| NLP | LLM | Fine-tuning 2024 | Llama 2 QLoRA |
Natural Language Processing (NLP) and Large Language Models (LLM) with Fine-Tuning LLM Llama 2 with QLoRA in 2024

| Overview
In this notebook we're going to Fine-Tuning LLM:

Many LLMs are general purpose models trained on a broad range of data and use cases. This enables them to perform well in a variety of applications, as shown in previous modules. It is not uncommon though to find situations where applying a general purpose model performs unacceptably for specific dataset or use case. This often does not mean that the general purpose model is unusable. Perhaps, with some new data and additional training the model could be improved, or fine-tuned, such that it produces acceptable results for the specific use case.

Fine-tuning uses a pre-trained model as a base and continues to train it with a new, task targeted dataset. Conceptually, fine-tuning leverages that which has already been learned by a model and aims to focus its learnings further for a specific task.
It is important to recognize that fine-tuning is model training. The training process remains a resource intensive, and time consuming effort. Albeit fine-tuning training time is greatly shortened as a result of having started from a pre-trained model.

Here some definitions:
▶️ Llame 2 Model?

Llama 2 is a family of pre-trained and fine-tuned large language models (LLMs) developed by Meta, the parent company of Facebook. These models, ranging from 7B to 70B parameters, are optimized for assistant-like chat use cases and excel in natural language generation tasks, including programming. Llama 2 is an extension of the original Llama model, utilizing the Google transformer architecture with various enhancements.
