jemalloc.NET: A native memory manager for .NET
Get the latest 0.2.x release from the releases page.
jemalloc.NET is a .NET API over the jemalloc native memory allocator and provides .NET applications with efficient data structures backed by native memory for large scale in-memory computation scenarios. jemalloc is "a general purpose malloc(3) implementation that emphasizes fragmentation avoidance and scalable concurrency support" that is widely used in the industry, particularly in applications that must scale and utilize large amounts of memory. In addition to its fragmentation and concurrency optimizations, jemalloc provides an array of developer options for debugging, monitoring and tuning allocations that makes it a great choice for use in developing memory-intensive applications.
The jemalloc.NET project provides:
- A low-level .NET API over the native jemalloc API functions like je_malloc, je_calloc, je_free, je_mallctl...
- A safety-focused high-level .NET API providing data structures like arrays backed by native memory allocated using jemalloc together with management features like reference counting and acceleration features like SIMD vectorized operations via the
Vector<T>.NET type. - A benchmark CLI program:
jembenchwhich uses the excellent BenchmarkDotNet library for easy and accurate benchmarking operations on native data structures vs managed objects using different parameters.
The high-level .NET API makes use of newly introduced C# and .NET features and classes like ref returns, Span<T>, Vector<T>, and Unsafe<T> from the System.Runtime.CompilerServices.Unsafe libraries, for working effectively with pointers to managed and unmanaged memory.
Data structures provided by the high-level API are more efficient than managed .NET arrays and objects at the scale of millions of elements, and memory allocation is much more resistant to fragmentation, while still providing necessary safety features like array bounds checking. Large .NET arrays must be allocated on the Large Object Heap and are not relocatable which leads to fragmentation and lower performance. In a benchmark specifically designed to fragment managed and unmanaged memory using arrays of Int32, jemalloc.NET performs a order of magnitude better that the .NET managed heap allocator at the cost of higher memory utilization:
BenchmarkDotNet=v0.10.11, OS=Windows 10 Redstone 2 [1703, Creators Update] (10.0.15063.726)
Processor=Intel Core i7-6700HQ CPU 2.60GHz (Skylake), ProcessorCount=8
Frequency=2531251 Hz, Resolution=395.0616 ns, Timer=TSC
.NET Core SDK=2.1.2
[Host] : .NET Core 2.0.3 (Framework 4.6.25815.02), 64bit RyuJIT
Job=JemBenchmark Jit=RyuJit Platform=X64
Runtime=Core AllowVeryLargeObjects=True Toolchain=InProcessToolchain
