluation
> Note that Razor expressions in the markdown content are supported - as the `@DateTime.Now.ToString()` expression in the example - and are expanded **before** the content is parsed by the TagHelper. This means you can embed dynamic values into the markdown content which gives you most of the flexibilty of Razor code now in Markdown. Embedded expressions **are not automatically HTML encoded** as they are embedded into the Markdown. Additionally you can also generate additional Markdown as part of a Razor expression to make the Markdown even more dynamic.
### TagHelper Attributes
#### filename
You can specify a filename to pull Markdown from and render into HTML. Files can be referenced:
* Physical paths: `/temp/somefile.md`
* Relative paths: `somefolder/somefile.md` - relative to current page
* Virtual paths: `~/somefolder/somefile.md` - relative to site root
> #### Relative File Links load resources as *Host Page Relative*
> Any relative links and resources - images, relative links - that are referenced are **relative to the host page** not relative to the Markdown document. Make sure you take into account paths for any related resources and either ensure they are relative to the host page or use absolute URLs.
#### url
You can also load Markdown documents from URL and process them as markdown to HTML for embedding into the page. The Url has to be openly accessible (ie. no authentication). This is great for loading and embedding content from remote sources such as from Github and rendering it as part of your application. It's very useful for CMS and Documentation solutions where a remote repository serves as the document store.
#### url-fixup-basepath
When `true` (default) any relative Markdown images and links are converted to absolute URLs relative to the Markdown document that is being loaded via the `url=` attribute. Typically you'll want images and links to be fixed up so images show and you don't end up with dead links. However in some situations you might want to render the page with the original links in which case you can explicitly force the attribute to `false`.
#### markdown (Model Binding)
In addition to the content you can also bind to the `markdown` attribute which allows for programmatic assignment and data binding.
```html
@model MarkdownPageModel
@{
Model.MarkdownText = "This is some **Markdown**!";
}
<markdown markdown="Model.MarkdownText" />The markdown attribute accepts binding expressions so you can bind Markdown for display from model values or other expressions easily.
normalize-whitespace
Markdown is sensitive to leading spaces and given that you're likely to enter Markdown into the literal TagHelper in a code editor there's likely to be a leading block of white space. Markdown treats leading white space as significant - 4 spaces or a tab indicate a code block so if you have:
<markdown>
#### This is Markdown text inside of a Markdown block
* Item 1
* Item 2
### Dynamic Data is supported:
The current Time is: @DateTime.Now.ToString("HH:mm:ss")
</markdown>without special handling Markdown would interpret the entire markdown text as a single code block.
By default the TagHelper sets normalize-whitespace="true" which automatically strips common white space to all lines from the code block. Note that this is based on the formatting of the first non-blank line of code and works only if all code lines start with the same formatted white space.
Optionally you can also force justify your code and turn the setting to false:
<markdown normalize-whitespace="false">
#### This is Markdown text inside of a Markdown block
* Item 1
* Item 2
### Dynamic Data is supported:
The current Time is: @DateTime.Now.ToString("HH:mm:ss")
</markdown>This also works, but is hard to maintain in some code editors due to auto-code reformatting.
sanitize-html
By default the Markdown tag helper strips <script> tags and href="https://github.com/RickStrahl/Westwind.AspNetCore.Markdown/blob/master/javascript" directives from the generated HTML content. The default for this property is true If you would like to explicitly include script tags because your content requires it you can enable that functionality by setting sanitize-html=false.
The default behavior strips the script content shown below (sanitize-html tag only shown by reference - true is the default so not required here):
<markdown sanitize-html="true">
### Rudimentary XSS Support
Below are a script tag, and some raw HTML alert with an onclick handler which
are potential XSS vulnerable. Default is `strip-script-tags="true"` to remove
script and other vulnerabilities.
<a href="https://github.com/RickStrahl/Westwind.AspNetCore.Markdown/blob/master/javascript: alert('Gotcha! javascript: executed.');">Malicious Link</a>
<script>
alert("GOTHCHA! Injected code executed.")
</script>
<div class="alert alert-info" onmouseover="alert('Gotcha! onclick handler fired');">
XSS Alert: You shouldn't be able to click me and execute the onclick handler.