Llama 2, developed by Meta, is a family of large language models optimized for assistant-like chat and natural language generation tasks, ranging from 7B to 70B parameters.
▶️ Fine-Tuning with LoRA?
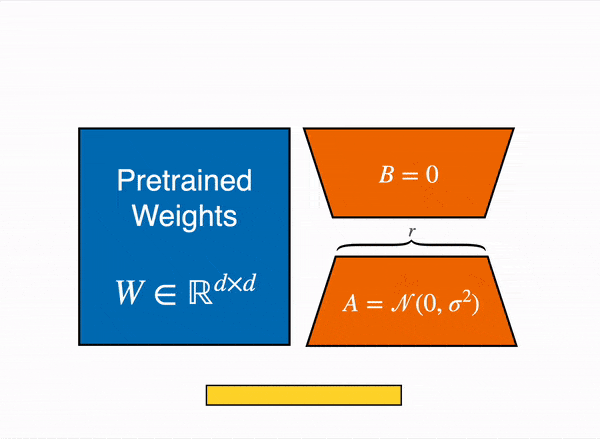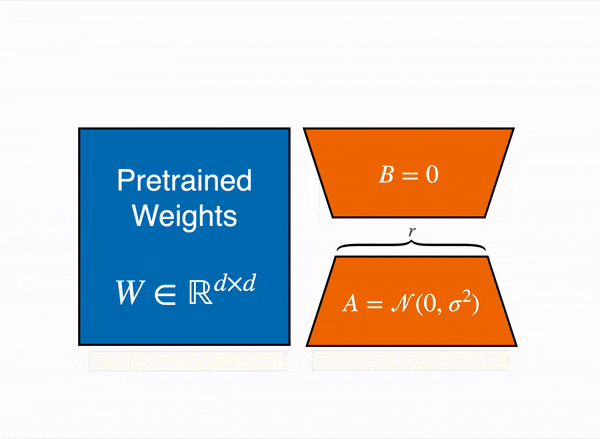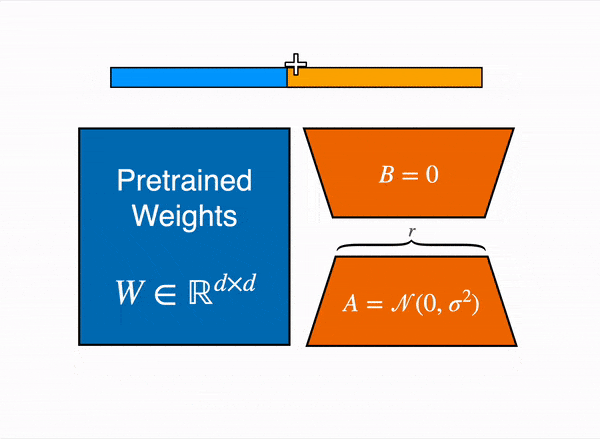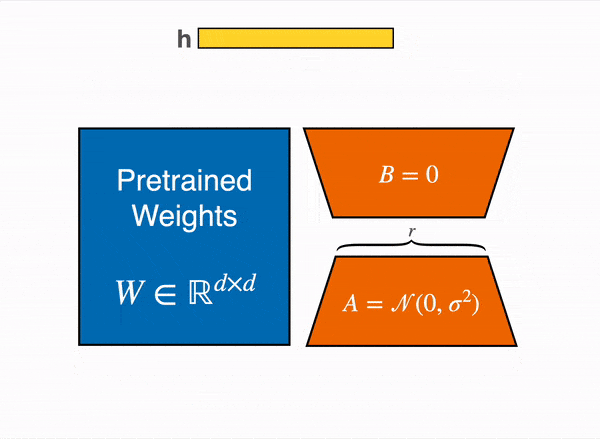
LoRA (Low-Rank Adapters) strategically freezes pre-trained model weights and introduces trainable rank decomposition matrices into the Transformer architecture's layers. This innovative technique significantly reduces the number of trainable parameters, leading to expedited fine-tuning processes and mitigated overfitting.
▶️ RLHF?
RLHF stands for Reinforcement Learning from Human Feedback. - Technique that trains a "reward model" directly from human feedback and uses this model as a reward function to optimize an agent's policy using reinforcement learning through an optimization algorithm like Proximal Policy Optimization (PPO). - This approach allows AI systems to better understand and adapt to complex human preferences, leading to improved performance and safety.

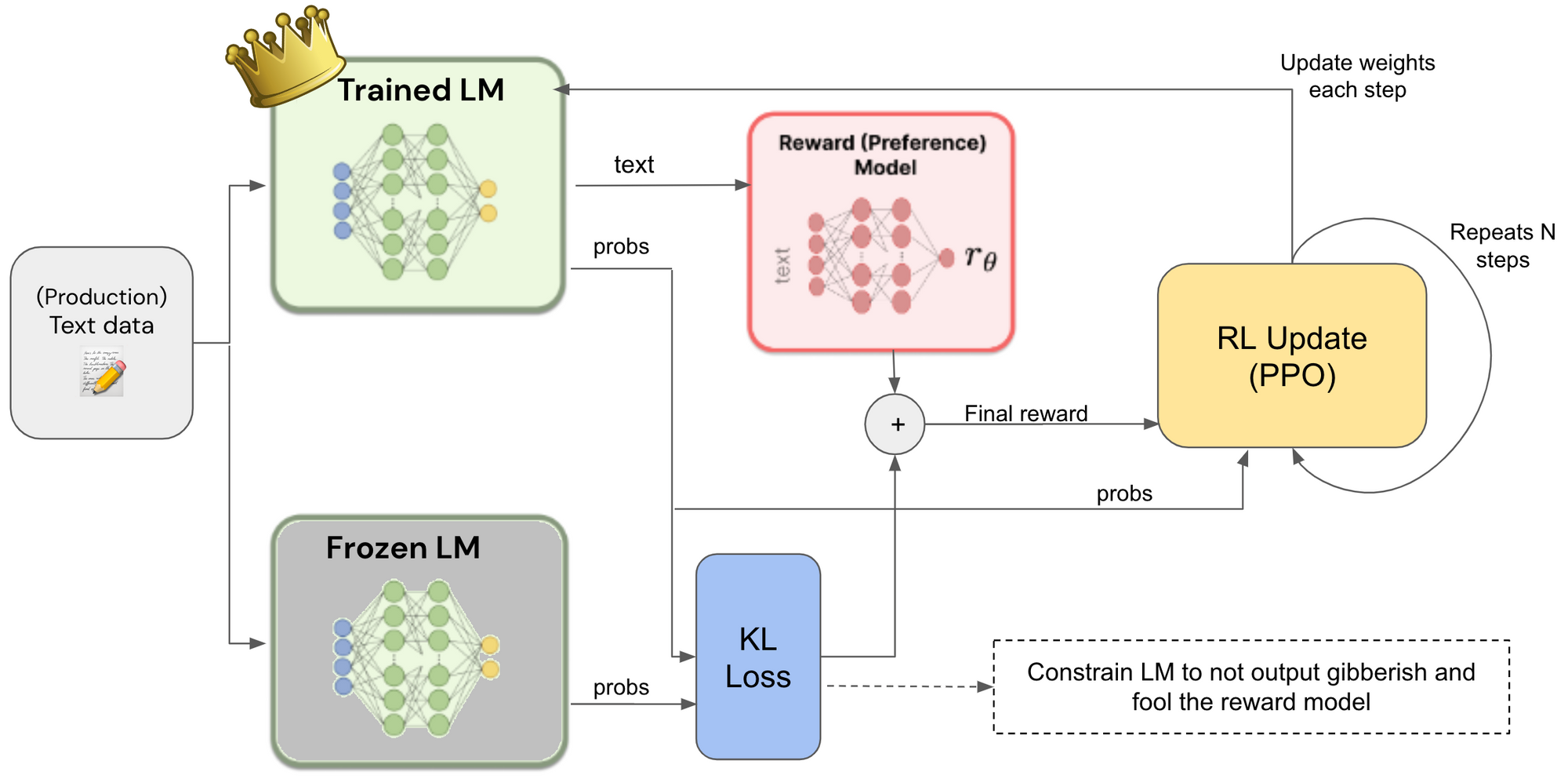
▶️ PPO?
- PPO is a policy gradient method, which means that it directly optimizes the policy function. - Policy gradient methods are typically more efficient than value-based methods, such as Q-learning, but they can be more difficult to train. Proximal Policy Optimization (PPO) is like a smart guide to learning how to do something better. Imagine you're trying to teach a robot how