RunStrategy=ColdStart
| Method | Parameter | Mean | Error | StdDev | PrivateMemory | Scaled | ScaledSD | Gen 0 | Gen 1 | Gen 2 | Allocated |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 'Run an allocation pattern that won't fragment the Large Object Heap.' | 100 | 763.74 ms | 7.536 ms | 7.049 ms | 42.1 MB | 1.00 | 0.00 | 101000.0000 | 101000.0000 | 101000.0000 | 45436.08 MB |
| 'Run an allocation pattern that fragments the Large Object Heap.' | 100 | 786.95 ms | 15.568 ms | 19.689 ms | 76.0 MB | 1.03 | 0.03 | 101000.0000 | 101000.0000 | 101000.0000 | 45436.09 MB |
| 'Run an allocation pattern that fragments the Large Object Heap with regular GC compaction.' | 100 | 790.30 ms | 15.392 ms | 19.466 ms | 75.9 MB | 1.03 | 0.03 | 111000.0000 | 111000.0000 | 111000.0000 | 45436.08 MB |
| 'Run an allocation pattern that won't fragment the unmanaged heap.' | 100 | 59.63 ms | 2.205 ms | 6.502 ms | 52.6 MB | 0.08 | 0.01 | 1000.0000 | 1000.0000 | 1000.0000 | 1.97 MB |
| 'Run an allocation pattern that fragments the unmanaged heap.' | 100 | 69.48 ms | 1.376 ms | 2.810 ms | 90.7 MB | 0.09 | 0.00 | 1000.0000 | 1000.0000 | 1000.0000 | 2.59 MB |
You can run this benchmark with the jembench command: jembench malloc --fragment 100 -u -b --cold-start
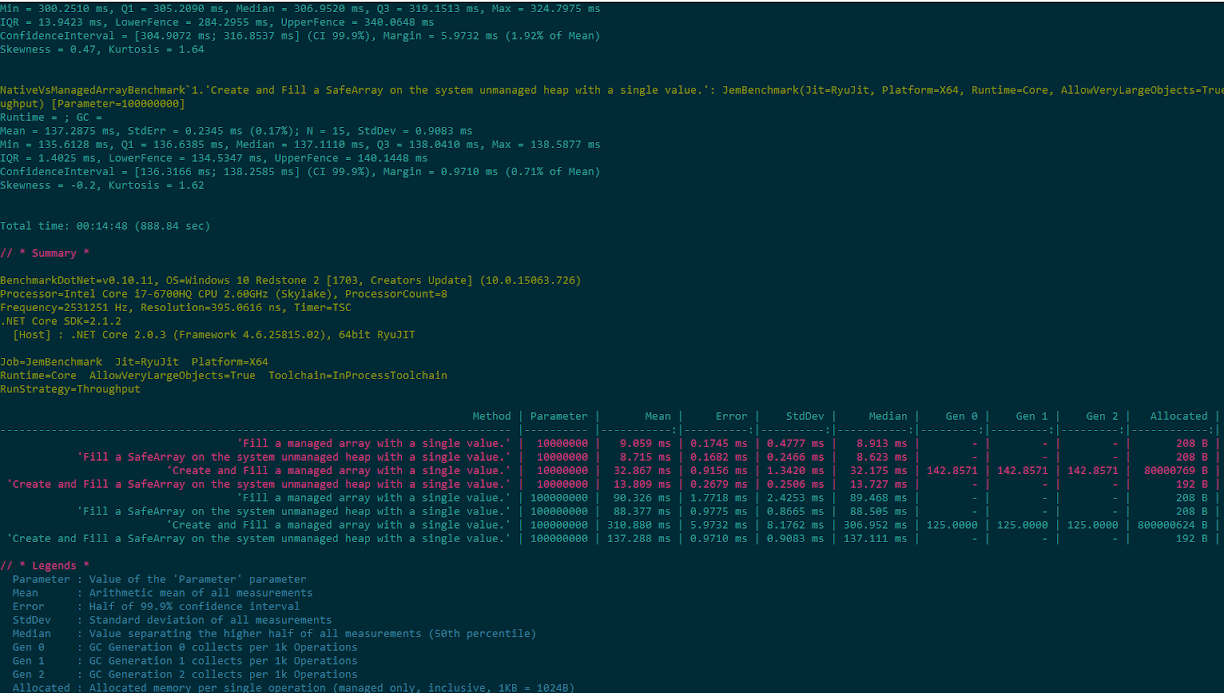
In the following jembench benchmark, simply filling an array is more or less the same across different kinds of memory and scales linearly depending on the size of the array, but allocating and filling a UInt64[] managed array of size 10000000 and 100000000 is more than 2x slower than using an equivalent native array provided by jemalloc.NET:
BenchmarkDotNet=v0.10.11, OS=Windows 10 Redstone 2 [1703, Creators Update] (10.0.15063.726)
Processor=Intel Core i7-6700HQ CPU 2.60GHz (Skylake), ProcessorCount=8
Frequency=2531251 Hz, Resolution=395.0616 ns, Timer=TSC
.NET Core SDK=2.1.2
[Host] : .NET Core 2.0.3 (Framework 4.6.25815.02), 64bit RyuJIT
Job=JemBenchmark Jit=RyuJit Platform=X64
Runtime=Core AllowVeryLargeObjects=True Toolchain=InProcessToolchain
RunStrategy=Throughput
| Method | Parameter | Mean | Error | StdDev | Median | Gen 0 | Gen 1 | Gen 2 | Allocated |
|---|---|---|---|---|---|---|---|---|---|
| 'Fill a managed array with a single value.' | 10000000 | 9.059 ms | 0.1745 ms | 0.4777 ms | 8.913 ms | - | - | - | 208 B |
| 'Fill a SafeArray on the system unmanaged heap with a single value.' | 10000000 | 8.715 ms | 0.1682 ms | 0.2466 ms | 8.623 ms | - | - | - | 208 B |
| 'Create and Fill a managed array with a single value.' | 10000000 | 32.867 ms | 0.9156 ms | 1.3420 ms | 32.175 ms | 142.8571 | 142.8571 | 142.8571 | 80000769 B |
