CodeShell VSCode Extension
codeshell-vscode项目是基于CodeShell大模型开发的支持Visual Studio Code的智能编码助手插件,支持python、java、c++/c、javascript、go等多种编程语言,为开发者提供代码补全、代码解释、代码优化、注释生成、对话问答等功能,旨在通过智能化的方式帮助开发者提高编程效率。
环境要求
- node版本v18及以上
- Visual Studio Code版本要求 1.68.1 及以上
- CodeShell 模型服务已启动
编译插件
如果要从源码进行打包,需要安装 node v18 以上版本,并执行以下命令:
git clone https://github.com/WisdomShell/codeshell-vscode.git
cd codeshell-vscode
npm install
npm exec vsce package然后会得到一个名为codeshell-vscode-${VERSION_NAME}.vsix的文件。
模型服务
llama_cpp_for_codeshell项目提供CodeShell大模型 4bits量化后的模型,模型名称为codeshell-chat-q4_0.gguf。以下为部署模型服务步骤:
编译代码
-
Linux / Mac(Apple Silicon设备)
git clone https://github.com/WisdomShell/llama_cpp_for_codeshell.git cd llama_cpp_for_codeshell make在 macOS 上,默认情况下启用了Metal,启用Metal可以将模型加载到 GPU 上运行,从而显著提升性能。
-
Mac(非Apple Silicon设备)
git clone https://github.com/WisdomShell/llama_cpp_for_codeshell.git cd llama_cpp_for_codeshell LLAMA_NO_METAL=1 make对于非 Apple Silicon 芯片的 Mac 用户,在编译时可以使用