to play a game. PPO helps the robot improve little by little without suddenly changing everything it's learned. This makes him more skillful while remaining safe and effective in his learning. It's a bit like learning to play football by gradually improving without forgetting everything you've already learned.
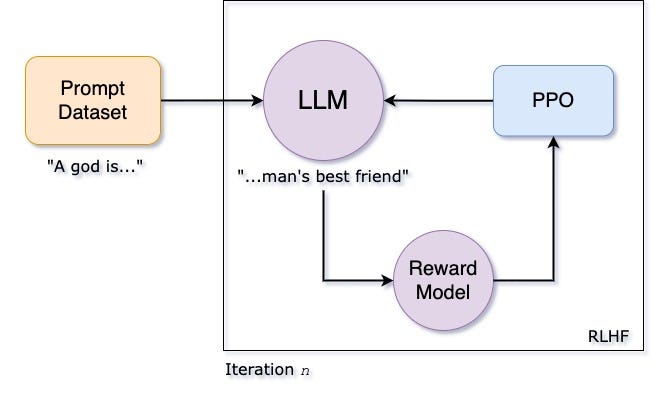
▶️ PERF?
Parameter Efficient Fine-Tuning (PEFT) overcomes the problems of consumer hardware, storage costs by fine tuning only a small subset of model’s parameters significantly reducing the computational expenses while freezing the weights of original pretrained LLM.

▶️ Model Quantization?
Quantization is a technique used to reduce the size of large neural networks, including large language models (LLMs) by modifying the precision of their weights. Instead of using high-precision data types, such as 32-bit floating-point numbers, quantization represents values using lower-precision data types, such as 8-bit integers. This process significantly reduces memory usage and can speed up model execution while maintaining acceptable accuracy. The basic idea behind quantization is quite easy: going from high-precision representation (usually the regular 32-bit floating-point) for weights and activations to a lower precision data type. The most common lower precision data types are: - float16, accumulation data type float16 - bfloat16, accumulation data type float32. It’s similar to the standard 32-bit floating-point format but uses fewer bits, so it takes up less space in computer memory. - int16, accumulation data type int32 - int8, accumulation data type int32▶️ 4-bit NormalFloat (NF4)?
