Seldon Core: Blazing Fast, Industry-Ready ML
A platform to deploy your machine learning models on Kubernetes at massive scale.
Seldon Core V2 Now Available

Seldon Core V2 is now available. If you're new to Seldon Core we recommend you start here. Check out the docs here and make sure to leave feedback on our slack community and submit bugs or feature requests on the repo. The codebase can be found in this branch.
Continue reading for info on Seldon Core V1...
![]()
Overview
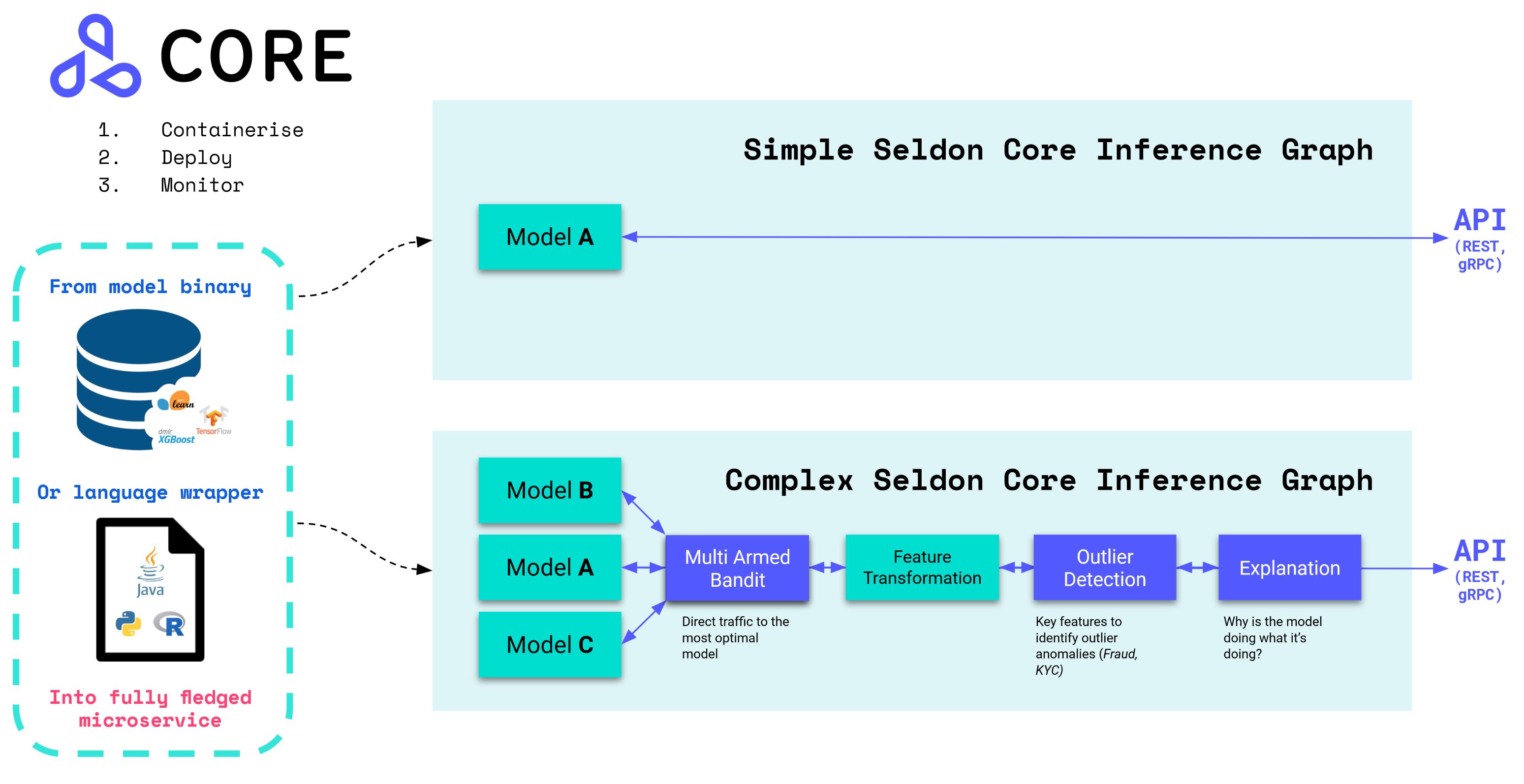
Seldon core converts your ML models (Tensorflow, Pytorch, H2o, etc.) or language wrappers (Python, Java, etc.) into production REST/GRPC microservices.
