Tanuki 🦝 
Easily build LLM-powered apps that get cheaper and faster over time.
Join us on Discord
Contents
## Introduction
Tanuki is a way to easily call an LLM in place of the function body in Python, with the same parameters and output that you would expect from a function implemented by hand.
These LLM-powered functions are well-typed, reliable, stateless, and production-ready to be dropped into your app seamlessly. Rather than endless prompt-wrangling and nasty surprises, these LLM-powered functions and applications behave like traditional functions with proper error handling.
Lastly, the more you use Tanuki functions, the cheaper and faster they gets (up to 9-10x!) through automatic model distillation.
```python
@tanuki.patch
def some_function(input: TypedInput) -> TypedOutput:
"""(Optional) Include the description of how your function will be used."""
@tanuki.align
def test_some_function(example_typed_input: TypedInput,
example_typed_output: TypedOutput):
assert some_function(example_typed_input) == example_typed_output
```
## Features
- **Easy and seamless integration** - Add LLM augmented functions to any workflow within seconds. Decorate a function stub with `@tanuki.patch` and optionally add type hints and docstrings to guide the execution. That’s it.
- **Type aware** - Ensure that the outputs of the LLM adhere to the type constraints of the function (Python Base types, Pydantic classes, Literals, Generics etc) to guard against bugs or unexpected side-effects of using LLMs.
- **Aligned outputs** - LLMs are unreliable, which makes them difficult to use in place of classically programmed functions. Using simple assert statements in a function decorated with `@tanuki.align`, you can align the behaviour of your patched function to what you expect.
- **Lower cost and latency** - Achieve up to 90% lower cost and 80% lower latency with increased usage. The package will take care of model training, MLOps and DataOps efforts to improve LLM capabilities through distillation.
- **Popular model support** - Tanuki supports a wide array of popular models (OpenAI, Amazon Bedrock, Together AI) to carry out the function execution
- **RAG support** - Seamlessly get embedding outputs for downstream RAG (Retrieval Augmented Generation) implementations. Output embeddings can then be easily stored and used for relevant document retrieval to reduce cost & latency and improve performance on long-form content.
- **Batteries included** - No remote dependencies other than OpenAI.
## Installation and Getting Started
### Installation
```
pip install tanuki.py
```
or with Poetry
```
poetry add tanuki.py
```
Set your OpenAI key using:
```
export OPENAI_API_KEY=sk-...
```
### Getting Started
To get started:
1. Create a python function stub decorated with `@tanuki.patch` including type hints and a docstring.
2. (Optional) Create another function decorated with `@tanuki.align` containing normal `assert` statements declaring the expected behaviour of your patched function with different inputs.
3. (Optional) Configure the model you want to use the function for. By default GPT-4 is used but if you want to use any other models supported in our stack, then configure them in the `@tanuki.patch` operator. You can find out exactly how to configure [Amazon Bedrock](https://github.com/Tanuki/tanuki.py/blob/master/docs/aws_bedrock.md) models and [Together AI](https://github.com/Tanuki/tanuki.py/blob/master/docs/together_ai.md) models in our docs.
The patched function can now be called as normal in the rest of your code.
To add functional alignment, the functions annotated with `align` must also be called if:
- It is the first time calling the patched function (including any updates to the function signature, i.e docstring, input arguments, input type hints, naming or the output type hint)
- You have made changes to your assert statements.
Here is what it could look like for a simple classification function:
```python
@tanuki.patch
def classify_sentiment(msg: str) -> Optional[Literal['Good', 'Bad']]:
"""Classifies a message from the user into Good, Bad or None."""
@tanuki.align
def align_classify_sentiment():
assert classify_sentiment("I love you") == 'Good'
assert classify_sentiment("I hate you") == 'Bad'
assert not classify_sentiment("People from Phoenix are called Phoenicians")
if __name__ == "__main__":
align_classify_sentiment()
print(classify_sentiment("I like you")) # Good
print(classify_sentiment("Apples might be red")) # None
```
See [here](https://github.com/monkeypatch/tanuki.py/blob/update_docs/docs/function_configurability.md) for configuration options for patched Tanuki functions
## How It Works
When you call a tanuki-patched function during development, an LLM in a n-shot configuration is invoked to generate the typed response.
The number of examples used is dependent on the number of align statements supplied in functions annotated with the align decorator.
The response will be post-processed and the supplied output type will be programmatically instantiated ensuring that the correct type is returned.
This response can be passed through to the rest of your app / stored in the DB / displayed to the user.
Make sure to execute all align functions at least once before running your patched functions to ensure that the expected behaviour is registered. These are cached onto the disk for future reference.