NF4, a 4-bit Normal Float, is tailor-made for AI tasks, specifically optimizing neural network weight quantization. This datatype is ideal for reducing memory usage in models, crucial for deploying on less powerful hardware. NF4 is information-theoretically optimal for normally distributed data, like neural network weights, providing more accurate representation within the 4-bit constraint. Floating-point storage involves sign, exponent, and fraction (mantissa). The binary conversion of numbers varies based on the datatype, affecting precision and range. For example, FP32, commonly used in Deep Learning, can represent numbers between ±1.18×10^-38 and ±3.4×10³⁸. On the other hand, NF4 has a range of [-8, 7]. QLoRA employs brainfloat16 (bfloat16), developed by Google for high-throughput floating-point operations in machine learning and computational tasks.
▶️ Bitsandbytes?
Make the process of model quantization more accessible. Bitsandbytes is a lightweight wrapper around CUDA custom functions, in particular 8-bit optimizers, matrix multiplication (LLM.int8()), and quantization functions. ```BitsAndBytesConfig```
```BitsAndBytesConfig```
▶️ 4-bit NormalFloat Quantization?
The aim of 4-bit NormalFloat Quantization is to reduce the memory usage of the model parameters by using lower precision types than full (float32) or half (bfloat16) precision. Meaning 4-bit quantization compresses models that have billions of parameters and makes them require less memory. ```python load_in_4bit=True ```▶️ Bfloat16 vs Float16/32?
**Understanding Float16/32 and Bfloat16:** - **Float16 (Half-Precision):** This format uses 16 bits to represent a floating-point number, with 1 bit for the sign, 5 bits for the exponent, and 10 bits for the mantissa. It is widely used for its reduced memory footprint but can be sensitive to numerical issues due to its limited dynamic range. - **Float32 (Single-Precision):** With 32 bits, float32 includes 1 bit for the sign, 8 bits for the exponent, and 23 bits for the mantissa. It provides a larger dynamic range and higher precision than float16 but consumes more memory. - **Bfloat16:** Specifically designed for deep learning, bfloat16 uses 16 bits, allocating 1 bit for the sign, 8 bits for the exponent, and 7 bits for the mantissa. Its dynamic range is closer to float32, making it suitable for maintaining precision while reducing memory usage during training. **Bfloat16:**
- 16-bit floating point format tailored for deep learning applications.
- Comprises one sign bit, eight exponent bits, and seven mantissa bits.
- Demonstrates a larger dynamic range (number of exponent bits) than float16, aligning closely with float32.
- Efficiently handles exponent changes, potentially leading to memory savings.
- Offers improved training efficiency, reduced memory usage, and space savings.
- Less susceptible to underflows, overflows, or numerical instability during training.
**Float16/32:**
- Float16: IEEE half-precision, Float32: IEEE single-precision.
- Exhibits a smaller dynamic range compared to bfloat16.
- May encounter numerical issues such as overflows or underflows during training.
- Loss scaling might be necessary in mixed precision settings to mitigate side effects.
- Float32 generally requires more memory for storage compared to bfloat16.
- Training behavior may be less stable, particularly with pure float32 dtype.
**GPU Dependency:**
- The effectiveness of bfloat16 and float16/32 is contingent on the GPU architecture.
- Some GPUs offer native support for bfloat16, optimizing its performance benefits.
- It is crucial to check GPU specifications and compatibility before choosing between bfloat16 and float16/32.
- Users may need to tailor configurations based on GPU capabilities for optimal results.
**Conclusion:**
While bfloat16 presents advantages in training efficiency and memory usage, its performance is influenced by GPU architecture. Understanding the characteristics of float16, float32, and bfloat16 is crucial for selecting the optimal format based on both task requirements and GPU capabilities.
**How to Enable Bfloat16:**
To enable bfloat16 in mixed precision mode, specific changes in the configuration file are necessary, including setting ```model.use_bfloat16``` to True, ```optimizer.loss_scaling_factor``` to 1.0, and model.mixed_precision to True. Notably, bfloat16 eliminates the need for loss scaling, which was initially introduced for mixed precision mode with float16 settings.