</div>
</markdown>With the flag set to false the script does execute and the link will trigger the second alert. The default of true removes the entire script block and replaces javascript: in the href with unsupported: which effectively doesn't do anything.
no-http-exception
Optional parameter that can be set if you are using a URL bound to the tag helper. When true causes the TagHelper to render empty instead of throwing an HTTP load exception and break the page.
Markdown Page Processor Middleware
The Markdown middleware allows you drop .md files into a configured folder and have that folder parsed directly from disk. The middleware merges the Markdown into a pre-configured Razor template you provide so your Markdown text can be rendered in the proper UI context of your site chrome.
To use this feature you need to do the following:
- Use
AddMarkdown()to configure the page processing - Use
UseMarkdown()to hook up the middleware - Create a Markdown View Template (default is:
~/Views/__MarkdownPageTemplate.cshtml) - Create
.mdfiles for your content - Rock on!
Note that the default template location can be customized for each folder and it can live anywhere including the Pages folder.
Startup Configuration
As with any middleware components you need to configure the Markdown middleware and hook it up for processing which is a two step process.
First you need to call AddMarkdown() to configure the Markdown processor. You need to specify the folders that the processor is supposed to work on.
At it's simplest you can just do:
public void ConfigureServices(IServiceCollection services)
{
services.AddMarkdown(config =>
{
// just add a folder as is
config.AddMarkdownProcessingFolder("/docs/");
services.AddMvc();
}
}This configures the Markdown processor for default behavior which handles .md files and extensionless Urls in the /docs/ folder as Markdown files (if they exist) and it assumes a default Razor Markdown host template at ~/Views/__MarkdownPageTemplate.cshtml.
All of these values can be customized with additional configuration options in ConfigureServices():
services.AddMarkdown(config =>
{
// optional Tag BlackList
config.HtmlTagBlackList = "script|iframe|object|embed|form"; // default
// Simplest: Use all default settings
var folderConfig = config.AddMarkdownProcessingFolder("/docs/", "~/Pages/__MarkdownPageTemplate.cshtml");
// Customized Configuration: Set FolderConfiguration options
folderConfig = config.AddMarkdownProcessingFolder("/posts/", "~/Pages/__MarkdownPageTemplate.cshtml");
// Optionally strip script/iframe/form/object/embed tags ++
folderConfig.SanitizeHtml = false; // default
// folderConfig.BasePath = "http://othersite.com";
// Optional configuration settings
folderConfig.ProcessExtensionlessUrls = true; // default
folderConfig.ProcessMdFiles = true; // default
// Optional pre-processing - with filled model
folderConfig.PreProcess = (model, controller) =>
{
// controller.ViewBag.Model = new MyCustomModel();
};
// optional custom MarkdigPipeline (using MarkDig; for extension methods)
config.ConfigureMarkdigPipeline = builder =>
{
builder.UseEmphasisExtras(Markdig.Extensions.EmphasisExtras.EmphasisExtraOptions.Default)
.UsePipeTables()
.UseGridTables()
.UseAutoIdentifiers(AutoIdentifierOptions.GitHub) // Headers get id="name"
.UseAutoLinks() // URLs are parsed into anchors
.UseAbbreviations()
.UseYamlFrontMatter()
.UseEmojiAndSmiley(true)
.UseListExtras()
.UseFigures()
.UseTaskLists()
.UseCustomContainers()
//.DisableHtml() // renders HTML tags as text including script
.UseGenericAttributes();
};
}); There are additional options including the ability to hook in a pre-processor that's fired on every controller hit. In the example I set a custom model to the ViewBag that the template can potentially pick up and work with. For applications you might have a stock View model that provides access rights and other user logic that needs to fire to access the page and display the view. Using the PreProcess Action hook you can run just about any pre-processing logic and get values into the View if necessary via the Controller.Viewbag.
In addition to the configuration you also need to hook up the Middleware in the Configure() method:
public void Configure(IApplicationBuilder app, IHostingEnvironment env)
{
...
app.UseMarkdown();
app.UseStaticFiles();
app.UseMvc();
}The UseMarkdown() method hooks up the middleware into the pipeline.