The inputs and outputs of the function will be stored during execution as future training data.
As your data volume increases, smaller and smaller models will be distilled using the outputs of larger models.
The smaller models will capture the desired behaviour and performance at a lower computational cost, lower latency and without any MLOps effort.
## Typed Outputs
LLM API outputs are typically in natural language. In many instances, it’s preferable to have constraints on the format of the output to integrate them better into workflows.
A core concept of Tanuki is the support for typed parameters and outputs. Supporting typed outputs of patched functions allows you to declare *rules about what kind of data the patched function is allowed to pass back* for use in the rest of your program. This will guard against the verbose or inconsistent outputs of the LLMs that are trained to be as “helpful as possible”.
You can use Literals or create custom types in Pydantic to express very complex rules about what the patched function can return. These act as guard-rails for the model preventing a patched function breaking the code or downstream workflows, and means you can avoid having to write custom validation logic in your application.
```python
@dataclass
class ActionItem:
goal: str = Field(description="What task must be completed")
deadline: datetime = Field(description="The date the goal needs to be achieved")
@tanuki.patch
def action_items(input: str) -> List[ActionItem]:
"""Generate a list of Action Items"""
@tanuki.align
def align_action_items():
goal = "Can you please get the presentation to me by Tuesday?"
next_tuesday = (datetime.now() + timedelta((1 - datetime.now().weekday() + 7) % 7)).replace(hour=0, minute=0, second=0, microsecond=0)
assert action_items(goal) == ActionItem(goal="Prepare the presentation", deadline=next_tuesday)
```
By constraining the types of data that can pass through your patched function, you are declaring the potential outputs that the model can return and specifying the world where the program exists in.
You can add integer constraints to the outputs for Pydantic field values, and generics if you wish.
```python
@tanuki.patch
def score_sentiment(input: str) -> Optional[Annotated[int, Field(gt=0, lt=10)]]:
"""Scores the input between 0-10"""
@tanuki.align
def align_score_sentiment():
"""Register several examples to align your function"""
assert score_sentiment("I love you") == 10
assert score_sentiment("I hate you") == 0
assert score_sentiment("You're okay I guess") == 5
# This is a normal test that can be invoked with pytest or unittest
def test_score_sentiment():
"""We can test the function as normal using Pytest or Unittest"""
score = score_sentiment("I like you")
assert score >= 7
if __name__ == "__main__":
align_score_sentiment()
print(score_sentiment("I like you")) # 7
print(score_sentiment("Apples might be red")) # None
```
To see more examples using Tanuki for different use cases (including how to integrate with FastAPI), have a look at [examples](https://github.com/monkeypatch/tanuki.py/tree/master/examples).
For embedding outputs for RAG support, see [here](https://github.com/monkeypatch/tanuki.py/blob/update_docs/docs/embeddings_support.md)
## Test-Driven Alignment
In classic [test-driven development (TDD)](https://en.wikipedia.org/wiki/Test-driven_development), the standard practice is to write a failing test before writing the code that makes it pass.
Test-Driven Alignment (TDA) adapts this concept to align the behavior of a patched function with an expectation defined by a test.
To align the behaviour of your patched function to your needs, decorate a function with `@align` and assert the outputs of the function with the ‘assert’ statement as is done with standard tests.
```python
@tanuki.align
def align_classify_sentiment():
assert classify_sentiment("I love this!") == 'Good'
assert classify_sentiment("I hate this.") == 'Bad'
@tanuki.align
def align_score_sentiment():
assert score_sentiment("I like you") == 7
```
By writing a test that encapsulates the expected behaviour of the tanuki-patched function, you declare the contract that the function must fulfill. This enables you to:
1. **Verify Expectations:** Confirm that the function adheres to the desired output.
2. **Capture Behavioural Nuances:** Make sure that the LLM respects the edge cases and nuances stipulated by your test.
3. **Develop Iteratively:** Refine and update the behavior of the tanuki-patched function by declaring the desired behaviour as tests.
Unlike traditional TDD, where the objective is to write code that passes the test, TDA flips the script: **tests do not fail**. Their existence and the form they take are sufficient for LLMs to align themselves with the expected behavior.
TDA offers a lean yet robust methodology for grafting machine learning onto existing or new Python codebases. It combines the preventive virtues of TDD while addressing the specific challenges posed by the dynamism of LLMs.
---
(Aligning function chains is work in progress)
```python
def test_score_sentiment():
"""We can test the function as normal using Pytest or Unittest"""
assert multiply_by_two(score_sentiment("I like you")) == 14
assert 2*score_sentiment("I like you") == 14
```
## Scaling and Finetuning
An advantage of using Tanuki in your workflow is the cost and latency benefits that will be provided as the number of datapoints increases.