| 'Create and Fill a SafeArray on the system unmanaged heap with a single value.' | 10000000 | 13.809 ms | 0.2679 ms | 0.2506 ms | 13.727 ms | - | - | - | 192 B |
| 'Fill a managed array with a single value.' | 100000000 | 90.326 ms | 1.7718 ms | 2.4253 ms | 89.468 ms | - | - | - | 208 B |
| 'Fill a SafeArray on the system unmanaged heap with a single value.' | 100000000 | 88.377 ms | 0.9775 ms | 0.8665 ms | 88.505 ms | - | - | - | 208 B |
| 'Create and Fill a managed array with a single value.' | 100000000 | 310.880 ms | 5.9732 ms | 8.1762 ms | 306.952 ms | 125.0000 | 125.0000 | 125.0000 | 800000624 B |
| 'Create and Fill a SafeArray on the system unmanaged heap with a single value.' | 100000000 | 137.288 ms | 0.9710 ms | 0.9083 ms | 137.111 ms | - | - | - | 192 B |
You can run this benchmark with the command jembench array --fill 10000000 100000000 -l -u. In this case we see that using the managed array of size 10 million elements allocated 800 MB on the managed heap while using the native array did not cause any allocations on the managed heap for the array data. Avoiding the managed heap for very large but simple data structures like arrays is a key optimizarion for apps that do large-scale in-memory computation.
Managed .NET arays are also limited to Int32 indexing and a maximum size of about 2.15 billion elements. jemalloc.NET provides huge arrays through the HugeArray<T> class which allows you to access all available memory as a flat contiguous buffer using array semantics. In the next benchmark jembench hugearray --fill -i 4200000000:
BenchmarkDotNet=v0.10.11, OS=Windows 10 Redstone 2 [1703, Creators Update] (10.0.15063.726)
Processor=Intel Core i7-6700HQ CPU 2.60GHz (Skylake), ProcessorCount=8
Frequency=2531251 Hz, Resolution=395.0616 ns, Timer=TSC
.NET Core SDK=2.1.2
[Host] : .NET Core 2.0.3 (Framework 4.6.25815.02), 64bit RyuJIT
Job=JemBenchmark Jit=RyuJit Platform=X64
Runtime=Core AllowVeryLargeObjects=True Toolchain=InProcessToolchain
RunStrategy=ColdStart TargetCount=7 WarmupCount=-1
| Method | Parameter | Mean | Error | StdDev | Allocated |
|---|---|---|---|---|---|
| 'Fill a managed array with the maximum size [2146435071] with a single value.' | 4200000000 | 3.177 s | 0.1390 s | 0.0617 s | 8585740456 B |
| 'Fill a HugeArray on the system unmanaged heap with a single value.' | 4200000000 | 4.029 s | 3.2233 s | 1.4312 s | 0 B |
an Int32[] of maximum size can be allocated and filled in 3.2s. This array consumes 8.6GB on the managed heap. But a jemalloc.NET HugeArray<Int32> of nearly double the size at 4.2 billion elements can be allocated in only 4 s and again consumes no memory on the managed heap. The only limit on the size of a HugeArray<T> is the available system memory.