Note that both ConfigureServices() and Configure() are required to reference the MVC middleware - services.AddMvc() and app.UseMvc() respectively - as the middleware relies on MVC and Razor to render the Razor host view template.
Create a Markdown Page View Template
Markdown is just an HTML fragment, not a complete document, so a host template is required into which the rendered Markdown is embedded. To accomplish this the middleware uses a well-known MVC controller endpoint that loads the configured Razor view template that embeds the Markdown text.
The middleware reads in the Markdown file from disk, and then uses a generic MVC controller method call the specified template to render the page containing your Markdown text as the content. The template is passed a MarkdownModel that includes RenderedMarkdown and Title properties.
Typically the template page is pretty simple and only contains the rendered Markdown plus a reference to a _Layout page, but what goes into this template is really up to you.
The actual rendered Markdown content renders into HTML is pushed into the page via ViewBag.RenderedMarkdown, which is an HtmlString instance that contains the rendered HTML.
A minimal template page can do something like this:
@model Westwind.AspNetCore.Markdown.MarkdownModel
@{
ViewBag.Title = Model.Title;
Layout = "_Layout";
}
<div style="margin-top: 40px;">
@Model.RenderedMarkdown
</div>This template can be a self contained file, or as I am doing here, it can reference a _layout page so that the layout matches the rest of your site.
A more complete template might also add a code highlighter (highlightJs here) and custom styling something more along the lines of this:
@model Westwind.AspNetCore.Markdown.MarkdownModel
@{
Layout = "_Layout";
}
@section Headers {
@if (!string.IsNullOrEmpty(Model.BasePath))
{
<base href="https://github.com/RickStrahl/Westwind.AspNetCore.Markdown/blob/master/@Model.BasePath" />
}
<style>
h3 {
margin-top: 50px;
padding-bottom: 10px;
border-bottom: 1px solid #eee;
}
/* vs2015 theme specific*/
pre {
background: #1E1E1E;
color: #eee;
padding: 0.7em !important;
overflow-x: auto;
white-space: pre;
word-break: normal;
word-wrap: normal;
}
pre > code {
white-space: pre;
}
</style>
}
<div style="margin-top: 40px;">
@Model.RenderedMarkdown
</div>
@section Scripts {
<script src="https://github.com/RickStrahl/Westwind.AspNetCore.Markdown/raw/master/~/lib/highlightjs/highlight.pack.js"></script>
<link href="https://github.com/RickStrahl/Westwind.AspNetCore.Markdown/blob/master/~/lib/highlightjs/styles/vs2015.css" rel="stylesheet" />
<script>
setTimeout(function () {
var pres = document.querySelectorAll("pre>code");
for (var i = 0; i < pres.length; i++) {
hljs.highlightBlock(pres[i]);
}
});
</script>
}Title Rendering
The middleware will attempt to find a title in the document to use as the title tag for the HTML page it generates. It'll look for the title in:
- Yaml Header
title: Your Title Text - The first
# Headertag in the first 10 lines of non-Yaml content - The first line underlined with
===in the first 11 lines of non-Yaml content
Both of the following will pick up Hello World as the title for a Markdown document:
---
title: Hello World
---
# This is my Hello World
Text to follow# Hello World
Text to followHello World
===========
Text to followBase Path Rendering
When rendering Markdown pages, the page is rendered similar to the way an HTML would be rendered in the path of the active document (ie. what's shown in the address bar). This works great if you have all the content locally and relative to the active document, treating the output much the same way you would an HTML document.
However, if you're loading content from a remote source, you may have to specify a separate base path in order to retrieve related dependencies like images, fonts, css etc. In order to do this you need to get a <base href="https://github.com/RickStrahl/Westwind.AspNetCore.Markdown/blob/master/<url>" /> into the page.
You can specify the baseUrl in two ways:
- Via Markdown folder configuration (
folderConfig.BaseUrl) - In the Markdown document via
baseUrl: <url>YAML header
The default Markdown rendering template includes the following header code:
@section Headers {
@if (string.IsNullOrEmpty(Model.BasePath))
{
<base href="https://github.com/RickStrahl/Westwind.AspNetCore.Markdown/blob/master/@Model.BasePath"/>
}
...