Successful executions of your patched function suitable for finetuning will be persisted to a training dataset, which will be used to distil smaller models for each patched function. Model distillation and pseudo-labelling is a verified way how to cut down on model sizes and gain improvements in latency and memory footprints while incurring insignificant and minor cost to performance (https://arxiv.org/pdf/2305.02301.pdf, https://arxiv.org/pdf/2306.13649.pdf, https://arxiv.org/pdf/2311.00430.pdf, etc).
Training smaller function-specific models and deploying them is handled by the Tanuki library, so the user will get the benefits without any additional MLOps or DataOps effort. Note: Finetuning currently is available only from GPT-4 (teacher) to GPT-3.5 (Student), it is not yet implemented for AWS Bedrock and Together AI models
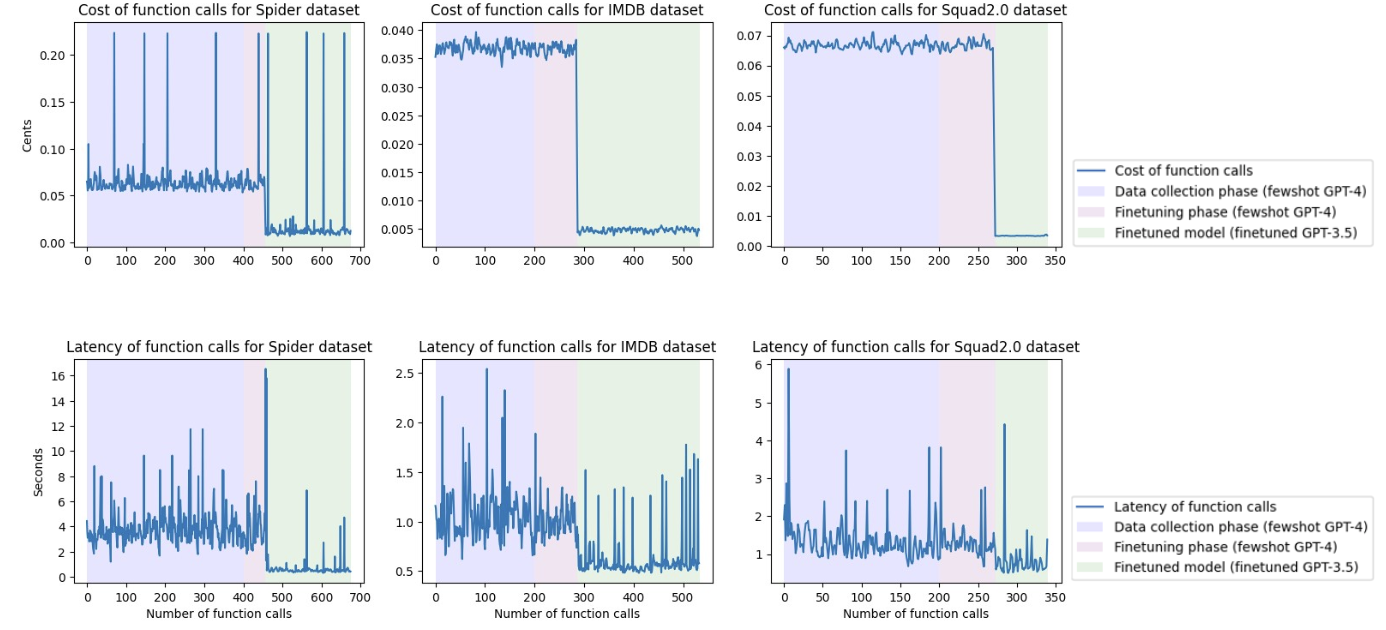
We tested out model distillation using Tanuki using OpenAI models on Squad2, Spider and IMDB Movie Reviews datasets. We finetuned the GPT-3.5-turbo model (student) using few-shot responses of GPT-4 (teacher) and our preliminary tests show that using less than 600 datapoints in the training data we were able to get GPT-3.5 turbo to perform essentialy equivalent (less than 1.5% of performance difference on held-out dev sets) to GPT-4 while achieving up to 12 times lower cost and over 6 times lower latency (cost and latency reduction are very dependent on task specific characteristics like input-output token sizes and align statement token sizes). These tests show the potential in model-distillation in this form for intelligently cutting costs and lowering latency without sacrificing performance.