Perhaps the killer feature of the recently introduced Span<T> class in .NET is its ability to efficiently zero-copy reinterpret numeric data structures (Int32, Int64 and their siblings) into other structures like the Vector<T> SIMD-enabled data types introduced in 2016. Vector<T> types are special in that the .NET RyuJIT compiler can compile operations on Vectors to use SIMD instructions like SSE, SSE2, and AVX for parallelizing operations on data on a single CPU core.
Using the SIMD-enabled SafeBuffer<T>.VectorMultiply(n) method provided by the jemalloc.NET API yields a more than 12x speedup for a simple in-place multiplication of a UInt64[] array of 10 million elements, compared to the unoptimized linear approach, allowing the operation to complete in 60 ms:
BenchmarkDotNet=v0.10.11, OS=Windows 10 Redstone 2 [1703, Creators Update] (10.0.15063.726)
Processor=Intel Core i7-6700HQ CPU 2.60GHz (Skylake), ProcessorCount=8
Frequency=2531251 Hz, Resolution=395.0616 ns, Timer=TSC
.NET Core SDK=2.1.2
[Host] : .NET Core 2.0.3 (Framework 4.6.25815.02), 64bit RyuJIT
Job=JemBenchmark Jit=RyuJit Platform=X64
Runtime=Core AllowVeryLargeObjects=True Toolchain=InProcessToolchain
RunStrategy=Throughput
| Method | Parameter | Mean | Error | StdDev | Gen 0 | Gen 1 | Allocated |
|---|---|---|---|---|---|---|---|
| 'Multiply all values of a managed array with a single value.' | 10000000 | 761.10 ms | 10.367 ms | 9.190 ms | 254250.0000 | 62.5000 | 800000304 B |
| 'Vector multiply all values of a native array with a single value.' | 10000000 | 59.23 ms | 1.170 ms | 1.149 ms | - | - | 360 B |
For huge arrays of UInt16[] we see similar speedups:
BenchmarkDotNet=v0.10.11, OS=Windows 10 Redstone 2 [1703, Creators Update] (10.0.15063.726)
Processor=Intel Core i7-6700HQ CPU 2.60GHz (Skylake), ProcessorCount=8
Frequency=2531251 Hz, Resolution=395.0616 ns, Timer=TSC
.NET Core SDK=2.1.2
[Host] : .NET Core 2.0.3 (Framework 4.6.25815.02), 64bit RyuJIT
Job=JemBenchmark Jit=RyuJit Platform=X64
Runtime=Core AllowVeryLargeObjects=True Toolchain=InProcessToolchain
RunStrategy=ColdStart TargetCount=1
| Method | Parameter | Mean | Error | Gen 0 | Gen 1 | Allocated |
|---|---|---|---|---|---|---|
| 'Multiply all values of a managed array with the maximum size [2146435071] with a single value.' | 4096000000 | 34.25 s | NA | 16375000.0000 | 3000.0000 | 51514441704 B |
| 'Vector multiply all values of a native array with a single value.' | 4096000000 | 12.06 s | NA | - | - | 0 B |
For a huge array with 4.1 billion UInt16 values it takes 12 seconds to do a SIMD-enabled multiplication operation on all the elements of the array. This is still 3x the performance of doing the same non-vectorized operation on a managed array of half the size.
Inside a .NET application, jemalloc.NET native arrays and data structures can be straightforwardly accessed by native libraries without the need to make additional copies or allocations. The goal of the jemalloc.NET project is to make accessible to .NET the kind of big-data in-memory numeric, scientific and other computing that typically would require coding in a low-level language like C/C++ or assembly.
How it works
Memory allocations are made using the jemalloc C functions like je_malloc, je_calloc etc, and returned as IntPtr pointers. Memory alignment is handled by jemalloc and memory allocations (called extents) are aligned to a multiple of the jemalloc page size e.g 4K. Inside extents, elements are aligned according to the .NET struct alignment specified using the StructLayout and other attributes. In the future the ability to manually align structures inside an extend and jemalloc's ability to manually align each extent (e.g using the je_posix_memalign function) may be exposed to alleviate potential performance problems with the default jemalloc page alignment.