}Create your Markdown Pages
Finally you need to create your Markdown pages in the folders you configured. Assume for a minute that you hooked up a Posts folder for Markdown Processing. The folder refers to the \wwwroot\Posts folder in your ASP.NET Core project. You can now create a new markdown file in that folder or any subfolder below it. I'm going to pretend I create blog post in a typical data folder structure.
For example:
wwwroot/posts/2018/03/23/MarkdownTagHelper.md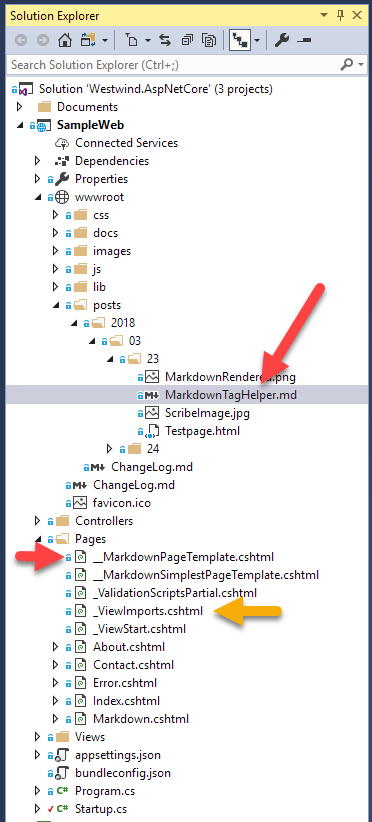
I can now access this post using either:
http://localhost:59805/posts/2018/03/23/MarkdownTagHelper.mdor if extensionless URLs are configured:
http://localhost:59805/posts/2018/03/23/MarkdownTagHelperThe screenshot below shows the output of this page which is a Markdown blog post I simply copied into a folder along with a couple of support images. This is in a stock ASP.NET Core MVC project without any other changes save a few label updates:

Voila generically rendered Markdown content from .md files on disk.
Markdown Styling
A Markdown parser only converts Markdown to HTML, it does nothing for styling or how that rendered HTML content is displayed. It's up to the hosting application to provide the styling applied to the rendered HTML. For the most part HTML 'just works'. For example the stock ASP.NET Core Bootstrap templates render most markdown text nicely as you would expect.
Syntax Highlighting
One thing that you usually will need to add is code syntax highlighting support. Syntax highlighting can be accomplished by using a JavaScript code highlighting addin. You can check out the Markdown.cshtml sample page to see how to use HiLightJs .
The following adds basic syntax coloring support using a preconfigured package of languages.
@section Scripts {
<script src="https://github.com/RickStrahl/Westwind.AspNetCore.Markdown/raw/master/~/lib/highlightjs/highlight.pack.js"></script>
<link href="https://github.com/RickStrahl/Westwind.AspNetCore.Markdown/blob/master/~/lib/highlightjs/styles/vs2015.css" rel="stylesheet" />
<script>
setTimeout(function () {
var pres = document.querySelectorAll("pre>code");
for (var i = 0; i < pres.length; i++) {
hljs.highlightBlock(pres[i]);
}
});
</script>
}highlightJs from CDN
The provided highlightJs package includes a custom compiled set of languages that I use most commonly. You can download and create your own package. You can also pick up HighlightJs directly off a CDN with the default language pack which may or may not provide the languages you need to display:
<script src="https://cdnjs.cloudflare.com/ajax/libs/highlight.js/9.12.0/highlight.min.js"></script> <link href="https://cdnjs.cloudflare.com/ajax/libs/highlight.js/9.12.0/styles/vs2015.min.css" rel="stylesheet" />
Default Document Handling
You can also use the stock ASP.NET Core default document middleware to automatically display a Markdown document on a root Url if you provide a physical file in the physical folder that matches a default document like index.md.