## Frequently Asked Questions
### Intro
#### What is Tanuki in plain words?
Tanuki is a simple and seamless way to create LLM augmented functions in python, which ensure the outputs of the LLMs follow a specific structure. Moreover, the more you call a patched function, the cheaper and faster the execution gets.
#### How does this compare to other frameworks like LangChain?
- **Langchain**: Tanuki has a narrower scope than Langchain. Our mission is to ensure predictable and consistent LLM execution, with automatic reductions in cost and latency through finetuning.
- **Magentic** / **Marvin**: Tanuki offers two main benefits compared to Magentic/Marvin, namely; lower cost and latency through automatic distillation, and more predictable behaviour through test-driven alignment. Currently, there are two cases where you should use Magentic, namely: where you need support for tools (functions) - a feature that is on our roadmap, and where you need support for asynchronous functions.
#### What are some sample use-cases?
We've created a few examples to show how to use Tanuki for different problems. You can find them [here](https://github.com/monkeypatch/tanuki.py/tree/master/examples).
A few ideas are as follows:
- Adding an importance classifier to customer requests
- Creating a offensive-language classification feature
- Creating a food-review app
- Generating data that conforms to your DB schema that can immediately
#### Why would I need typed responses?
When invoking LLMs, the outputs are free-form. This means that they are less predictable when used in software products. Using types ensures that the outputs adhere to specific constraints or rules which the rest of your program can work with.
#### Do you offer this for other languages (eg Typescript)?
Not right now but reach out on [our Discord server](https://discord.gg/kEGS5sQU) or make a Github issue if there’s another language you would like to see supported.
### Getting Started
#### How do I get started?
Follow the instructions in the [Installation and getting started]() and [How it works]() sections
#### How do I align my functions?
See [How it works]() and [Test-Driven Alignment]() sections or the examples shown [here](https://github.com/monkeypatch/tanuki.py/tree/master/examples).
#### Do I need my own OpenAI key?
Yes
#### Does it only work with OpenAI?
Currently yes but there are plans to support Anthropic and popular open-source models. If you have a specific request, either join [our Discord server](https://discord.gg/kEGS5sQU), or create a Github issue.
### How It Works
#### How does the LLM get cheaper and faster over time? And by how much?
In short, we use distillation of LLM models.
Expanded, using the outputs of the larger (teacher) model, a smaller (student) model will be trained to emulate the teacher model behaviour while being faster and cheaper to run due to smaller size. In some cases it is possible to achieve up to 90% lower cost and 80% lower latency with a small number of executions of your patched functions.
#### How many calls does it require to get the improvement?
The default minimum is 200 calls, although this can be changed by adding flags to the patch decorator.
#### Can I link functions together?
Yes! It is possible to use the output of one patched function as the input to another patched function. Simply carry this out as you would do with normal python functions.
#### Does fine-tuning reduce the performance of the LLM?
Not necessarily. Currently the only way to improve the LLM performance is to have better align statements. As the student model is trained on both align statements and input-output calls, it is possible for the fine tuned student model to exceed the performance of the N-shot teacher model during inference.
### Accuracy & Reliability
#### How do you guarantee consistency in the output of patched functions?
Each output of the LLM will be programmatically instantiated into the output class ensuring the output will be of the correct type, just like your Python functions. If the output is incorrect and instantiating the correct output object fails, an automatic feedback repair loop kicks in to correct the mistake.
#### How reliable are the typed outputs?
For simpler-medium complexity classes GPT-4 with align statements has been shown to be very reliable in outputting the correct type. Additionally we have implemented a repair loop with error feedback to “fix” incorrect outputs and add the correct output to the training dataset.
#### How do you deal with hallucinations?
Hallucinations can’t be 100% removed from LLMs at the moment, if ever. However, by creating test functions decorated with `@tanuki.align`, you can use normal `assert` statements to align the model to behave in the way that you expect. Additionally, you can create types with Pydantic, which act as guardrails to prevent any nasty surprises and provide correct error handling.
#### How do you deal with bias?
By adding more align statements that cover a wider range of inputs, you can ensure that the model is less biased.
#### Will distillation impact performance?
It depends. For tasks that are challenging for even the best models (e.g GPT-4), distillation will reduce performance.
However, distillation can be manually turned off in these cases. Additionally, if the distilled model frequently fails to generate correct outputs, the distilled model will be automatically turned off.
#### What is this not suitable for?
- Time-series data
- Tasks that requires a lot of context to completed correctly
- For tasks that directly output complex natural language, you will get less value from Tanuki and may want to consider the OpenAI API directly.
---
## [Simple ToDo List App](https://github.com/monkeypatch/tanuki.py/tree/master/examples/todolist)