**Bfloat16:**
- 16-bit floating point format tailored for deep learning applications.
- Comprises one sign bit, eight exponent bits, and seven mantissa bits.
- Demonstrates a larger dynamic range (number of exponent bits) than float16, aligning closely with float32.
- Efficiently handles exponent changes, potentially leading to memory savings.
- Offers improved training efficiency, reduced memory usage, and space savings.
- Less susceptible to underflows, overflows, or numerical instability during training.
**Float16/32:**
- Float16: IEEE half-precision, Float32: IEEE single-precision.
- Exhibits a smaller dynamic range compared to bfloat16.
- May encounter numerical issues such as overflows or underflows during training.
- Loss scaling might be necessary in mixed precision settings to mitigate side effects.
- Float32 generally requires more memory for storage compared to bfloat16.
- Training behavior may be less stable, particularly with pure float32 dtype.
**GPU Dependency:**
- The effectiveness of bfloat16 and float16/32 is contingent on the GPU architecture.
- Some GPUs offer native support for bfloat16, optimizing its performance benefits.
- It is crucial to check GPU specifications and compatibility before choosing between bfloat16 and float16/32.
- Users may need to tailor configurations based on GPU capabilities for optimal results.
**Conclusion:**
While bfloat16 presents advantages in training efficiency and memory usage, its performance is influenced by GPU architecture. Understanding the characteristics of float16, float32, and bfloat16 is crucial for selecting the optimal format based on both task requirements and GPU capabilities.
**How to Enable Bfloat16:**
To enable bfloat16 in mixed precision mode, specific changes in the configuration file are necessary, including setting ```model.use_bfloat16``` to True, ```optimizer.loss_scaling_factor``` to 1.0, and model.mixed_precision to True. Notably, bfloat16 eliminates the need for loss scaling, which was initially introduced for mixed precision mode with float16 settings.
▶️ fp16 vs bf16 vs tf32?
Mixed precision training optimizes computational efficiency by using lower-precision numerical formats for specific variables. Traditionally, models use 32-bit floating point precision (fp32), but not all variables require this high precision. Mixed precision involves using 16-bit floating point (fp16) or other data types like brainfloat16 (bf16) and tf32 (CUDA internal data type) for certain computations. - **fp16 (float16):** - Advantages: Faster computations, especially in saving activations. - Gradients are computed in half precision but converted back to full precision for optimization. - Memory usage may increase, as both 16-bit and 32-bit precision coexist on the GPU. - Enables mixed precision training, improving efficiency. - Enable with `fp16=True` in the training arguments. - **bf16 (brainfloat16):** - Advantages: Wider dynamic range compared to fp16, suitable for mixed precision training. - Available on Ampere or newer hardware. - Enables mixed precision training and evaluation (Use with training and evaluation), - Lower precision but larger dynamic range than fp16. - Enable with `bf16=True` in the training arguments. - **tf32 (CUDA internal data type):** - Advantages: Up to 3x throughput improvement in training and/or inference. - Exclusive to Ampere hardware. - Similar numerical range as fp32 but with reduced precision (10 bits). - Allows using normal fp32 training/inference code with enhanced throughput. - Enable by allowing tf32 support in your code. ```python import torch torch.backends.cuda.matmul.allow_tf32 = True torch.backends.cudnn.allow_tf32 = True ``` - Enable this mode in the 🤗 Trainer with `tf32=True` in the training arguments. - Requires torch version >= 1.7 to use tf32 data types. These approaches provide advantages in terms of computational speed and efficiency, making them valuable for mixed precision training on specific hardware architectures.▶️ QLoRA?
QLoRA (Quantized Low-Rank Adaptation) is an extension of LoRA (Low-Rank Adapters) that uses quantization to improve parameter efficiency during fine-tuning. QLoRA is more memory efficient than LoRA because it loads the pretrained model to GPU memory as 4-bit weights, compared to 8-bits in LoRA. This technique to reduce the memory footprint of large language models during finetuning, without sacrificing performance by using quantization. It's peft method.