Seldon handles scaling to thousands of production machine learning models and provides advanced machine learning capabilities out of the box including Advanced Metrics, Request Logging, Explainers, Outlier Detectors, A/B Tests, Canaries and more.
- Read the Seldon Core Documentation
- Join our community Slack to ask any questions
- Get started with Seldon Core Notebook Examples
- Join our fortnightly online working group calls : Google Calendar
- Learn how you can start contributing
- Check out Blogs that dive into Seldon Core components
- Watch some of the Videos and Talks using Seldon Core
High Level Features
With over 2M installs, Seldon Core is used across organisations to manage large scale deployment of machine learning models, and key benefits include:
- Easy way to containerise ML models using our pre-packaged inference servers, custom servers, or language wrappers.
- Out of the box endpoints which can be tested through Swagger UI, Seldon Python Client or Curl / GRPCurl.
- Cloud agnostic and tested on AWS EKS, Azure AKS, Google GKE, Alicloud, Digital Ocean and Openshift.
- Powerful and rich inference graphs made out of predictors, transformers, routers, combiners, and more.
- Metadata provenance to ensure each model can be traced back to its respective training system, data and metrics.
- Advanced and customisable metrics with integration to Prometheus and Grafana.
- Full auditability through model input-output request logging integration with Elasticsearch.
- Microservice distributed tracing through integration to Jaeger for insights on latency across microservice hops.
- Secure, reliable and robust system maintained through a consistent security & updates policy.
Getting Started
Deploying your models using Seldon Core is simplified through our pre-packaged inference servers and language wrappers. Below you can see how you can deploy our "hello world Iris" example. You can see more details on these workflows in our Documentation Quickstart.
Install Seldon Core
Quick install using Helm 3 (you can also use Kustomize):
kubectl create namespace seldon-system
helm install seldon-core seldon-core-operator \
--repo https://storage.googleapis.com/seldon-charts \
--set usageMetrics.enabled=true \
--namespace seldon-system \
--set istio.enabled=true
# You can set ambassador instead with --set ambassador.enabled=trueDeploy your model using pre-packaged model servers
We provide optimized model servers for some of the most popular Deep Learning and Machine Learning frameworks that allow you to deploy your trained model binaries/weights without having to containerize or modify them.
You only have to upload your model binaries into your preferred object store, in this case we have a trained scikit-learn iris model in a Google bucket:
gs://seldon-models/v1.19.0-dev/sklearn/iris/model.joblibCreate a namespace to run your model in:
kubectl create namespace seldonWe then can deploy this model with Seldon Core to our Kubernetes cluster using the pre-packaged model server for scikit-learn (SKLEARN_SERVER) by running the kubectl apply command below:
$ kubectl apply -f - << END
apiVersion: machinelearning.seldon.io/v1
kind: SeldonDeployment
metadata:
name: iris-model
namespace: seldon
spec:
name: iris
predictors:
- graph:
implementation: SKLEARN_SERVER
modelUri: gs://seldon-models/v1.19.0-dev/sklearn/iris
name: classifier
name: default
replicas: 1
ENDSend API requests to your deployed model
Every model deployed exposes a standardised User Interface to send requests using our OpenAPI schema.
This can be accessed through the endpoint http://<ingress_url>/seldon/<namespace>/<model-name>/api/v1.0/doc/ which will allow you to send requests directly through your browser.
