Project Title: Heart-a-tracker

Developing
Requirements
Python >= 3.7
Node.js >= 10
Yarn >= 1.15
UI built with create-react-app.
UI dependencies
Express+GraphQL API Dependencies
Installing
git clone git@github.com:a-laughlin/3308proj.git 3308proj- run
. setup.shuntilNext Step!stops appearing. (Installs all dependencies.)
Pulling from Master to your personal branch
git checkout <your branchname>
yarn pullSee Code Contribution Flow for more details on our flow.
Pushing from your personal branch to your remote branch (to PR master)
yarn push
For development speed and process consistency, this runs all tests locally, pushes to github, and triggers a travis CI build. If all pass, it then opens a new browser tab with PR to master prepopulated.
See Code Contribution Flow for more details on our flow.
Running the Web + API in dev mode
yarn dev
Starts the API and UI
On change, reloads UI/API and re-runs affected UI tests
Testing
Machine Learning: "yarn test-ml"
All integration & unit tests yarn test
Update Jest snapshots "yarn update-test-snapshots"
see TESTING.md for user acceptance tests
Tech Stack Overview (at V0.2, aka project end)
- Web Server*: Express routing data requests to GraphQL and passing through static file (html,js,css) requests to the file system.
- UI: Single static html page. Data rendered by React using Apollo Client to request and cache it from our GraphQL API.
- API: Apollo GraphQL Server to route data requests to the appropriate resources (e.g., file system, database, python machine-learning code).
- ML: Pytorch RNN, LSTM, and ODENet for heart rate predictions.
- Database: Sqlite.
* For performance, we'd normally use something like nginx or apache to route static file requests, but using express for everything is simpler, and simplicity trumps performance in our context.
Project Directory Structure
(tests colocated with files, suffixed with _test or .test)
.
├── src
│ ├── api see src/api/README.md
│ │ ├── __snapshots__ jest testing snapshots
│ │ ├── datasource-apis
│ │ │ ├── filesystem.js
│ │ │ ├── ml.js
│ │ │ └── sqlite.js
│ │ ├── api.js
│ │ ├── graphql-server.js
│ │ ├── graphql-server.test.js
│ │ ├── package.json api project dependencies/scripts
│ ├── ml pytorch machine learning
│ │ ├── README.md machine learning documentation
│ │ ├── Models.py
│ │ ├── ml_utils.py
│ │ ├── ml_utils_test.py
│ │ ├── predict.py
│ │ └── train.py
│ ├── mobile our original react-native mobile ui (now unused)
│ └── web react web ui
│ ├── public static files
│ │ ├── index.html main index.html
│ │ └── manifest.json specify project behavior if "installed" as PWA
│ ├── src
│ │ ├── sample_data sample data for testing (in web/ to work with react build)
│ │ │ ├── README.md
│ │ │ ├── ml_input_foo.json
│ │ │ ├── ml_input_sine.json
│ │ │ ├── ml_model_foo.pt stored prediction model
│ │ │ └── ml_output_foo.json
│ │ ├── App.js main web code
│ │ ├── App.test.js integration tests (disabled until react update fixes warnings)
│ │ ├── graphql-client.js apollo graphql client
│ │ ├── hooks.js react "hooks" for components to use
│ │ ├── hooks.test.js unit+integration tests
│ │ ├── index.css global tag styles + reset. (other styles inline)
│ │ ├── index.js loads App.js, includes some unused PWA infrastructure
│ │ ├── serviceWorker.js for use if we go the PWA route
│ │ ├── style-string-to-obj.js inline style generator
│ │ ├── style-string-to-obj.test.js unit tests
│ │ ├── utils.js utlities (mostly FP)
│ │ └── utils.test.js unit tests
│ ├── Home_page_screenshot_V00.png mockup for v0.0
│ ├── Error_screenshot_V01.png mockup for v0.1
│ ├── Loading_screenshot_V01.png mockup for v0.1
│ ├── README.md web docs
│ ├── jest.config.js configure jest testing
│ └── package.json react project config
├── Pipfile pipenv setup
├── README.md main project documentation
├── TESTING.md user acceptance test cases
├── build.py for building/testing/cleaning tasks
└── setup.sh project setup/installation for different platformsTeam member’s names
- Adam Laughlin
- Ben Wilson
- Brian Solar
- Chris Powell
Vision statement: what would you tell potential customers?