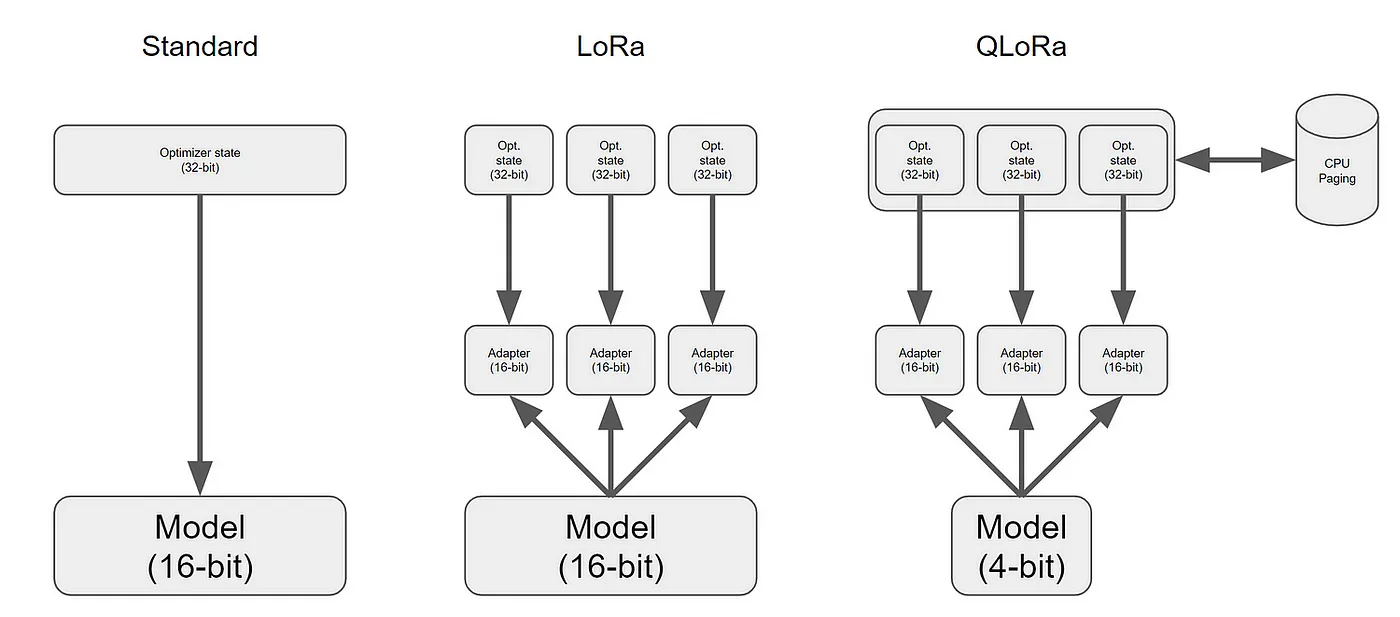
▶️ What are we training with QLoRA?
QLoRA fine-tunes language models by quantizing pre-trained weights to 4-bit representations, keeping them fixed. It trains a small number of low-rank matrices during fine-tuning, efficiently updating knowledge without extensive resource usage. This approach enhances memory efficiency, allowing effective fine-tuning by adjusting a subset of the model's existing knowledge for specific tasks. - An adapter weights trained (**trainer.save_model()**). - After your merge the adapter weights to the base LLM.
▶️ What is Supervised fine-tuning?
Supervised fine-tuning (SFT) is a key step in reinforcement learning from human feedback (RLHF). The TRL library from HuggingFace provides an easy-to-use API to create SFT models and train them on your dataset with just a few lines of code. It comes with tools to train language models using reinforcement learning, starting with supervised fine-tuning, then reward modeling, and finally proximal policy optimization (PPO). We will provide SFT Trainer the model, dataset, Lora configuration, tokenizer, and training parameters. ```SFTTrainer```▶️ Trainer vs SFTTrainer
 **Trainer:**
- **General-purpose training:** Designed for training models from scratch on supervised learning tasks like text classification, question answering, and summarization.
- **Highly customizable:** Offers a wide range of configuration options for fine-tuning hyperparameters, optimizers, schedulers, logging, and evaluation metrics.