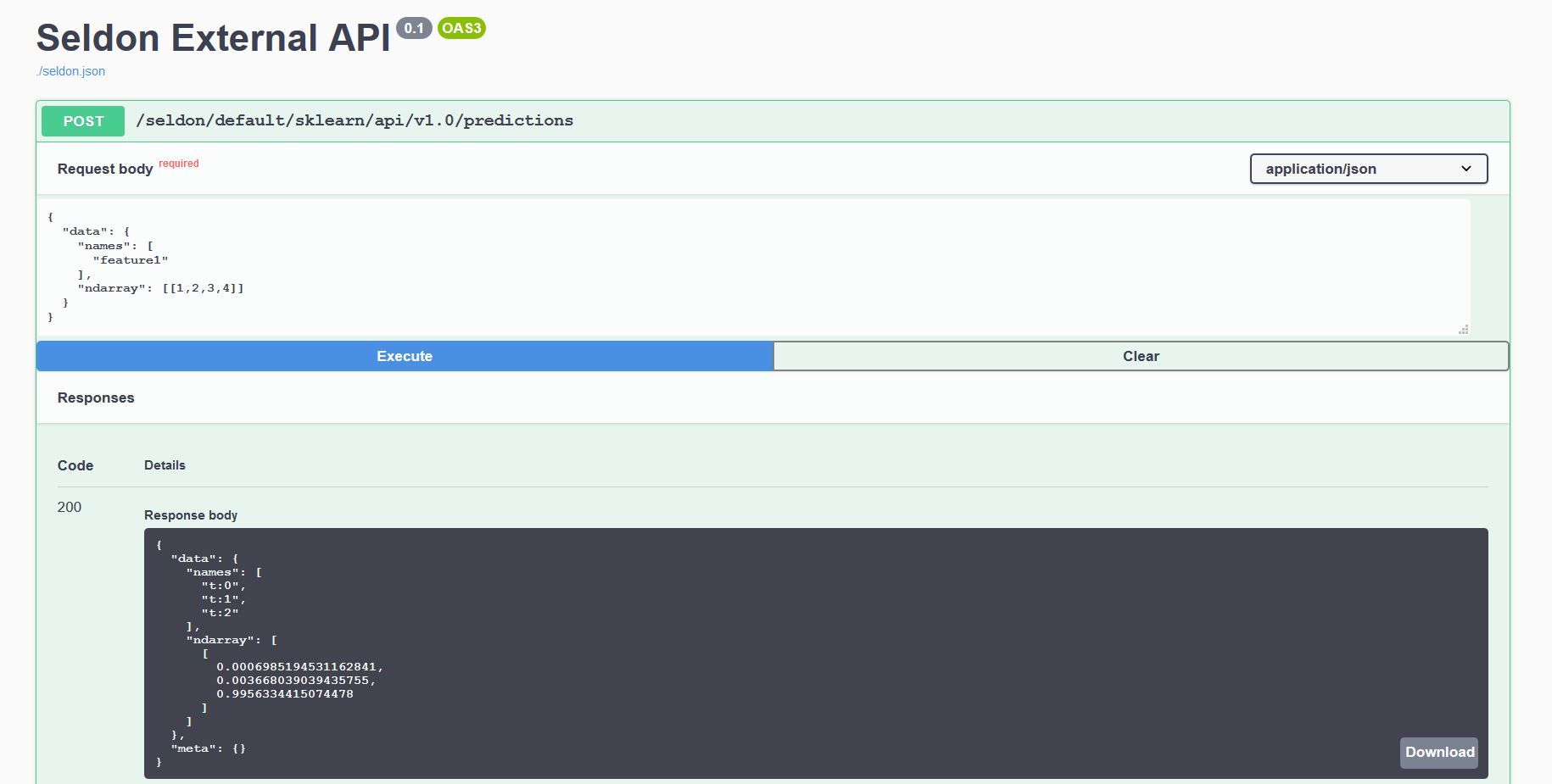
Or alternatively you can send requests programmatically using our Seldon Python Client or another Linux CLI:
$ curl -X POST http://<ingress>/seldon/seldon/iris-model/api/v1.0/predictions \
-H 'Content-Type: application/json' \
-d '{ "data": { "ndarray": [[1,2,3,4]] } }'
{
"meta" : {},
"data" : {
"names" : [
"t:0",
"t:1",
"t:2"
],
"ndarray" : [
[
0.000698519453116284,
0.00366803903943576,
0.995633441507448
]
]
}
}Deploy your custom model using language wrappers
For more custom deep learning and machine learning use-cases which have custom dependencies (such as 3rd party libraries, operating system binaries or even external systems), we can use any of the Seldon Core language wrappers.