Each allocation pointer is tracked in a thread-safe allocations ledger together with a reference count. Each valid Jem.NET data structure has a pointer in the allocations ledger. There are other allocation ledgers that track details of different data structures like FixedBufferAllocation. When a pointer to an extent is released by a data stucture it is removed from all allocation ledgers. During the free operation the memory extent is filled with junk values by jemalloc as a safety feature however this feature and many other aspects of jemalloc can be turned off or on by the user.
Any attempt to read or write data structure memory locations is guarded by checking that the data structure owns a valid pointer to the memory location. Since there can't be two pointers allocated with the same address at the same time, pointers act as a unique Id for tracking the active memory extents. Data structures are provided with reference counting methods like Acquire() and Release() to manage their lifetimes. Attempts to free or dispose of a data structure with a non-zero reference count will throw an exception. Unlike the stack-only Span<T> you are allowed to use class fields and properties to hold Jem.NET data structures like FixedBuffer<T> because FixedBuffer<T> guards every access to memory by first checking if the memory extent it is assigned is still valid. However you must take responsibility for using the reference counting features correctly i.e when sharing data structures between methods and threads you should always call FixedBuffer<T>.Acquire() to prevent a nethod from accidentally releasing the buffer's memory when it is in use.
In data structures like FixedBuffer<T> the primitive .NET types are always correctly aligned for SIMD vectorized operations and such operations like FixedBuffer<T>.VectorMultiply() can be significatnly faster than the non-optimized variants. E.g. an in-place multiplication of a FixedBuffer<Uint16> is many times faster than the same operation on a .NET Uint16[]:
BenchmarkDotNet=v0.10.11, OS=Windows 10 Redstone 2 [1703, Creators Update] (10.0.15063.726)
Processor=Intel Core i7-6700HQ CPU 2.60GHz (Skylake), ProcessorCount=8
Frequency=2531251 Hz, Resolution=395.0616 ns, Timer=TSC
.NET Core SDK=2.1.2
[Host] : .NET Core 2.0.3 (Framework 4.6.25815.02), 64bit RyuJIT
Job=JemBenchmark Jit=RyuJit Platform=X64
Runtime=Core AllowVeryLargeObjects=True Toolchain=InProcessToolchain
RunStrategy=Throughput
| Method | Parameter | Mean | Error | StdDev | Gen 0 | Gen 1 | Allocated |
|---|---|---|---|---|---|---|---|
| 'Multiply all values of a managed array with a single value.' | 10000000 | 606.33 ms | 4.1602 ms | 3.4740 ms | 228875.0000 | 4.1667 | 703125.3 KB |
| 'Vector multiply all values of a native array with a single value.' | 10000000 | 36.40 ms | 0.5256 ms | 0.4659 ms | - | - | 1.32 KB |
Pointers to data structure memory extents can be passed directly to unmanaged functions and libraries without the need for marshalling or more allocations. This is important when you want to build high-performance apps that use libraries written in C or assembly that process large amounts of in-memory data.
Installation
Requirements
Currently only runs on 64bit Windows; support for Linux 64bit and other 64bit platforms supported by .NET Core will be added soon.
Windows
- The latest .NET Core 2.0 x64 runtime
- The latest version of the Microsoft Visual C++ Redistributable for Visual Studio 2017
Steps
Grab the latest release from the releases page and unzip to a folder. Type jembench to run the benchmark CLI program and you should see the program version and options printed. NuGet packagees can be found in x64\Release. The API library assembly files themselves are in x64\Release\netstandard2.0
Note that if using jemalloc.NET in your own projects you must put the native jemallocd.dll library somewhere where it can be located by the .NET runtime. You can create a post-build step to copy it to the output folder of your project or put it somewhere on your %PATH%.