LLAMA_NO_METAL=1或LLAMA_METAL=OFF的 CMake 选项来禁用Metal构建,从而使模型正常运行。 -
Windows
您可以选择在Windows Subsystem for Linux中按照Linux的方法编译代码,也可以选择参考llama.cpp仓库中的方法,配置好w64devkit后再按照Linux的方法编译。
下载模型
在Hugging Face Hub上,我们提供了三种不同的模型,分别是CodeShell-7B、CodeShell-7B-Chat和CodeShell-7B-Chat-int4。以下是下载模型的步骤。
-
使用CodeShell-7B-Chat-int4模型推理,将模型下载到本地后并放置在以上代码中的
llama_cpp_for_codeshell/models文件夹的路径git clone https://huggingface.co/WisdomShell/CodeShell-7B-Chat-int4/blob/main/codeshell-chat-q4_0.gguf -
使用CodeShell-7B、CodeShell-7B-Chat推理,将模型放置在本地文件夹后,使用TGI加载本地模型,启动模型服务
git clone https://huggingface.co/WisdomShell/CodeShell-7B-Chat
git clone https://huggingface.co/WisdomShell/CodeShell-7B加载模型
CodeShell-7B-Chat-int4模型使用llama_cpp_for_codeshell项目中的server命令即可提供API服务
./server -m ./models/codeshell-chat-q4_0.gguf --host 127.0.0.1 --port 8080注意:对于编译时启用了 Metal 的情况下,若运行时出现异常,您也可以在命令行添加参数 -ngl 0显式地禁用Metal GPU推理,从而使模型正常运行。
