Summarize the Past to Predict the Future: Natural Language Descriptions of Context Boost Multimodal Object Interaction Anticipation (CVPR 2024)
[Paper] [Poster] [Website]
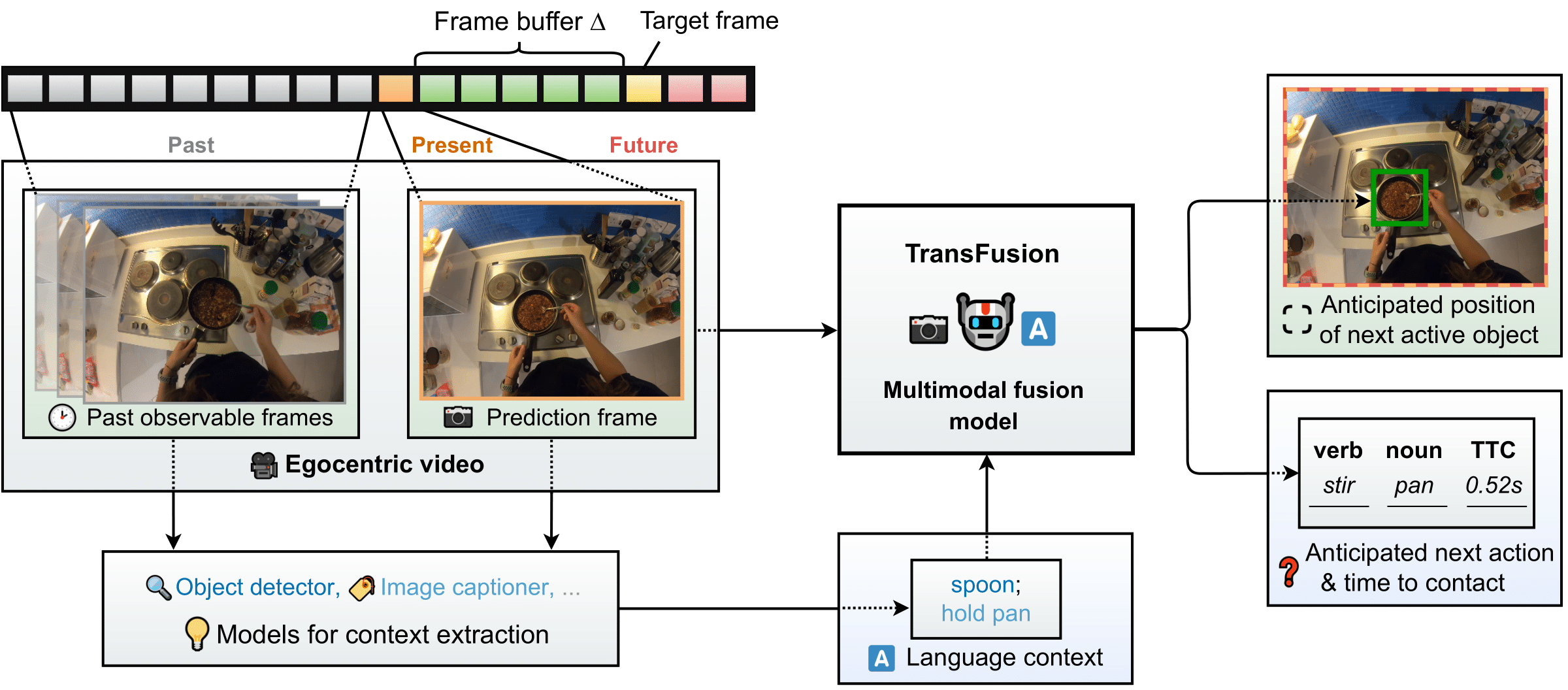
We propose TransFusion, a multimodal transformer-based architecture for short-term object interaction anticipation in egocentric videos. Our method exploits the representational power of language by summarizing the action context textually, after leveraging pre-trained image captioning and vision-language models to extract the action context from past video frames. The summarized action context and the last observed video frame are processed by a multimodal fusion module to forecast the next object interaction.
Preparation
Preparing environment
Please run the following commands:
conda create -n transfusion python=3.9
conda activate transfusion
pip install -r requirements.txtPreparing checkpoints and language context
Extract this file, containing initial checkpoints and language context files, into the project's root directory.
Preparing datasets
Please see here for instructions on how to download Ego4D resources. Place the Ego4D short-term object interaction anticipation annotation files into datasets/Ego4d/v1/annotations and/or datasets/Ego4d/v2/annotations, depending on which version(s) of the Ego4D dataset you wish to use.
Download the full-scale Ego4D videos into datasets/Ego4d/v1/full_scale and/or datasets/Ego4d/v2/full_scale. Then, run the following script to extract the prediction frames: python data_preprocessing/extract_prediction_frames.py --version={v1/v2}.
Running experiments
We provide convenience scripts train_ego4d.sh (for Ego4Dv1) and train_ego4dv2.sh (for Ego4Dv2) to begin training immediately using our best configurations.