Predict future heart behavior.
Motivation: why are you working on this project?
This project combines the interests of our group into one cohesive idea.
Risks and Mitigation Strategies:
Risk: No prior experience working with these team members impacting our success.
Mitigation Strategy: Start with some ice breakers, share experiences from previous classes, find a shared goal we can all get behind
Risk: Schedules interfering
Mitigation Strategy: Find a backup time to meet in case we can't meet at the normal scheduled time. We can also meet without someone if they can meet with a group member before hand. If we can project manage well enough we can have our meeting without someone
Risk: Not learning the necessary tools/skills in time: Pytorch, etc.
Mitigation Strategy: Fall back on simpler APIs, such as Keras/sklearn Use tools that are in one’s experience
Risk: Not having the necessary tools/frameworks available: Backend not supporting Pytorch
Mitigation Strategy: Fall back on simpler APIs, or ones that are supported Adapt the problem to one that can be accomplished with the available tools
Risk: Not having the necessary data Heart rate data (clean) over a period of time
Mitigation Strategy: Synthetically generate our own data Use publicly available data (such as on Kaggle or university research websites)
Risk: One member not completing a task required for the group to move forward
Mitigation Strategy: Have each story assigned to two members (one primary, one secondary) to encourage accountability Have early deadlines for completion, allowing an assessment on progression and follow-up action to push for a timely completion
Risk: Lack of access to test devices Building for iOS or Android with only some team members having access
Mitigation Strategy: Discuss what device we all have access to, possibly loading it onto our roommate’s phone to be able to complete stories on our own Look for software that acts like a mobile OS as an environment
Risk: Spending too much time at any point in the development Creating too many stories or spending too many resources in a section that creates a limited amount of time for the other areas
Mitigation Strategy: Estimate the number of days and hours we have in total and attempt to assign portions of development to stages of the process, i.e. 10% to UI, 10% to data pipeline, 50% to neural network algorithm and improvements to it, etc… Attempt to project manage on a larger scale before breaking it down into stories and sprints, understanding when we need to take the actions outlined above because we no longer have time to spend on that part of the project.
Risk: Different data collecting devices and data formats Apple Watch, Garmin, FitBit, Jawbone, etc, with different data types
Mitigation Strategy: This could be luxury if we aren’t able to find time for it. Try to find an intermediary, such as Apple’s Health app, who already transforms and stores the data
Project Management Process decided: (e.g., scrum, kanban: with specifics!)
Yes, we're doing scrum with our weekly meetings. We're meeting weekly. We're beginning to plan out time based sprints.
- Issue ownership: determining who is going to take ownership of issues based on skill set, time commitment, availability etc.
- Issue Selection
- Issue Flow
- Done defined (definition TBD)
- Project tracker supports PM process stages
- Meetings 6.1 Sprint planning meetings 6.1.1 Issue ownership 6.1.2 Issue selection 6.2 Retrospective meetings (done at the beginning of Sprint planning meetings) 6.3 Stand up meetings
Project Management Tooling
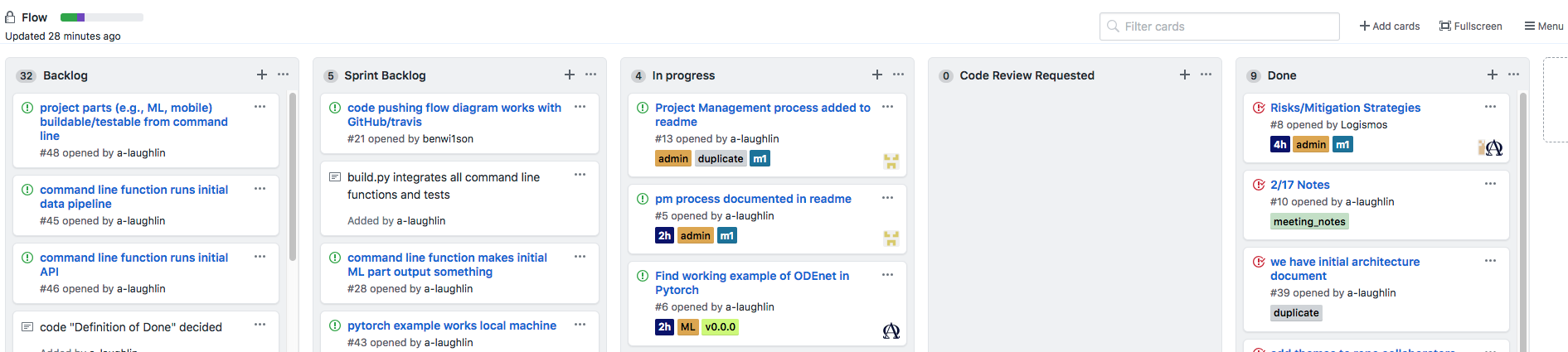
Backlog
- Contains all non-started stories that aren't in the current sprint.