- CodeShell-7B和CodeShell-7B-Chat模型,使用TGI加载本地模型,启动模型服务
模型服务[NVIDIA GPU]
对于希望使用NVIDIA GPU进行推理的用户,可以使用text-generation-inference项目部署CodeShell大模型。以下为部署模型服务步骤:
下载模型
在 Hugging Face Hub将模型下载到本地后,将模型放置在 $HOME/models 文件夹的路径下,即可从本地加载模型。
git clone https://huggingface.co/WisdomShell/CodeShell-7B-Chat部署模型
使用以下命令即可用text-generation-inference进行GPU加速推理部署:
docker run --gpus 'all' --shm-size 1g -p 9090:80 -v $HOME/models:/data \
--env LOG_LEVEL="info,text_generation_router=debug" \
ghcr.nju.edu.cn/huggingface/text-generation-inference:1.0.3 \
--model-id /data/CodeShell-7B-Chat --num-shard 1 \
--max-total-tokens 5000 --max-input-length 4096 \
--max-stop-sequences 12 --trust-remote-code更详细的参数说明请参考text-generation-inference项目文档。
配置插件
VSCode中执行Install from VSIX...命令,选择codeshell-vscode-${VERSION_NAME}.vsix,完成插件安装。
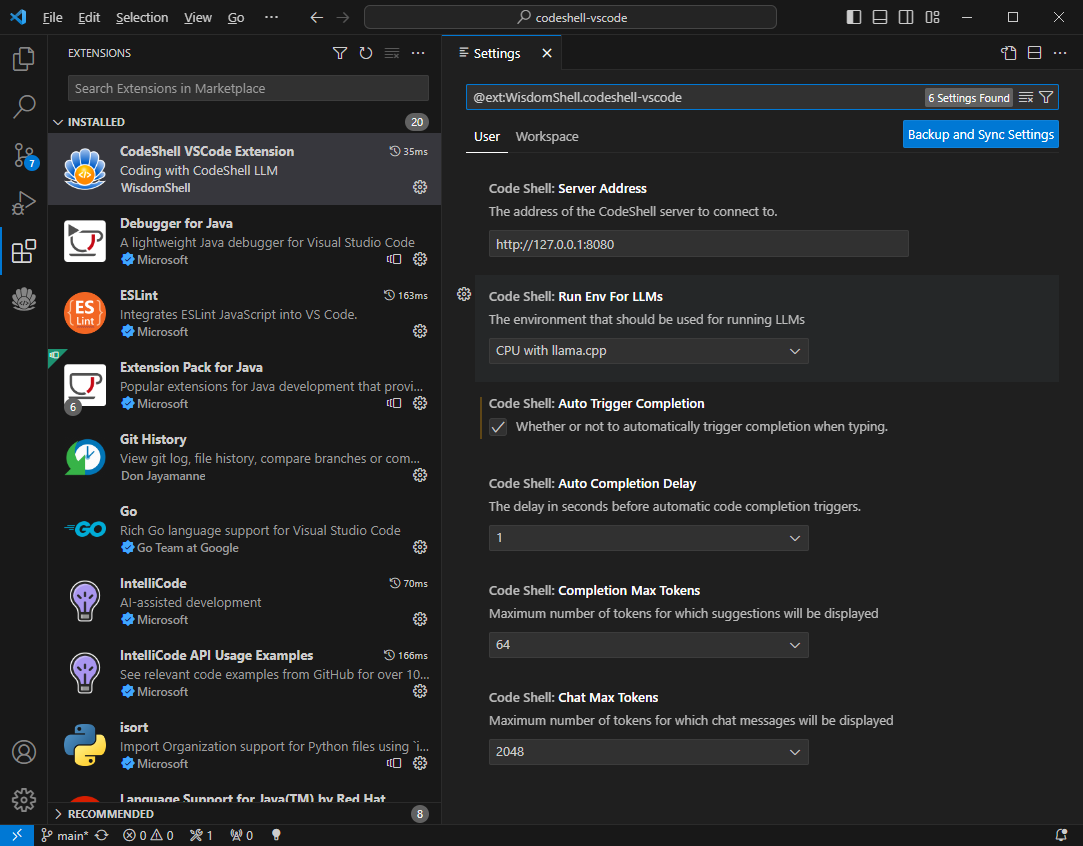
- 设置CodeShell大模型服务地址