In order to train using a custom configuration, set the DATA environment variable to the correct data storage path. CODE should be set to the repository root. RUNS sets where the experiment checkpoints and artifacts are to be saved.
The training is started using python runner/run_experiment.py --config <chosen main config file>.yml. The main configuration files are runner/nao/configs/ego_nao_res50_ego4d.yml (Ego4Dv1) and runner/nao/configs/ego_nao_res50_ego4dv2.yml (Ego4Dv2).
This step results in a trained model for bounding box and noun-verb classification. The model weights are saved both in the wandb runs (check your project) as well as offline (in the RUNS directory). Make sure to clean those locations and the .wandb_cache directory periodically when running multiple experiments, as they tend to get large.
SSL issues
In case the training terminates due to SSL-related errors when downloading external checkpoints for third-party libraries, you can pass the --skip-ssl-verification flag to the convenience scripts or the main training script in order to disable all SSL checks. Note that this may be risky if sensitive data is used with this project.
Obtaining predictions
Obtaining predictions for the validation set
Predictions for the validation set will be logged to wandb as JSON files conforming to the format used in the Ego4D evaluation protocol in case save_every >= 1.
Obtaining predictions for the test set
Requires running the model with the --run-test command line argument, as well as the --resume-from command line argument to the desired model checkpoint and version. If the argument is a wandb run link (e.g. --resume-from=1a2b3c4d:v5), the corresponding configuration files and weights will be downloaded. Alternatively, check the run configuration parameter documentation below.
Evaluation
To evaluate the produced validation set predictions, run the official Ego4D evaluation script with the desired prediction JSON file.
Test set predictions can be evaluated by submitting to the official eval.ai challenge server.
Hardware requirements
This framework supports DDP by default. Simply add all GPUs to be used as list entires in the run.devices option of the main configuration file. We recommend training our models on at least 3 80GB GPUs, which is the default setting for our Ego4Dv2 configuration file.
Note that metrics will be computed on parts of the data when using more than one GPU, and the metrics should be recomputed manually by fusing all logged prediction JSONs associated with the respective epoch and running the official Ego4D evaluation script on the fused result so as to obtain an exact value. If you are using wandb, we provide the convenience script runner/utils/evaluate_wandb_jsons.py to download, fuse and evaluate the prediction JSONs from wandb automatically. Please consult the argument help strings in this script for more information on how to use it.
Please be aware that the validation sanity check at the start of training logs a small JSON prediction file to wandb, which will have the artifact version v0. The actual prediction JSON artifacts will start at v1 for epoch 0, v2 for epoch 1, etc.
Note that 16-bit precision can be used by setting run.precision: 16. This setting is the default for Ego4Dv1 and allows to train an Ego4Dv1 model on one 80GB GPU. However, we have observed that this may lead to numerical instabilities in the form of a NaN loss. In the event that this happens, we recommend restarting the training using 32-bit precision.
TTC
Using a linear head for TTC prediction gives suboptimal performance on TTC-related metrics. As reported in the paper, the TTC predictions from the linear head are replaced with TTC predictions from the standard Ego4D SlowFast-based TTC predictor after obtaining the results from the pipeline to improve performance.
To replace the initial TTC predictions with predictions from the Ego4D pipeline, generate prediction JSONs as described above, then obtain the corresponding TTC predictions from the Ego4D TTC predictor. You can use runner/utils/produce_object_detections.py --input-path=<path to prediction file> to obtain a JSON file with object detections from the prediction JSON produced by our pipeline. Note that this will require downloading the LMDB files and SlowFast checkpoint associated with the respective Ego4D version. Finally, run runner/utils/adapt_ttc_values.py --input-path=<path to prediction file> --ttc-reference-path=<path to output of Ego4D TTC predictor> --output-path=<desired output path> to obtain an output file with improved TTC results.
The command to produce TTC predictions using the Ego4D TTC predictor should look similar to this: <details style="margin-bottom: 20px";>
python scripts/run_sta.py \
--cfg configs/Ego4dShortTermAnticipation/SLOWFAST_32x1_8x4_R50.yaml \
TRAIN.ENABLE False TEST.ENABLE True ENABLE_LOGGING False \
CHECKPOINT_FILE_PATH <path to slowfast_model.ckpt of respective version> \
RESULTS_JSON <path to result JSON> \
CHECKPOINT_LOAD_MODEL_HEAD True \
DATA.CHECKPOINT_MODULE_FILE_PATH "" \
CHECKPOINT_VERSION "" \
TEST.BATCH_SIZE 1 NUM_GPUS 1 \
EGO4D_STA.OBJ_DETECTIONS <path to object detection JSON> \
EGO4D_STA.ANNOTATION_DIR <path to of respective dataset version> \
EGO4D_STA.RGB_LMDB_DIR <path to directory with LMDB files> \
EGO4D_STA.TEST_LISTS "['<fho_sta_val.json or fho_sta_test_unannotated.json>']"Configuration file structure
Please see CONFIG.md for explanations of the options in the configuration files.