You only have to write a class wrapper that exposes the logic of your model; for example in Python we can create a file Model.py:
import pickle
class Model:
def __init__(self):
self._model = pickle.loads( open("model.pickle", "rb") )
def predict(self, X):
output = self._model(X)
return outputWe can now containerize our class file using the Seldon Core s2i utils to produce the sklearn_iris image:
s2i build . seldonio/seldon-core-s2i-python3:0.18 sklearn_iris:0.1And we now deploy it to our Seldon Core Kubernetes Cluster:
$ kubectl apply -f - << END
apiVersion: machinelearning.seldon.io/v1
kind: SeldonDeployment
metadata:
name: iris-model
namespace: model-namespace
spec:
name: iris
predictors:
- componentSpecs:
- spec:
containers:
- name: classifier
image: sklearn_iris:0.1
graph:
name: classifier
name: default
replicas: 1
ENDSend API requests to your deployed model
Every model deployed exposes a standardised User Interface to send requests using our OpenAPI schema.
This can be accessed through the endpoint http://<ingress_url>/seldon/<namespace>/<model-name>/api/v1.0/doc/ which will allow you to send requests directly through your browser.
Or alternatively you can send requests programmatically using our Seldon Python Client or another Linux CLI:
$ curl -X POST http://<ingress>/seldon/model-namespace/iris-model/api/v1.0/predictions \
-H 'Content-Type: application/json' \
-d '{ "data": { "ndarray": [1,2,3,4] } }' | json_pp
{
"meta" : {},
"data" : {
"names" : [
