 aimanamri
commented
1 month ago
aimanamri
commented
1 month ago Hi @pchidr2 , thanks for commenting!
Disclaimer : I am following this tutorial for the data modelling as I am still learning too😅. He was using AWS but I am trying to use Azure. still in-progress~~
The reason PKs which aren't in the dataset is for data normalization. Removing the duplicated data in fact table (here : fact.trip table) a.k.a reduce columns in main table and then put them into few dimension tables which then can be joined later when doing analysis. Also, I can describe what payment_type = 1 means without repeating same data.
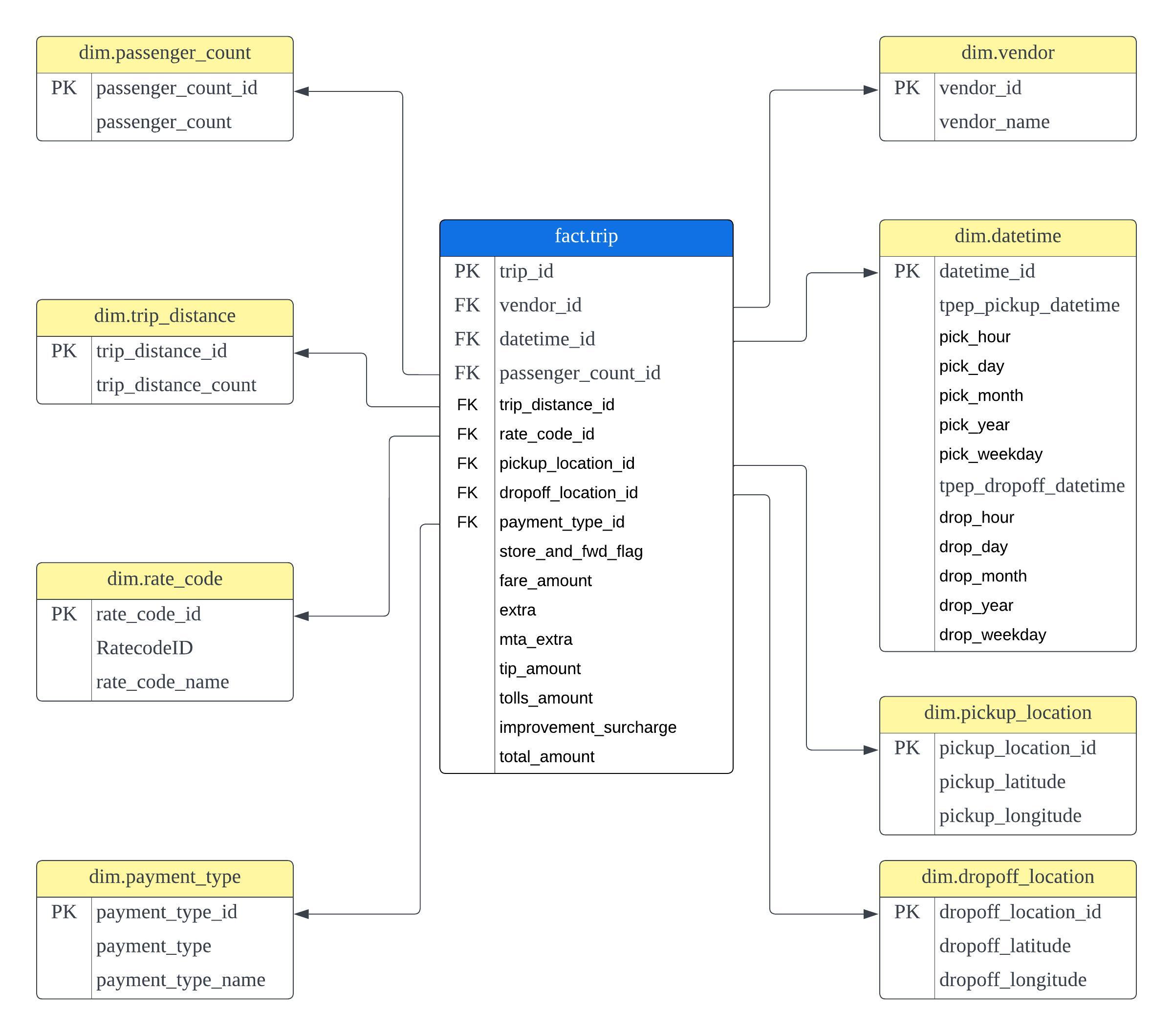
As example dim.rate_code table, rate_code_id is actually auto-generated index (1~ n th rows). So, I was planning to remove the duplicates in RateCodeID column which will keep only unique values from all rows and then, reset the table index ( rate_code_id) using Python. Well, actually we can just rename RateCodeID to rate_code_id and make it as PK, so less columns are stored.
For dim.payment_type table, payment_type_id is actually auto-generated index (1~ n th rows). So, same as above, remove the duplicates in payment_type column which will keep only unique values from all rows and then, reset the table index ( payment_type_id) using Python.
For dim.passenger_count table, to be honest, this table can should be eliminated because this data does not really require primary keys. (cost more storage!)
For dim.datetime table, the tutorial used PK like from number 1 until n th rows. But after few readings, there is some practice that use date as the PK. ex: 8th June 2024, the PK can be used is 20240608.
Conclusion, this data model still need improvement and surely there are still lot of better methods. Sorry don't know if I really answered your question.
I saw your datatmodel. I should say that you have created a really good datamodel. I have a quick question for you. I noticed that you have created some PK which aren't there in the dataset. For example - Passengercountid, Paymenttypeid etc but you have included in the data model. Can you please explain me?