You'll need to use the default ASP.NET Core DefaultDocuments middleware and ensure it's registered before the Markdown middleware in the startup Configure() method:
app.UseDefaultFiles(new DefaultFilesOptions()
{
DefaultFileNames = new List<string> { "index.md", "index.html" }
});
app.UseMarkdown();
// make sure `UseMarkdown()` is called before this
app.UseStaticFiles()Assuming I've mapped the /docs/ folder, I can then create /docs/index.md. I can now navigate to /docs/ and the /docs/index.md file will be served.
Westwind.AspNetCore.Markdown and XSS
You should always treat Markdown exactly like you would treat raw HTML. If you're letting users input Markdown, understand that the rendered HTML may have to be sanitized.
This component has a few features that provides basic options to remove the most obvious XSS attacks.
There are two approaches:
- Remove support for HTML tags
- Strip Script tags
Remove support for HTML tags embedded in Markdown
By default Markdown supports rendering of embedded HTML as-is. Any HTML text inside of a Markdown document that is preceeded by a blank line will render as raw HTML.
This means that it's possible to enter any kind of HTML and script into a markdown document and that script executes when rendered unsanitized.
You can explicitly remove HTML support which effectively renders all HTML tags as HTML encoded text. To do this use the following configuration setup:
services.AddMarkdown(config =>
{
// Create custom MarkdigPipeline
// using MarkDig; for extension methods
config.ConfigureMarkdigPipeline = builder =>
{
builder.UseEmphasisExtras(Markdig.Extensions.EmphasisExtras.EmphasisExtraOptions.Default)
.UsePipeTables()
.UseGridTables()
...
// *** DISABLE HTML HERE
.DisableHtml();
};
});Use the StripScriptTags Option
The various components and static methods each have the ability to trigger a script tag filter which is fired after the HTML has been generated. A few RegEx expressions are used to remove <script> (and <iframe>,<object>,<embed> and <form>) tags, <a href='javascript:'> type requests and onXXX= DOM event handlers.
Markdown.Parse(markdown,sanitizeHtml)
The Parse() and ParseHtml() methods both include a sanitizeHtml parameter which is false by default. The default behavior is to leave script code as is so if you use the static functions stripping script out is always an opt in operation.
Markdown Tag Helper
The Markdown TagHelper has a sanitize-html attribute that is true by default. The TagHelper automatically removes script tags by default. Set the attribute to false to force the tag helper to explicitly include scripts.
Markdown Page Handler
By default the Markdown Page Handler renders script as is. In most cases pages are static and usually under the control of the Web site and meant to replace potentially large HTML pages which in some cases may need to include script.
To strip script tags you can set the StripScriptTags flag on the folder configuration instance:
var folderConfig = config.AddMarkdownProcessingFolder(
"/docs/",
"~/Pages/__MarkdownPageTemplate.cshtml");
folderConfig.SanitizeHtml = true;Overriding the Html Tag Blacklist
The HTML Tag Blacklist used when when sanitizeHtml is set to true can be overridden via the Config object's HtmlTagBlackList property during configuration:
public void ConfigureServices(IServiceCollection services)
{
services.AddMarkdown(config =>
{
// optionally set the BlackList Tag list - default values below
config.HtmlTagBlackList = "script|iframe|object|embed|form";
...
}
}This value is global and can only be set during startup. Changing it at runtime has no effect as it translates to RegEx expression parameters.