"t:0",
"t:1",
"t:2"
],
"ndarray" : [
[
0.000698519453116284,
0.00366803903943576,
0.995633441507448
]
]
}
}Dive into the Advanced Production ML Integrations
Any model that is deployed and orchestrated with Seldon Core provides out of the box machine learning insights for monitoring, managing, scaling and debugging.
Below are some of the core components together with link to the logs that provide further insights on how to set them up.
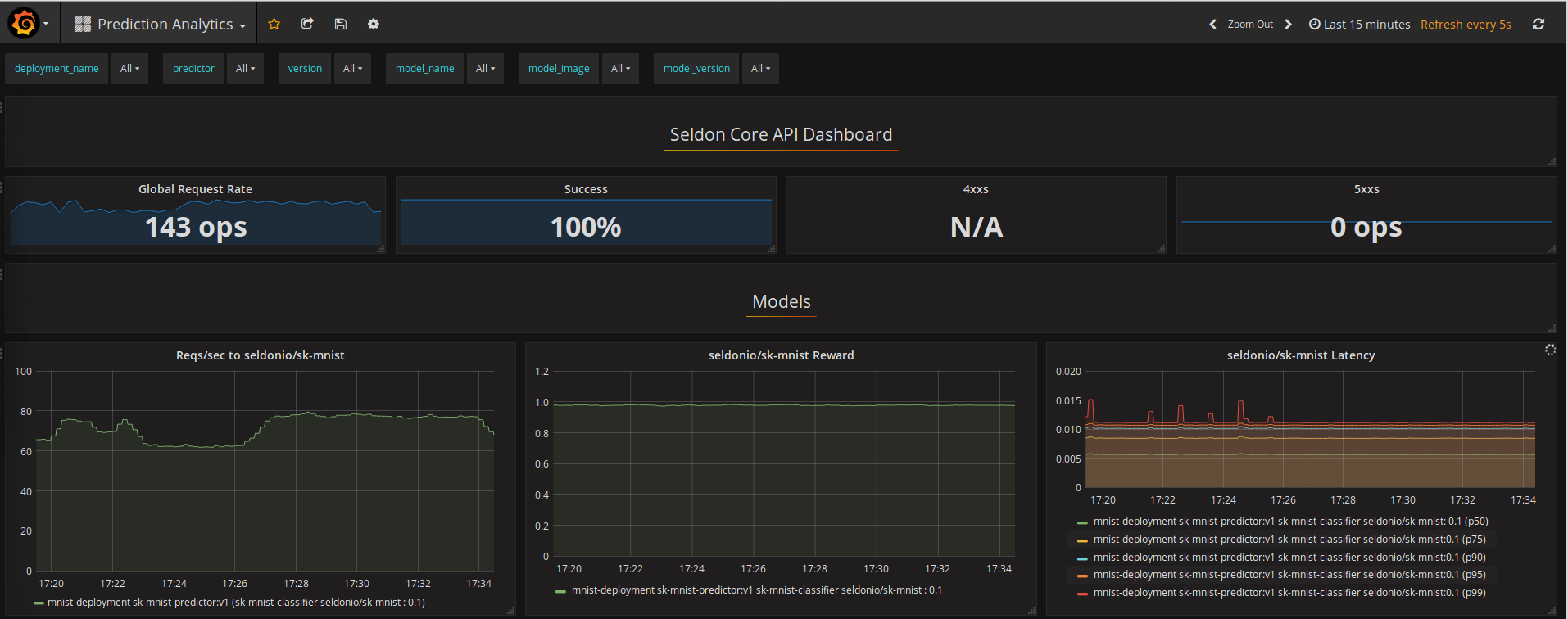
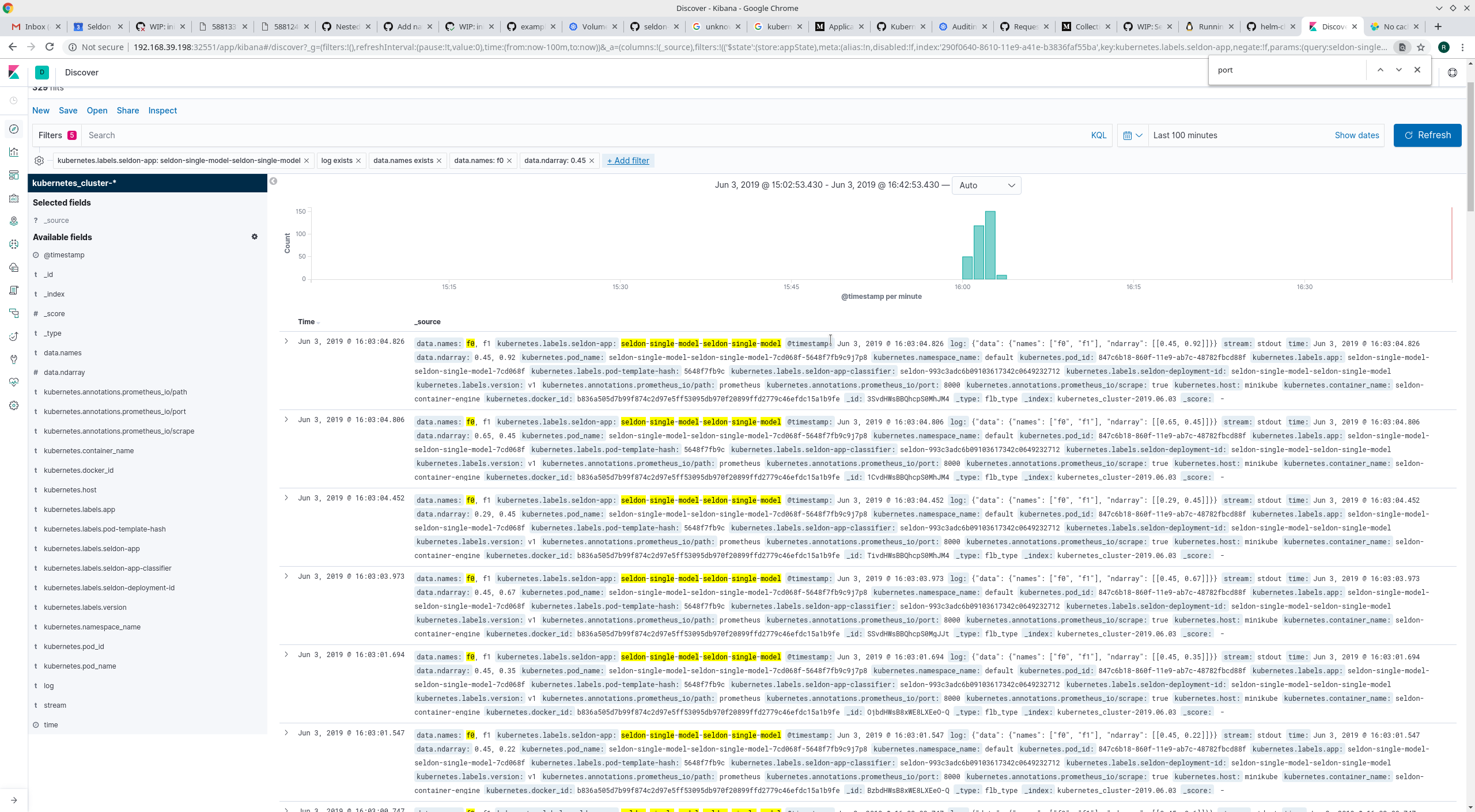

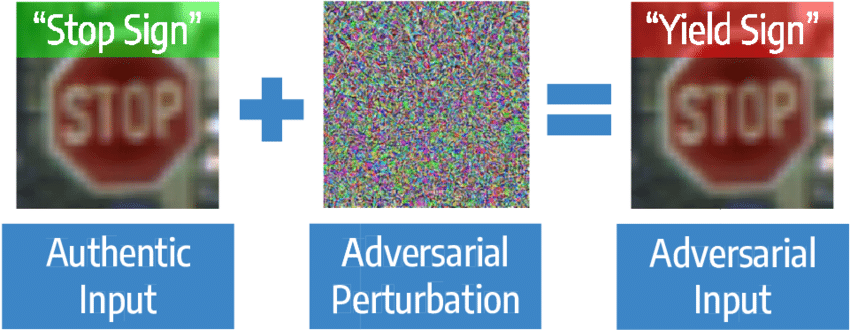
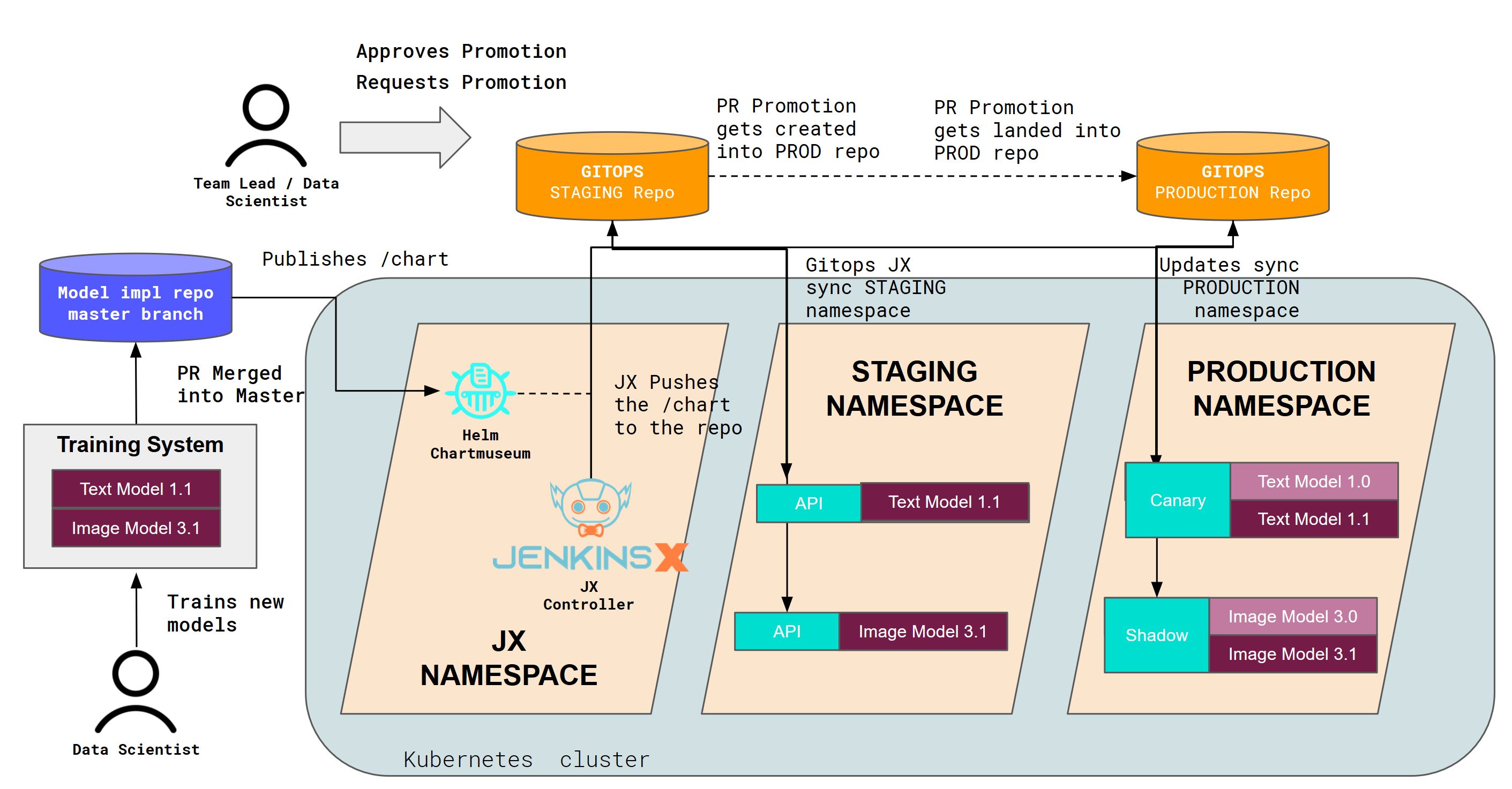
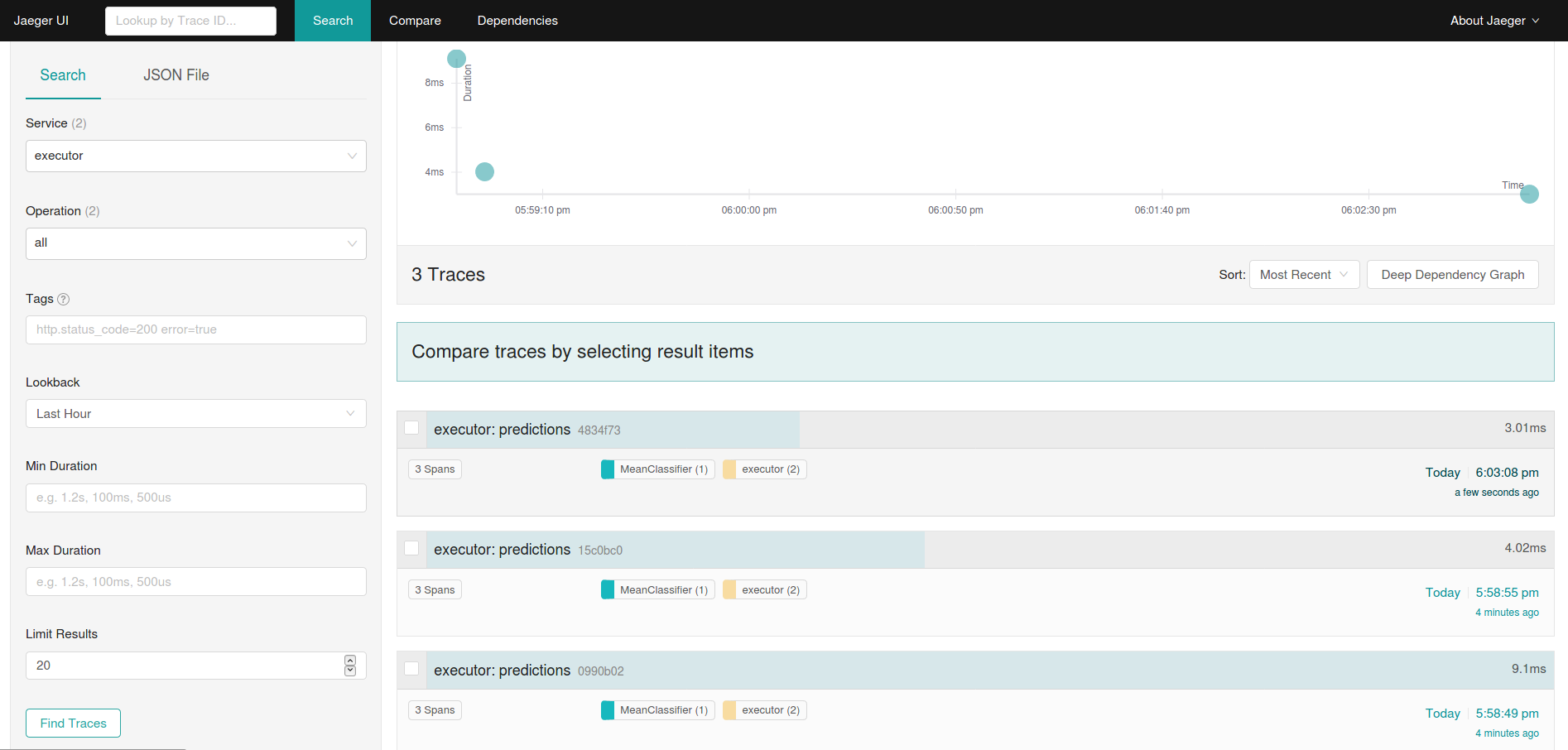
Where to go from here
Getting Started
Seldon Core Deep Dive
- Detailed Installation Parameters
