Tatoeba to Anki sentence pair flash card creator
Download decks for 39 languages here!
This project creates Anki flashcards from a Tatoeba language pair, ordering the cards by difficulty, downloading audio from Tatoeba (and high-quality Text-To-Speech if the native audio is not available) and reducing the card number to a set maximum.
The ordering algorithm takes the average frequency of each sentence and sentence length into account.
It also removes duplicates.
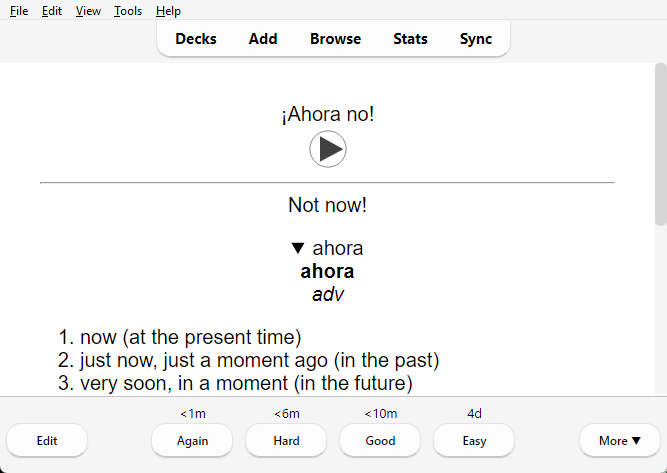
Additionally it supports the generation of automatic help to lookup single words directly on the back of the card. By default, it downloads a dictionary for this automatically (limited to English definitions currently). You can also pass a custom tabfile dictionary (use pyglossary to convert other dictionaries).
It should work for all languages pairs.
Running it
You should install it with pip install git+https://github.com/Vuizur/tatoeba-to-anki or poetry add git+https://github.com/Vuizur/tatoeba-to-anki.
Then use it from Python by creating a file example.py with the following content:
from tatoeba_to_anki import AnkiDeckCreator
adc = AnkiDeckCreator(
"Polish", "English", max_sentence_number=6000, tts_voices="pl-PL-ZofiaNeural", in_memory_database=False
)
adc.export_anki_deck()The parameter tts_voices is one (or a list) of the Edge TTS voices. For choosing the best one, you can use the read aloud function of the Edge browser. The strings you can use are listed in the voices.txt file under shortName.
I plan on adding more features, you can open an issue if you think something should be changed/improved or send a pull request.
Attribution
All the sentences come from the Tatoeba corpus and are available under the CC-BY 2.0 FR.
The definitions come from Wiktionary and are available under the Creative Commons Attribution-ShareAlike 3.0 Unported License
Acknowledgements
I thank the authors of the Tatoeba project, LBeaudoux (the creator of TatoebaTools) and Tatu Ylonen and the other contributors of the Wiktextract project for their hard work.
Interesting other projects:
-
This project for generating Swedish cards is pretty sophisticated and is probably worth understanding more fully
-
Sentence pairs is a pretty simple package which has given me the idea of using the wordfreq package
-
Older solutions such as Tatoeba-Ankigeneration scrape parts of the site by themselves, but that is not necessary anymore with the new downloadable data
-
Interesting article: https://digitalwords.net/anki/tatoeba-audio/index.eng.html