Usage
High-level API
Currently there are 4 implemented native memory data structures:
1. FixedBuffer<T>
FixedBuffer<T> is a fixed-length array of data backed by memory on the unmanaged heap, that is implemented as .NET struct. The underlying data type of a FixedBuffer<T> must be a primitive type: Boolean, Byte, SByte, Int16, UInt16, Int32, UInt32, Int64, UInt64, IntPtr, UIntPtr, Char, Double, or Single.
FixedBuffer<Int64> buffer = new FixedBuffer<Int64>(1000000); // Create an array of 1 million Int64 integers.
buffer.Fill(100);
long a = buffer[10]; //copy on read
ref long b = ref buffer[10]; // no copy...b is an alias to the memory location of buffer[10]Primitives types have a maximum width of 64bits and (assuming correct memory alignment) can be read and updated atomically on machines with a 64bit word-size. This eliminates the possibility of 'struct tearing', or struct fields being read or written to inconsistently by multiple concurrent operations, because reads and writes to FixedBuffer<T> elements are only done directly to the underlying memory location for the data element.
All properties and fields of FixedBuffer<T> are readonly with only the index operator [] returing a ref T to the underlying data element. To use copy-on-read semantics simply create and assign variables to elements in the array. Use ref variables to get an alias to the memory location itself:
FixedBuffer<int> b = ...;
int num = b[15];
num = 6; // b[15] is still 6
ref int r = ref b[15]; //get an alias to b[15]
r = 23; // b[15] is nowAlthough FixedBuffer<T> is a .NET value type, only the metadata about the data structure is copied from one variable assignment to another. The actual data of a FixedBuffer<T> resides at a single memory location only. Each data access to a <T> element in a FixedBuffer<T> from all copies of a FixedBuffer<T> will read and write the same memory and makes the same guard checks against the same pointer in the allocations ledger. When the pointer used by a FixedBufferFixedBuffer<T> automatically becomes invalid. e.g:
FixedBuffer<int> array = new FixedBuffer<int>(100);
array[16] = 1;
FixedBuffer<int> copy = array;
int a = copy[16]; // a is 16;
copy[5] = 99;
int b = array[5]; // b is 99
copy.Free(); Invalidate the buffer from the copy
int c = array[16]; //InvalidOperationException thrown here
You can create user-defined structures that contain FixedBuffer<T> e.g
public struct Employee : IEquatable<Employee>
{
...
public DateTime? DOB { get; set; }
public decimal Balance { get; set; }
public FixedBuffer<float> BonusPayments { get; set; }
public FixedBuffer<byte> Photo { get; set; } //8
}The FixedUtf8String type is another struct that uses a FixedBuffer<byte> for storage of string data.
public readonly struct FixedUtf8String : IEquatable<FixedUtf8String>, IRetainable, IDisposable
{
...
#region Fields
private readonly FixedBuffer<byte> buffer;
private const int StringNotFound = -1;
...Each FixedBuffer<T> has a constructor from T[] which copies the data from the managed array to the unmanaged buffer allocated.
public static TestUDT MakeTestRecord(Random rng)
{
Guid _id = Guid.NewGuid();
string _ids = _id.ToString("N");
byte[] photo = new byte[4096];
rng.NextBytes(photo);
return new TestUDT()
{
ID = _id,
FirstName = new FixedUtf8String("Gavial-" + _id.ToString("D").Substring(0, 4)),
LastName = new FixedUtf8String("Buxarinovich-" + _id.ToString("D").Substring(0, 4)),
DOB = _ids.StartsWith("7") ? (DateTime?)null : DateTime.UtcNow,
Balance = 2131m,
Photo = new FixedBuffer<byte>(photo)
};
}Arrays of these kinds of user-defined structures can also be stored in native memory using the SafeBuffer<T> class.