- Pre-packaged Inference Servers
- Language Wrappers for Custom Models
- Create your Inference Graph
- Deploy your Model
- Testing your Model Endpoints
- Troubleshooting guide
- Usage reporting
- Upgrading
- Changelog
Pre-Packaged Inference Servers
Language Wrappers (Production)
Language Wrappers (Incubating)
- Java Language Wrapper [Incubating]
- R Language Wrapper [ALPHA]
- NodeJS Language Wrapper [ALPHA]
- Go Language Wrapper [ALPHA]
Ingress
Production
- Supported API Protocols
- CI/CD MLOps at Scale
- Metrics with Prometheus
- Payload Logging with ELK
- Distributed Tracing with Jaeger
- Replica Scaling
- Budgeting Disruptions
- Custom Inference Servers
Advanced Inference
Examples
Reference
- Annotation-based Configuration
- Benchmarking
- General Availability
- Helm Charts
- Images
- Logging & Log Level
- Private Docker Registry
- Prediction APIs
- Python API reference
- Release Highlights
- Seldon Deployment CRD
- Service Orchestrator
- Kubeflow
Developer
About the name "Seldon Core"
The name Seldon (ˈSɛldən) Core was inspired from the Foundation Series (Sci-fi novels) where its premise consists of a mathematician called "Hari Seldon" who spends his life developing a theory of Psychohistory, a new and effective mathematical sociology which allows for the future to be predicted extremely accurate through long periods of time (across hundreds of thousands of years).
Commercial Offerings
To learn more about our commercial offerings visit https://www.seldon.io/.