- **Handles complex training workflows:** Supports features like gradient accumulation, early stopping, checkpointing, and distributed training.
- **Requires more data:** Typically needs larger datasets for effective training from scratch.
**SFTTrainer:**
- **Supervised Fine-tuning (SFT):** Optimized for fine-tuning pre-trained models with smaller datasets on supervised learning tasks.
- **Simpler interface:** Provides a streamlined workflow with fewer configuration options, making it easier to get started.
- **Efficient memory usage:** Uses techniques like parameter-efficient (PEFT) and packing optimizations to reduce memory consumption during training.
- **Faster training:** Achieves comparable or better accuracy with smaller datasets and shorter training times than Trainer.
**Choosing between Trainer and SFTTrainer:**
- **Use Trainer:** If you have a large dataset and need extensive customization for your training loop or complex training workflows.
- **Use SFTTrainer:** If you have a pre-trained model and a relatively smaller dataset, and want a simpler and faster fine-tuning experience with efficient memory usage.
**Trainer:**
- **General-purpose training:** Designed for training models from scratch on supervised learning tasks like text classification, question answering, and summarization.
- **Highly customizable:** Offers a wide range of configuration options for fine-tuning hyperparameters, optimizers, schedulers, logging, and evaluation metrics.
- **Handles complex training workflows:** Supports features like gradient accumulation, early stopping, checkpointing, and distributed training.
- **Requires more data:** Typically needs larger datasets for effective training from scratch.
**SFTTrainer:**
- **Supervised Fine-tuning (SFT):** Optimized for fine-tuning pre-trained models with smaller datasets on supervised learning tasks.
- **Simpler interface:** Provides a streamlined workflow with fewer configuration options, making it easier to get started.
- **Efficient memory usage:** Uses techniques like parameter-efficient (PEFT) and packing optimizations to reduce memory consumption during training.
- **Faster training:** Achieves comparable or better accuracy with smaller datasets and shorter training times than Trainer.
**Choosing between Trainer and SFTTrainer:**
- **Use Trainer:** If you have a large dataset and need extensive customization for your training loop or complex training workflows.
- **Use SFTTrainer:** If you have a pre-trained model and a relatively smaller dataset, and want a simpler and faster fine-tuning experience with efficient memory usage.
▶️ Flash Attention?
Flash Attention is a an method that reorders the attention computation and leverages classical techniques (tiling, recomputation) to significantly speed it up and reduce memory usage from quadratic to linear in sequence length. Accelerates training up to 3x. Learn more at FlashAttention. Resume: It focuses on the part of the model called “attention,” which helps the model to focus on the most important parts of the data, just like when you pay attention to the most important parts of a lecture. Flash Attention 2 makes this process faster and uses less memory

▶️ Flash Attention Vs Normal with pretraining_tp?
**Observations:** 1. **Training Loss**: - The training losses across all cases are very close to each other. There is a very minor decrease in training loss when using a ```pretraining_tp``` of 1 vs. 2 but the difference is negligible. - The attention type (Flash vs. Normal) does not seem to have a noticeable impact on the final training loss. 2. **Training Time**: - **Using Flash Attention significantly reduces training time, nearly by half as compared to using Normal Attention.** - The ```pretraining_tp``` value does not seem to significantly impact the training time. 3. **Inference Time**: - Flash Attention with ``pretraining_tp`` of 2 has the fastest inference time. - Interestingly, Normal Attention has similar inference times for both ``pretraining_tp`` values, and they're both comparable or slightly faster than Flash Attention with ``pretraining_tp`` of 1.

**Conclusion:** - Flash Attention is significantly faster in training compared to Normal Attention, which is expected based on the stated advantages of Flash Attention. - The pretraining_tp values, either 1 or 2, do not drastically impact the model's performance or training/inference times in this experiment. However, using pretraining_tp of 2 slightly improves inference time when using Flash Attention. - The model’s performance, in terms of loss, is mostly consistent across all cases. Hence, other considerations like training time, inference time, and computational resources could be more important when deciding on the configurations to use.
▶️ Add Special Tokens for Chat Format/chatml?