- Reviewed during sprint planning. Stories chosen for sprint moved to Sprint backlog.
Sprint Backlog
- Contains all non-started stories that aren't in the current sprint.
- Where we get stories to work on during a sprint
- All stories in this column should have at least a version (e.g. v0.0.0) or class milestone (e.g., m1), an hour estimate (e.g., 2h), user or dev value, (e.g., u1, d1) and project part (e.g., mobile, devops).
- Contains "pre-assigned" stories - those that a specific person wants to work on. And non-assigned stories, those up for anyone. We can re-assign any story to ourselves if it's non-assigned or we talk to the person it's assigned to, and they agree.
In Progress
- What we're currently working on.
- All stories must have an assignee.
- One story in progress per person.
Review Requested
- Enables requesting a review on a tentatively finished ticket, for learning purposes.
- Working async, it may be a while before getting a review. Helps keeps "In Progress" to one ticket per person.
- In addition to moving it to this column, ask a particular person to review your code via slack.
Done
- Contains stories finished for the sprint.
- Stories are "closed" github issues.
- Github issues that are "closed" will automatically move to this column.
- All code stories meet the Definition of Done
- All code stories are merged into master branch.
Story Labels
Estimates 2h, 4h, 8h, 16h Instead of using story points, we're going with # of hours estimated to eliminate unnecessary indirection. at 16h, it's likely we'll break it down into smaller stories. We may add a shorter one for small admin tasks. Class Milestones m1, m2, ... ,m7 Version Milestones v0.0.0, v0.0.1, v0.0.2, v0.0.... whatever we get to by the course end. Project Parts mobile, ML, apiin, apiout, devops, admin, dpipe (data pipeline) User Value Estimates u1 (nice to have), u2 (important), u3 (critical) Dev Value Estimates d1 (nice to have), d2 (important), d3 (critical) Issue States bug, duplicate, regres (Regression - was working, now broke) Misc meeting_notes (taken during meetings, like sprint retrospective/planning)
Definition of Done (for code stories)
- Includes
- Code written
- Explanation in appropriate readme (e.g., src/mobile/readme.md) if necessary
- CI tests passing (once implemented)
Dev Process (i.e., Git Flow, vs Trunk-Based Development)
Code Contribution Flow
Mostly trunk-based for speed. Active development happens in non-changing individual branches to:
- promote small+frequent commits
- enable optional code reviews via Github's PR UI
- revert fast

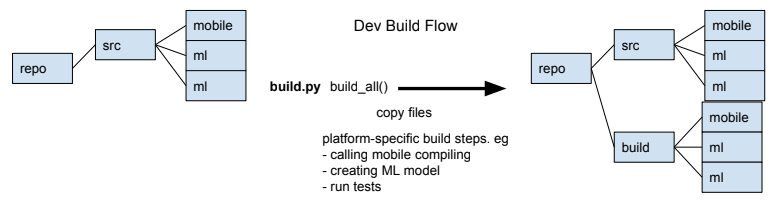
Build Process Flow
Dev Tooling (for our own reference, and milestone 5)
Project Management Stack
- kanban via GitHub Project Tab, for simplicity and keeping all project info in one place
Version Control
- Git
- GitHub
Mobile Stack
- TBD
ML Stack
- Python
- PyTorch
Communication Tools
- Github Issues
- Github Issue Comments
- Slack
- Slack Travis CI Notifications
- Slack Github Notifications (minus issues, since they were spammy)
CI Tooling
- Travis CI
Design
- Primary Color: #42A5F5
- Secondary Color: #84FFFF
- Surface Color: #FFFFFF
- Background Color: #FFFFFF
- Error Color: #B71C1C
- Text: White on error, black on everything else
Mockups
V0.0

V0.1
Main mock up still applicable, adding loading and error states:


V0.2
TBD