
![]()
![]()
KeyDB is now a part of Snap Inc! Check out the announcement here
Release v6.3.0 is here with major improvements as we consolidate our Open Source and Enterprise offerings into a single BSD-3 licensed project. See our roadmap for details.
Want to extend KeyDB with Javascript? Try ModJS
Need Help? Check out our extensive documentation.
KeyDB is on Slack. Click here to learn more and join the KeyDB Community Slack workspace.
What is KeyDB?
KeyDB is a high performance fork of Redis with a focus on multithreading, memory efficiency, and high throughput. In addition to performance improvements, KeyDB offers features such as Active Replication, FLASH Storage and Subkey Expires. KeyDB has a MVCC architecture that allows you to execute queries such as KEYS and SCAN without blocking the database and degrading performance.
KeyDB maintains full compatibility with the Redis protocol, modules, and scripts. This includes the atomicity guarantees for scripts and transactions. Because KeyDB keeps in sync with Redis development KeyDB is a superset of Redis functionality, making KeyDB a drop in replacement for existing Redis deployments.
On the same hardware KeyDB can achieve significantly higher throughput than Redis. Active-Replication simplifies hot-spare failover allowing you to easily distribute writes over replicas and use simple TCP based load balancing/failover. KeyDB's higher performance allows you to do more on less hardware which reduces operation costs and complexity.
The chart below compares several KeyDB and Redis setups, including the latest Redis6 io-threads option, and TLS benchmarks.
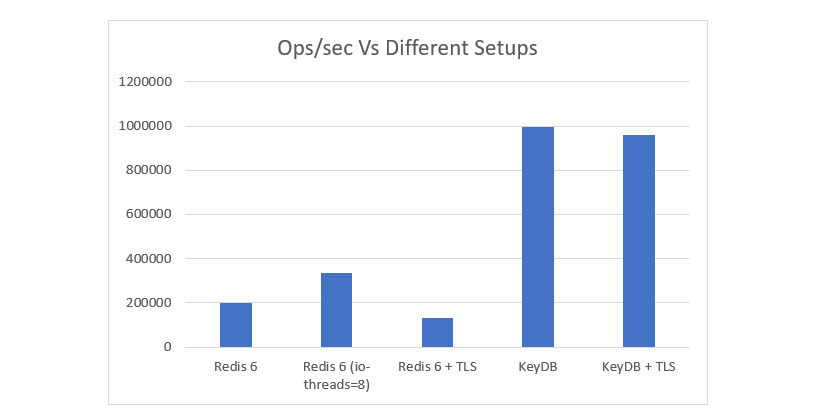
See the full benchmark results and setup information here: https://docs.keydb.dev/blog/2020/09/29/blog-post/
Why fork Redis?
KeyDB has a different philosophy on how the codebase should evolve. We feel that ease of use, high performance, and a "batteries included" approach is the best way to create a good user experience. While we have great respect for the Redis maintainers it is our opinion that the Redis approach focuses too much on simplicity of the code base at the expense of complexity for the user. This results in the need for external components and workarounds to solve common problems - resulting in more complexity overall.
Because of this difference of opinion features which are right for KeyDB may not be appropriate for Redis. A fork allows us to explore this new development path and implement features which may never be a part of Redis. KeyDB keeps in sync with upstream Redis changes, and where applicable we upstream bug fixes and changes. It is our hope that the two projects can continue to grow and learn from each other.
Project Support
The KeyDB team maintains this project as part of Snap Inc. KeyDB is used by Snap as part of its caching infrastructure and is fully open sourced. There is no separate commercial product and no paid support options available. We really value collaborating with the open source community and welcome PRs, bug reports, and open discussion. For community support or to get involved further with the project check out our community support options here (slack, forum, meetup, github issues). Our team monitors these channels regularly.
Additional Resources
Try the KeyDB Docker Image
Join us on Slack
Learn more using KeyDB's extensive documentation
See the KeyDB Roadmap to see what's in store
Benchmarking KeyDB
Please note keydb-benchmark and redis-benchmark are currently single threaded and too slow to properly benchmark KeyDB. We recommend using a redis cluster benchmark tool such as memtier. Please ensure your machine has enough cores for both KeyDB and memtier if testing locally. KeyDB expects exclusive use of any cores assigned to it.