- 配置是否自动触发代码补全建议
- 配置自动触发代码补全建议的时间延迟
- 配置补全的最大tokens数量
- 配置问答的最大tokens数量
- 配置模型运行环境
注意:不同的模型运行环境可以在插件中进行配置。对于CodeShell-7B-Chat-int4模型,您可以在Code Shell: Run Env For LLMs选项中选择CPU with llama.cpp选项。而对于CodeShell-7B和CodeShell-7B-Chat模型,应选择GPU with TGI toolkit选项。
功能特性
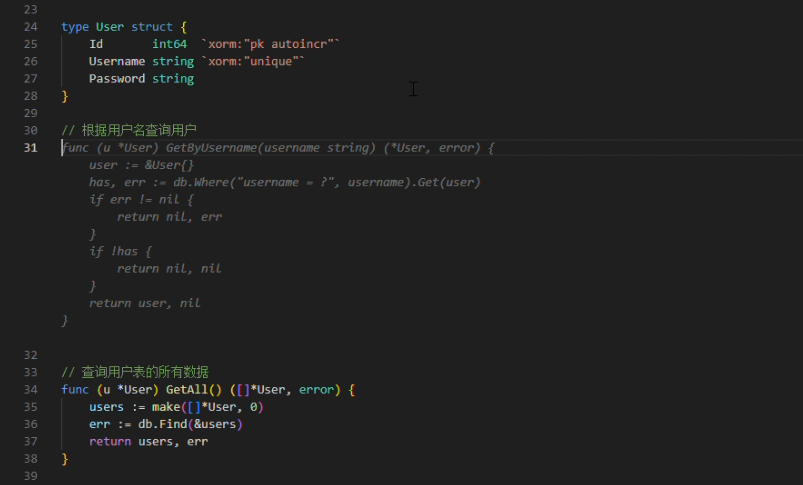
1. 代码补全
- 自动触发代码建议
- 热键触发代码建议
在编码过程中,当停止输入时,代码补全建议可自动触发(在配置选项Auto Completion Delay中可设置为1~3秒),或者您也可以主动触发代码补全建议,使用快捷键Alt+\(对于Windows电脑)或option+\(对于Mac电脑)。
当插件提供代码建议时,建议内容以灰色显示在编辑器光标位置,您可以按下Tab键来接受该建议,或者继续输入以忽略该建议。
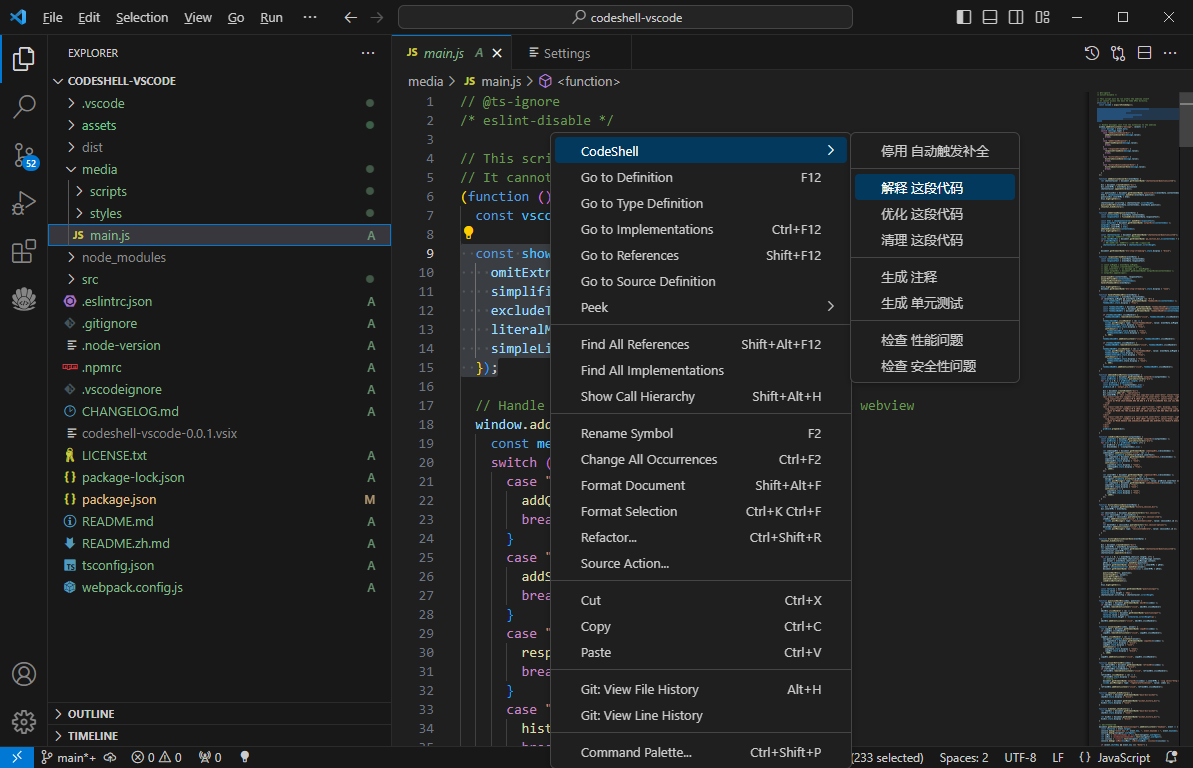
2. 代码辅助
- 对一段代码进行解释/优化/清理
- 为一段代码生成注释/单元测试
- 检查一段代码是否存在性能/安全性问题
在vscode侧边栏中打开插件问答界面,在编辑器中选中一段代码,在鼠标右键CodeShell菜单中选择对应的功能项,插件将在问答界面中给出相应的答复。
3. 智能问答
- 支持多轮对话
- 支持会话历史
- 基于历史会话(做为上文)进行多轮对话
- 可编辑问题,重新提问
- 对任一问题,可重新获取回答
- 在回答过程中,可以打断
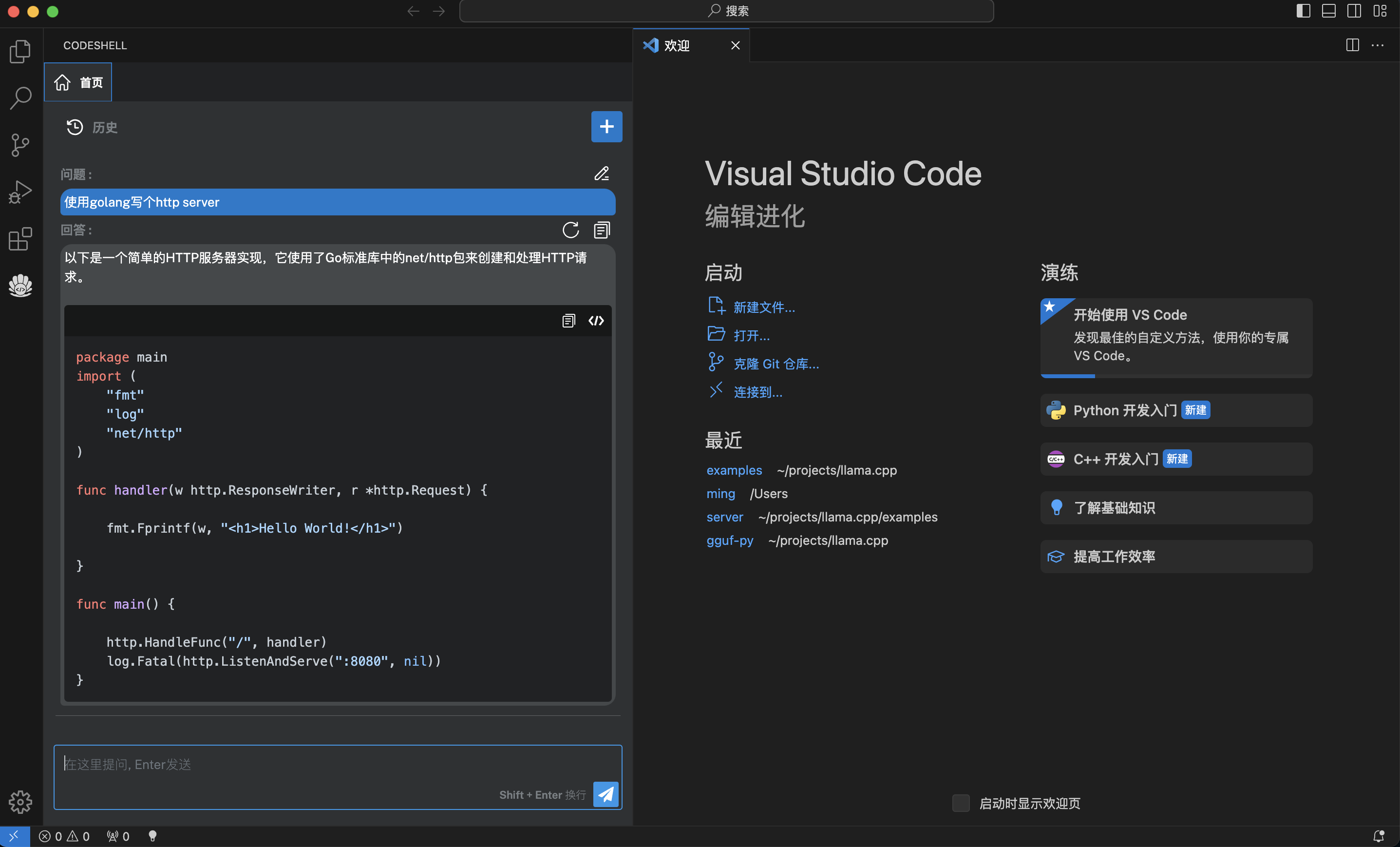
在问答界面的代码块中,可以点击复制按钮复制该代码块,也可点击插入按钮将该代码块内容插入到编辑器光标处。
开源协议
Apache 2.0