Adding special tokens to a language model is crucial for training chat models. These tokens are added between the different roles in a conversation, such as the user, assistant, and system and help the model recognize the structure and flow of a conversation. This setup is essential for enabling the model to generate coherent and contextually appropriate responses in a chat environment. The setup_chat_format() function in trl easily sets up a model and tokenizer for conversational AI tasks - Adds special tokens to the tokenizer, e.g. <|im_start|> and <|im_end|>, to indicate the start and end of a conversation. - Resizes the model’s embedding layer to accommodate the new tokens. - Sets the chat_template of the tokenizer, which is used to format the input data into a chat-like format. The default is chatml from OpenAI.
Define our use case
In the process of fine-tuning Language Models (LLMs), it is crucial to have a clear understanding of your specific use case and the task you aim to address. This knowledge will guide you in selecting the most suitable pre-existing model or assist you in curating a dataset for the fine-tuning process. If your use case hasn't been defined yet, it is advisable to revisit your initial considerations. It's important to note that fine-tuning is not universally necessary for all scenarios. Prior to embarking on the fine-tuning journey, it is highly recommended to explore and assess already fine-tuned models or those available through APIs.
Author Note:
While the model demonstrates remarkable performance across various tasks in datasets, notable alterations in its generation capabilities may not be readily apparent.
👉🏿 So this is an example of how Fine tuning in 2024
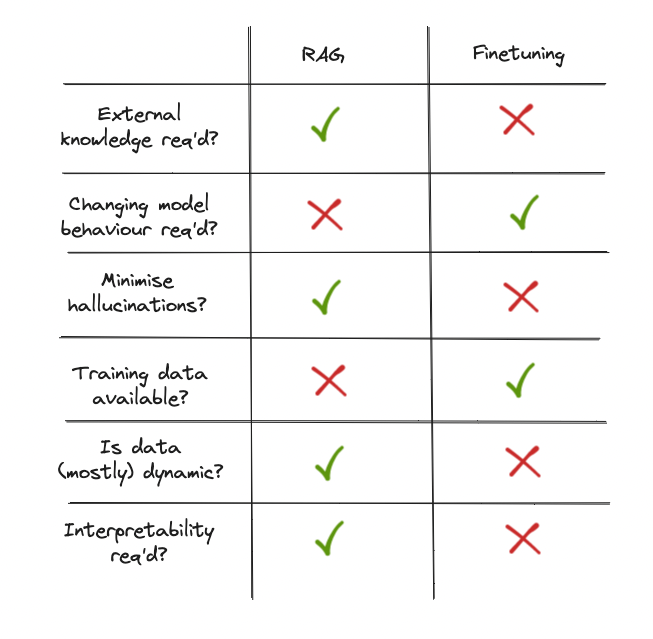
This is why it is preferable to use a RAG to reduce hallucination about the task already present in the model in this case.
RAG vs Finetuning
As the enthusiasm for Large Language Models (LLMs) continues to grow, numerous developers and organizations are actively engaged in creating applications that leverage their capabilities. Yet, when pre-trained LLMs fail to meet desired expectations, the pivotal question arises: How can we enhance the performance of the LLM application? This leads us to a critical juncture where we must deliberate on whether to employ Retrieval-Augmented Generation (RAG) or pursue model fine-tuning to optimize the outcomes.

Learning Objectives
By the end of this notebook, you will gain expertise in the following areas:
- Learn how to effectively prepare datasets for training.
- Few shots learning
- Understand the process of fine-tuning the Llama 2 on QLoRA with SFTTrainer in 2024.
Ressources
-
Optimizing LLMs: A Step-by-Step Guide to Fine-Tuning with PEFT and Qlora
-
How to Fine-Tune an LLM - Part 2: Instruction Tuning Llama 2
-
Fine-Tuning Llama 2 LLM on Google Colab: A Step-by-Step Guide
-
Mastering Llama 2: A Comprehensive Guide to Fine-Tuning in Google Colab
-
OpenAI introduced Chat Markup Language (ChatML) based input to non-chat modes
-
The Science of Control: How Temperature, Top-p, and Top-k Shape Large Language Models