New Configuration Options
With new features comes new options. All other configuration options behave as you'd expect. Your existing configuration files should continue to work unchanged.
server-threads N
server-thread-affinity [true/false]The number of threads used to serve requests. This should be related to the number of queues available in your network hardware, not the number of cores on your machine. Because KeyDB uses spinlocks to reduce latency; making this too high will reduce performance. We recommend using 4 here. By default this is set to two.
min-clients-per-thread 50The minimum number of clients on a thread before KeyDB assigns new connections to a different thread. Tuning this parameter is a tradeoff between locking overhead and distributing the workload over multiple cores
replica-weighting-factor 2KeyDB will attempt to balance clients across threads evenly; However, replica clients are usually much more expensive than a normal client, and so KeyDB will try to assign fewer clients to threads with a replica. The weighting factor below is intended to help tune this behavior. A replica weighting factor of 2 means we treat a replica as the equivalent of two normal clients. Adjusting this value may improve performance when replication is used. The best weighting is workload specific - e.g. read heavy workloads should set this to 1. Very write heavy workloads may benefit from higher numbers.
active-client-balancing yesShould KeyDB make active attempts at balancing clients across threads? This can impact performance accepting new clients. By default this is enabled. If disabled there is still a best effort from the kernel to distribute across threads with SO_REUSEPORT but it will not be as fair. By default this is enabled
active-replica yesIf you are using active-active replication set active-replica option to “yes”. This will enable both instances to accept reads and writes while remaining synced. Click here to see more on active-rep in our docs section. There are also docker examples on docs.
multi-master-no-forward noAvoid forwarding RREPLAY messages to other masters? WARNING: This setting is dangerous! You must be certain all masters are connected to eachother in a true mesh topology or data loss will occur! This command can be used to reduce multimaster bus traffic
db-s3-object /path/to/bucketIf you would like KeyDB to dump and load directly to AWS S3 this option specifies the bucket. Using this option with the traditional RDB options will result in KeyDB backing up twice to both locations. If both are specified KeyDB will first attempt to load from the local dump file and if that fails load from S3. This requires the AWS CLI tools to be installed and configured which are used under the hood to transfer the data.
storage-provider flash /path/to/flashIf you would like to use KeyDB FLASH storage, specify the storage medium followed by the directory path on your local SSD volume. Note that this feature is still considered experimental and should be used with discretion. See FLASH Documentation for more details on configuration and setting up your FLASH volume.
Building KeyDB
KeyDB can be compiled and is tested for use on Linux. KeyDB currently relies on SO_REUSEPORT's load balancing behavior which is available only in Linux. When we support marshalling connections across threads we plan to support other operating systems such as FreeBSD.
More on CentOS/Archlinux/Alpine/Debian/Ubuntu dependencies and builds can be found here: https://docs.keydb.dev/docs/build/
Init and clone submodule dependencies:
% git submodule init && git submodule updateInstall dependencies:
% sudo apt install build-essential nasm autotools-dev autoconf libjemalloc-dev tcl tcl-dev uuid-dev libcurl4-openssl-dev libbz2-dev libzstd-dev liblz4-dev libsnappy-dev libssl-devCompiling is as simple as:
% makeTo build with systemd support, you'll need systemd development libraries (such as libsystemd-dev on Debian/Ubuntu or systemd-devel on CentOS) and run:
% make USE_SYSTEMD=yesTo append a suffix to KeyDB program names, use:
% make PROG_SUFFIX="-alt"***Note that the following dependencies may be needed: % sudo apt-get install autoconf autotools-dev libnuma-dev libtool
KeyDB by default is built with TLS enabled. To build without TLS support, use:
% make BUILD_TLS=noRunning the tests with TLS enabled (you will need tcl-tls
installed):
% ./utils/gen-test-certs.sh
% ./runtest --tlsTo build with KeyDB FLASH support, use:
% make ENABLE_FLASH=yes***Note that the KeyDB FLASH feature is considered experimental (beta) and should used with discretion
Fixing build problems with dependencies or cached build options
KeyDB has some dependencies which are included in the deps directory.
make does not automatically rebuild dependencies even if something in
the source code of dependencies changes.
When you update the source code with git pull or when code inside the
dependencies tree is modified in any other way, make sure to use the following
command in order to really clean everything and rebuild from scratch:
make distcleanThis will clean: jemalloc, lua, hiredis, linenoise.