Extend Markdown to HTML Rendering with MarkdownRenderExtensions
You can add custom rendering functionality to the Markdown parser via Markdown Render Extensions, that let you modify the inbound markdown and outbound html before the parsed result is returned via an implementation of IMarkdownRenderExtension. You can create a custom class and implement the required interface, to modify content to render or already rendered for final output and then add the custom class to:
MarkdownRenderExtensionsManager.Current.AddRenderExtension( new MyRenderExtension() );To implement a render extension involves implement the IMarkdownRenderExtension interface. Here's an example for a PlantUMLRenderExtension that intercepts incoming markdown and replace ```plantuml code blocks with <img> urls that generate diagrams:
public class PlantUmlMarkdownRenderExtension : IMarkdownRenderExtension
{
public string Name {get; set;} = "PlantUmlRenderExtension";
private const string PlantUmlServerUrl = "http://www.plantuml.com/plantuml/png/";
private const string StartUmlString = "\n```plantuml";
private static readonly Regex plantUmlRegex = new Regex(@"(\n```plantuml[\S\s]).*?([\s\S]```)", RegexOptions.Singleline);
// demonstrates pre-render Markdown processing
public void BeforeMarkdownRendered(ModifyMarkdownArguments args)
{
if (string.IsNullOrEmpty(args.Markdown) ||
!args.Markdown.Contains(StartUmlString))
return;
var markdown = args.Markdown;
var matches = plantUmlRegex.Matches(markdown);
foreach (var match in matches)
{
var origBlock = match?.ToString();
var umlBlock = origBlock.TrimStart();
if (umlBlock.StartsWith("```"))
umlBlock = umlBlock.Replace("```plantuml", string.Empty).Trim(' ', '`', '\n', '\r');
var url = PlantUmlServerUrl + PlantUmlTextEncoding.EncodeUrl(umlBlock);
var html = $"<img src=\"{url}\" alt=\"diagram\" />";
if (url.Contains("plantuml.com"))
{
var linkUrl = url.ReplaceMany(new string[] { "/svg/", "/png/", "/txt/" }, "/uml/");
if (!string.IsNullOrEmpty(linkUrl))
html = $"<a href=\"{linkUrl}\" target=\"_blank\">{html}</a>";
}
markdown = markdown.Replace(origBlock, html);
}
args.Markdown = markdown;
}
// demonstrate post-render HTML processing
public void AfterMarkdownRendered(ModifyHtmlAndHeadersArguments args)
{
args.Html += "\n<div class='shareware-banner'>This is a demonstration copy of MyGreatProduct. Please register your copy.</div>";
}
public void AfterDocumentRendered(ModifyHtmlArguments args)
{ }
}This addin overrides the BeforeMarkdownRendered() method which receives the inbound args.Markdown property that can be modified. It parses the inbound Markdown and replaces it with the transformed Markdown which is then used in rendering.
Likewise the AfterMarkdownRendered(ModifyHtmlAndHeadersArguments() method receives an args.Html property which allows you to modify the rendered HTML output and lets you modify that.
You can create new addins and register them application wide using the following:
Directly
MarkdownRenderExtensionsManager.Current.AddRenderExtension( new PlantUMLRenderExtension() );via Middleware Configuration in ASP.NET
services.AddMarkdown(config =>
{
config.MarkdownRenderExtensions.Add( new PlantUmlMarkdownRenderExtension() );
// ...
} Markdown Render Extensions are a great and quick way to extend Markdown rendering at the application level, without affecting the core Markdown processor.
Using a Different Markdown Parser
The default implementation of this library and middleware uses the MarkDig Markdown Parser for processing of Markdown content. However, you can implement your own parser by implementing:
- IMarkdownParserFactory
- IMarkdownParser
These two simple single-method interfaces have a IMarkdownParserFactory.GetParser() and IMarkdownParser.Parse() methods respectively that you can implement to retrieve an instance of your own custom parser.
To configure a custom parser apply it to the Configuration.MarkdownParserFactory property in the Startup.ConfigureServices() method:
services.AddMarkdown(config =>
{
// Create your own IMarkdownParserFactory and IMarkdownParser implementation
config.MarkdownParserFactory = new CustomMarkdownParserFactory();
...
} The custom parser is then used for all markdown processing in this library.
License
The Westwind.Web.MarkdownControl library is an open source product licensed under:
All source code is © West Wind Technologies, regardless of changes made to them. Any source code modifications must leave the original copyright code headers intact if present.
There's no charge to use, integrate or modify the code for this project. You are free to use it in personal, commercial, government and any other type of application and you are free to modify the code for use in your own projects.
Give back
If you find this library useful, consider making a small donation:
<a href="https://www.paypal.com/cgi-bin/webscr?cmd=_s-xclick&hosted_button_id=BA3NHHFHTMXD8" title="Find this library useful? Consider making a small donation." alt="Make Donation" style="text-decoration: none;">