2. SafeBuffer<T>
SafeBuffer<T> is a fixed-length array of data backed by memory on the unmanaged heap that inherits from the .NET SafeHandle class and is implemented as .NET class i.e a reference type. SafeBuffer<T> is an abstract class that can be used as the base to create data-structures like arrays or trees that are backed by unmanaged memory. The implemented SafeArray<T> class is the simplest concrete class that derives from SafeBuffer. SafeArray<T> can contain both primitive types and user-defined structures e.g:
public struct Employee : IEquatable<Employee>
{
public Guid ID { get; set; }
public FixedUtf8String FirstName { get; set; }
public FixedUtf8String LastName { get; set; }
public DateTime? DOB { get; set; }
public decimal Salary { get; set; }
public FixedBuffer<float> Bonuses { get; set; }
public FixedBuffer<byte> Photo { get; set; }
}
...
public SafeArray<Employee> employees = new SafeArray<Employee>(100);The only restrictions on the type T of a SafeBuffer<T> is that it must be a struct and it must implement IEquatable<T>
3. FixedUtf8Buffer
FixedUtf8Bufferis a fixed-length immutable string type using UTF-8 encoding that is backed by memory on the unmanaged heap and is implemented as a .NET struct You can create user-defined structures that contain a FixedUtf8Buffer or create a SafeBuffer<FixedUtf8Buffer> for representing arrays of stringd. Some commmon string operations are implemented like IndexOf() and Substring() and there is a constructor taking a .NET String.
4. HugeBuffer<T>
HugeBuffer<T> is similar to SafeBuffer<T> but with the ability to store and index up to Int64.MaxValue array elements. HugeBuffer<T> lets you treat all available memory as a linear contiguous buffer.
Tuning jemalloc
The jemalloc allocator contains many parameters that can be adjusted to suit the workload and allocation patterns of the application.
Jem.Init(string conf)
Jem.SetMallCtlInt32(int value)
jembench CLI
Examples:
jembench hugearray -l -u --math --cold-start -t 3 4096000000Benchmark math operations onHugeArray<UInt64>arrays of size 4096000000 without benchmark warmup and only using 3 iterations of the target methods. Benchmarks on huge arrays can be lengthy so you should carefully choose the benchmark parameters affecting how long you want the benchmark to run,
Building from source
Currently build instuctions are only provided for Visual Studio 2017 on Windows but instructions for building on Linux will also be provided. jemalloc.NET is a 64-bit library only.
Requirements
Visual Studio 2017 15.5 with at least the following components:
- C# 7.2 compiler
- .NET Core 2.x SDK x64
- MSVC 2017 compiler toolset v141 or higher
- Windows 10 SDK for Desktop C++ version 10.0.10.15603 or higher. Note that if you only have higher versions installed you will need to retarget the jemalloc MSVC project to your SDK version from Visual Studio.
Per the instructions for building the native jemalloc library for Windows, you will also need Cygwin (32- or 64-bit )with the following packages:
- autoconf
- autogen
- gcc
- gawk
- grep
- sed
Cygwin tools aren't actually used for compiling jemalloc but for generating the header files. jemalloc on Windows is built using MSVC.
Steps
- You must add the .NET Core NuGet feed on MyGet and also the CoreFxLab feed to your NuGet package sources. You can do this in Visual Studio 2017 from Tools->Options->NuGet Package Manager menu item.
- Clone the project:
git clone https://github.com/alllisterb/jemalloc.NETand init the submodules:git submodule update --init --recursive - Open a x64 Native Tools Command Prompt for VS 2017 and temporarily add
Cygwin\binto the PATH e.gset PATH=%PATH%;C:\cygwin\bin. Switch to thejemallocsubdirectory in your jemalloc.NET solution dir and runsh -c "CC=cl ./autogen.sh". This will generate some files in thejemallocsubdirectory and only needs to be done once. - From a Visual Studio 2017 Developer Command prompt run
build.cmd. Alternatively you can load the solution in Visual Studio and using the "Benchmark" solution configuration build the entire solution. - The solution should build without errors.
- Run
jembenchfrom the solution folder to see the project version and help.