TTS QA - Quality Assessment Text to Speech Data Annotation Tool
Overview

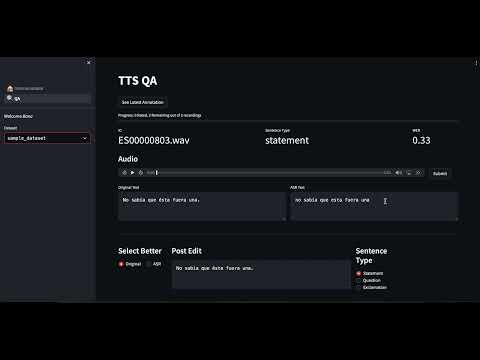
For a quick overview of the project, please watch the following video:
Step 1: Prerequisites
- Python 3.6 or higher installed on your system along with packages in requirements.txt. You may install them using pip install -r requirements.txt while the environment is active.
- docker-compose
- aiXplain SDK installed and configured as described in the aiXplain SDK documentation (More details below)
- AWS S3 credentials (access key and secret access key) to upload and download files from S3
Details:
Prior to running the code, you will need to set up the following services to set up the repo:
-
aiXplain: For transcribing audio, ASR models are accessed from the aiXplain platform. This repo makes use of the aixplain platform and its models as an essential element. aiXplain provides easy to use no-code AI/ ML solutions to integrate into applications such as this. They can be easily integrated into applications with a single API call.
To use the aiXplain tools, you firstly need to create an account on the aiXplain platform. Then, you can choose from the plethora of models to use directly or create pipelines that use those models in a cascade. Trying or deploying those models requires credits, which may be easily purchased from the platform.
After setting up, you need to generate a private TEAM_API_KEY from the integrations settings. Please store that safely as it will be used by the aiXplain SDK to securely access your account and models/ pipelines.
Following are some short youtube videos that explain the aiXplain platform and how to use it:
- aiXplain Teaser: Overview
- aiXplain Tools: Tools overview such as models, piplines, benchmark and finetune.
- aiXplain Discover: Find and try over 38,000 models hosted on the platform
- aiXplain Credits: How to purchase and use credits
-
AWS S3 bucket: This is used to temporarily store data for being processed by the pipeline.
After both are set up, you should enter the relevant information and credentials in the environment files:
-
Configure the environment file:
vars.env. -
Open the
vars.envfile and add the following environment variables:S3_BUCKET_NAME: The name of the S3 bucket where the video and subtitles will be stored. THE BUCKET MUST BE PUBLIC.S3_DATASET_DIR: The folder path inside the S3 bucket where the video will be stored.AWS_ACCESS_KEY_ID: Your AWS access key ID.AWS_SECRET_ACCESS_KEY: Your AWS secret access key.AWS_DEFAULT_REGION: The AWS region where the S3 bucket is located.
-
Configure the environment file:
secrets.env. -
Open the
secrets.env.examplefile and save it assecrets.env. Then, add the following environment variables:TEAM_API_KEY: aiXplain Platform API key. (Generated from aiXplain platform from Team Settings > Integrations)HUGGINGFACE_TOKEN: Huggingface token for using the models. (You may get it from the huggingface website after signing up)
Start Database
To start the postgreSQL database and the redis database, run the following command.
bash docker-compose.sh startThis will create docker containers for each.
Start Celery
Use the following command to start celery. This is used to schedule tasks asynchronously.
celery -A src.service.tasks worker --loglevel=info --pool=threadsStart Backend
The following will start the backend service that handes the data processing.
uvicorn src.service.api:app --port 8089 --reloadStart WebApp Frontend
Please note that the previous services need to be running properly for the web app to work.
1. Annotator
You may use the following command to run the annotator app while in the project root directory.
python -m streamlit run --server.port 8501 ./src/web_app/annotator/🏠_Intro_annotator.py2. Admin
You may use the following command to run the admin app while in the project root directory.
python -m streamlit run --server.port 8502 --server.maxUploadSize 8192 ./tts-qa/src/web_app/admin/🏠_Intro_admin.pyYou may choose open ports of your choice.
You can upload a csv file containing the text and a zip file containing recordings. Example file may be downloaded from the frontend to see the format. Moreover, you may also extract the start and end ids of the recordings from the file names by providing a regex filter to extract those. After uploading the corresponding files, the processing will start. Once the initial processing end (visible through celery), you will need to start the trimming script using.
python ./tts-qa/src/utils/trim_asr.pyHow to dump and restore the database
The following command generates a backup dump of the database with the timestamp as its name, which you may save to s3.
docker exec -t postgres_container_dev pg_dump -U postgres dev_tts_db > dump_`date +%Y-%m-%d"_"%H_%M_%S`.sql
cat dump_2023-08-08_10_16_24.sql | docker exec -i postgres_container_dev psql -U postgres dev_tts_dbThe above is for postgres_container_dev, however, you can replace dev with prod for the production container.
Get Duration script
Here are some queries to run to get some insights about the data.
CREATE FUNCTION ROUND(float,int) RETURNS NUMERIC AS $f$
SELECT ROUND( CAST($1 AS numeric), $2 )
$f$ language SQL IMMUTABLE;SELECT dataset.name as dataset_name, ROUND(SUM(sample.trimmed_audio_duration) / 60, 2) AS minutes, ROUND(SUM(sample.trimmed_audio_duration) / 3600, 2) AS hours
FROM sample
JOIN dataset ON sample.dataset_id = dataset.id
WHERE dataset.name NOT LIKE '%English%' AND dataset.name NOT LIKE '%German%'
GROUP BY dataset.name
ORDER BY dataset.name;Sum of the duration of all the samples in a dataset
SELECT SUM(sample.trimmed_audio_duration) / 60 / 60 as duration_after_trimming
FROM sample
JOIN dataset ON sample.dataset_id = dataset.id
WHERE dataset.name LIKE '%' || 'English' || '%';Sum of the duration of all the samples for each dataset.language
SELECT dataset.language as dataset_name, ROUND(SUM(sample.trimmed_audio_duration) / 60, 2) AS minutes, ROUND(SUM(sample.trimmed_audio_duration) / 3600, 2) AS hours
FROM sample
JOIN dataset ON sample.dataset_id = dataset.id
WHERE dataset.name NOT LIKE '%English (A%'
GROUP BY dataset.language
ORDER BY dataset.language;