Also if you force certain build options like 32bit target, no C compiler
optimizations (for debugging purposes), and other similar build time options,
those options are cached indefinitely until you issue a make distclean
command.
Fixing problems building 32 bit binaries
If after building KeyDB with a 32 bit target you need to rebuild it
with a 64 bit target, or the other way around, you need to perform a
make distclean in the root directory of the KeyDB distribution.
In case of build errors when trying to build a 32 bit binary of KeyDB, try the following steps:
- Install the package libc6-dev-i386 (also try g++-multilib).
- Try using the following command line instead of
make 32bit:make CFLAGS="-m32 -march=native" LDFLAGS="-m32"
Allocator
Selecting a non-default memory allocator when building KeyDB is done by setting
the MALLOC environment variable. KeyDB is compiled and linked against libc
malloc by default, with the exception of jemalloc being the default on Linux
systems. This default was picked because jemalloc has proven to have fewer
fragmentation problems than libc malloc.
To force compiling against libc malloc, use:
% make MALLOC=libcTo compile against jemalloc on Mac OS X systems, use:
% make MALLOC=jemallocMonotonic clock
By default, KeyDB will build using the POSIX clock_gettime function as the monotonic clock source. On most modern systems, the internal processor clock can be used to improve performance. Cautions can be found here: http://oliveryang.net/2015/09/pitfalls-of-TSC-usage/
To build with support for the processor's internal instruction clock, use:
% make CFLAGS="-DUSE_PROCESSOR_CLOCK"Verbose build
KeyDB will build with a user friendly colorized output by default. If you want to see a more verbose output, use the following:
% make V=1Running KeyDB
To run KeyDB with the default configuration, just type:
% cd src
% ./keydb-serverIf you want to provide your keydb.conf, you have to run it using an additional parameter (the path of the configuration file):
% cd src
% ./keydb-server /path/to/keydb.confIt is possible to alter the KeyDB configuration by passing parameters directly as options using the command line. Examples:
% ./keydb-server --port 9999 --replicaof 127.0.0.1 6379
% ./keydb-server /etc/keydb/6379.conf --loglevel debugAll the options in keydb.conf are also supported as options using the command line, with exactly the same name.
Running KeyDB with TLS:
Please consult the TLS.md file for more information on how to use KeyDB with TLS.
Playing with KeyDB
You can use keydb-cli to play with KeyDB. Start a keydb-server instance, then in another terminal try the following:
% cd src
% ./keydb-cli
keydb> ping
PONG
keydb> set foo bar
OK
keydb> get foo
"bar"
keydb> incr mycounter
(integer) 1
keydb> incr mycounter
(integer) 2
keydb>You can find the list of all the available commands at https://docs.keydb.dev/docs/commands/
Installing KeyDB
In order to install KeyDB binaries into /usr/local/bin, just use:
% make installYou can use make PREFIX=/some/other/directory install if you wish to use a
different destination.
Make install will just install binaries in your system, but will not configure init scripts and configuration files in the appropriate place. This is not needed if you just want to play a bit with KeyDB, but if you are installing it the proper way for a production system, we have a script that does this for Ubuntu and Debian systems:
% cd utils
% ./install_server.shNote: install_server.sh will not work on Mac OSX; it is built for Linux only.
The script will ask you a few questions and will setup everything you need to run KeyDB properly as a background daemon that will start again on system reboots.
You'll be able to stop and start KeyDB using the script named
/etc/init.d/keydb_<portnumber>, for instance /etc/init.d/keydb_6379.
Multithreading Architecture
KeyDB works by running the normal Redis event loop on multiple threads. Network IO, and query parsing are done concurrently. Each connection is assigned a thread on accept(). Access to the core hash table is guarded by spinlock. Because the hashtable access is extremely fast this lock has low contention. Transactions hold the lock for the duration of the EXEC command. Modules work in concert with the GIL which is only acquired when all server threads are paused. This maintains the atomicity guarantees modules expect.
Unlike most databases the core data structure is the fastest part of the system. Most of the query time comes from parsing the REPL protocol and copying data to/from the network.
Code contributions
Note: by contributing code to the KeyDB project in any form, including sending a pull request via Github, a code fragment or patch via private email or public discussion groups, you agree to release your code under the terms of the BSD license that you can find in the COPYING file included in the KeyDB source distribution.
Please see the CONTRIBUTING file in this source distribution for more information.