Tracking Trans Hate Bills
What Is This?
This repository is my workspace for investigating anti-trans legislation proposed in the US in 2023.
This repository is not intended to identify these bills, which is just too large a task for one person. Instead, I am using two lists that are actively being compiled by other organizations: the ACLU and trackingtranslegislation.com.
- Mapping Attacks on LGBTQ Rights in U.S. State Legislatures | American Civil Liberties Union
- 2023 Anti-Trans Bills | Track Trans Legislation
A Guide to the Repository
Retrieval
The datasets can be retrieved or updated using the scripts retrieval/get_aclu_data.ipynb and retrieval/get_ttl_data.ipynb. There's an additional script (retrieval/get_equality_texas.ipynb) for retrieving data from EqualityTexas, but that data isn't currently incorporated into any of the pipelines. The script retrieval/legiscan_lookup_aclu.ipynb is used to resolve bills tracked by the ACLU to legiscan IDs so that we can use the Legiscan service to get more information about them--including downloading the text of the bill with retrieval/retrieve_legislation.ipynb. Finally, retrieval/build_neutral_corpus.ipynb is for constructing a corpus of neutral bills in order to compare their statistical properties to those of the anti-trans corpus.
Visualization
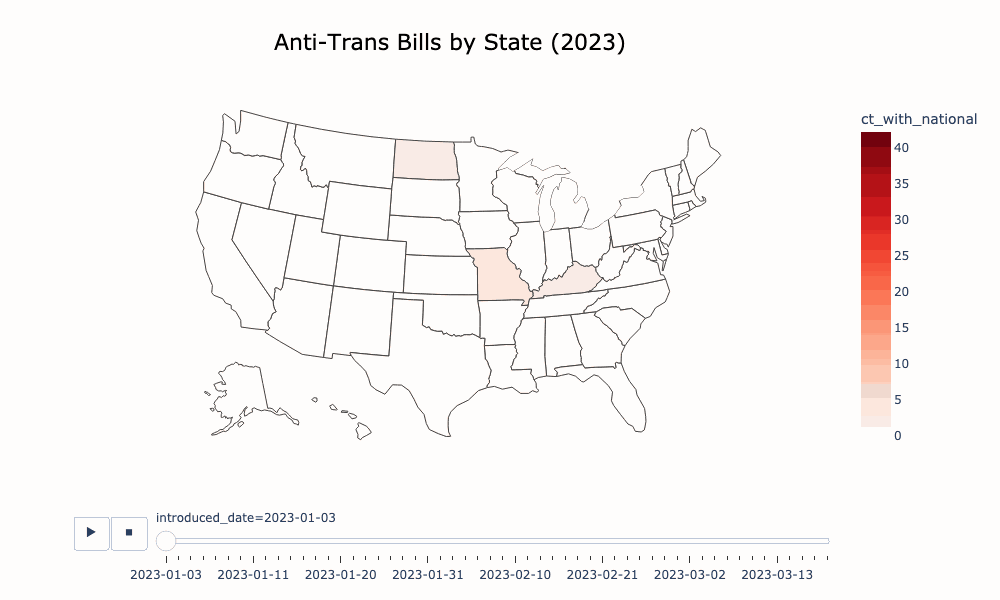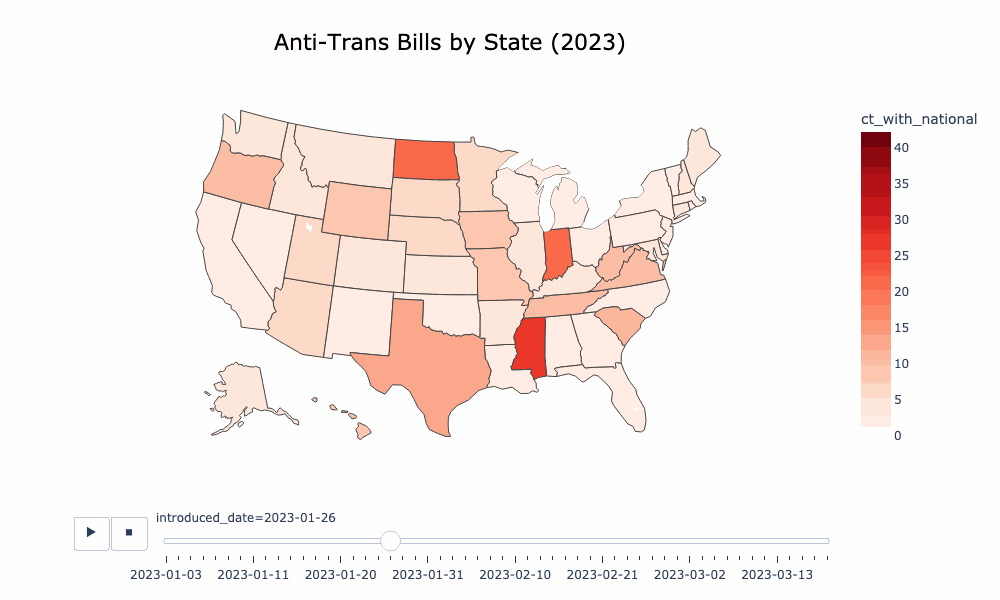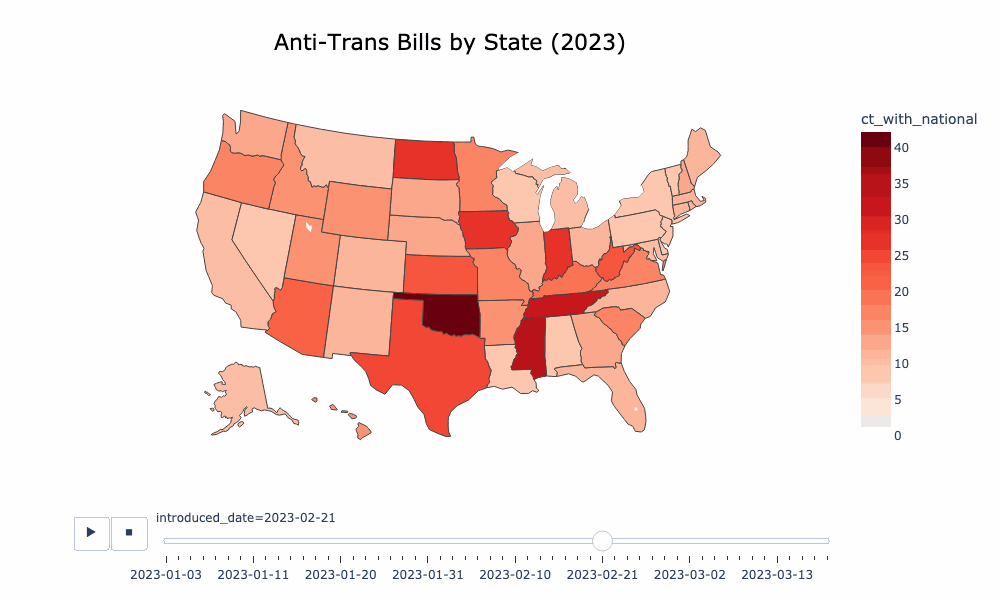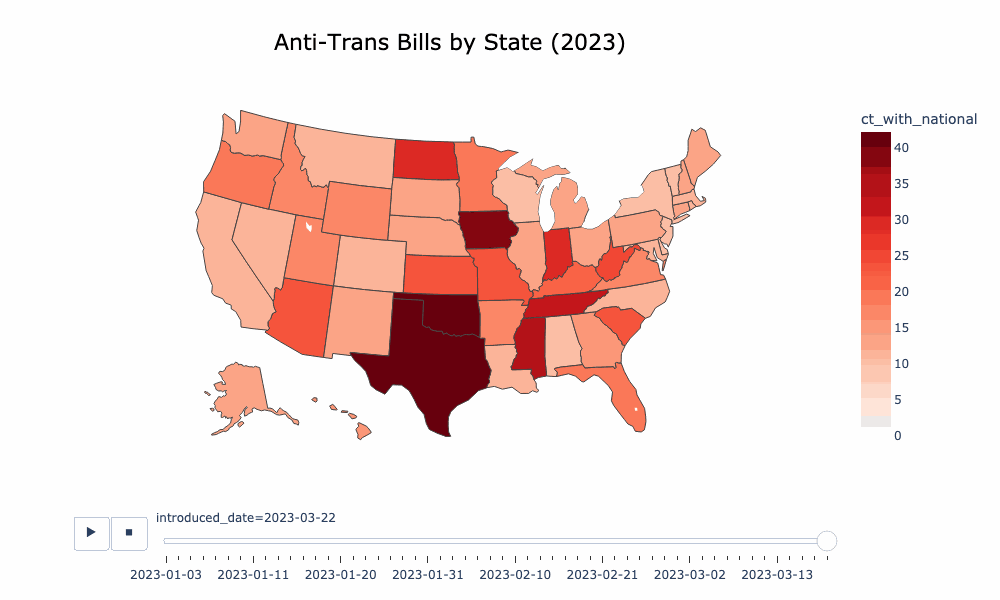
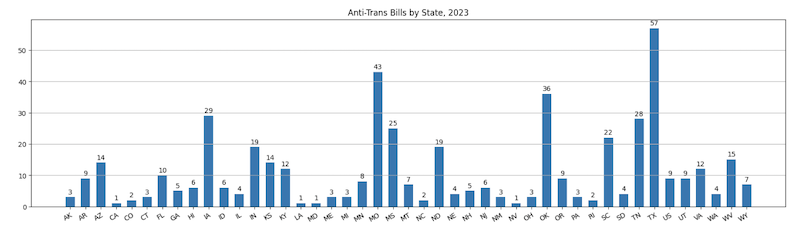
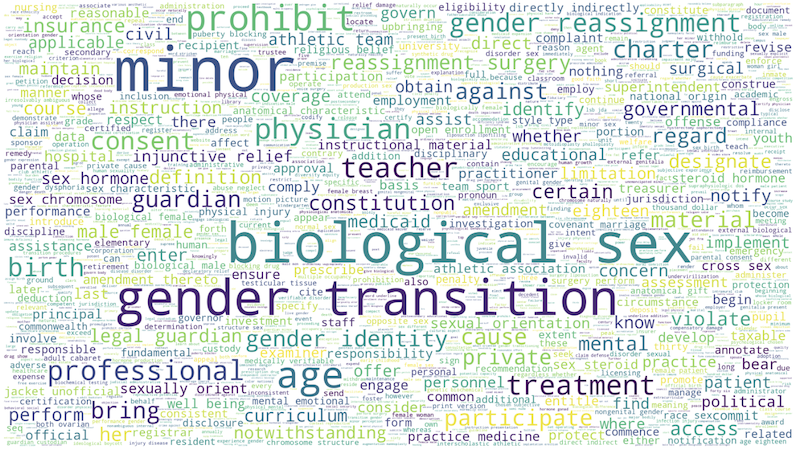
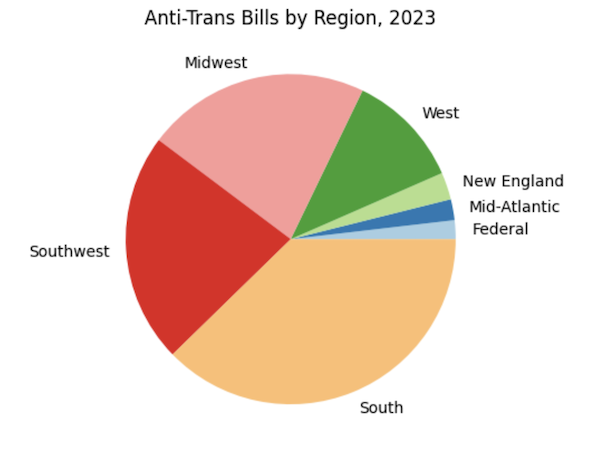
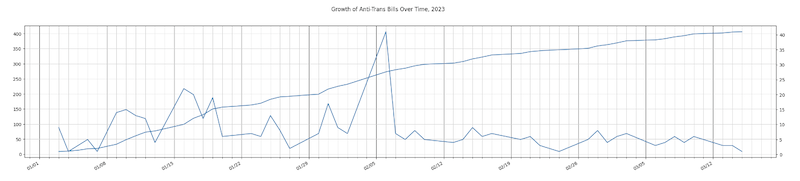
If you're interested in time series or pie chart visualizations, you probably want to look at visualize/aggregate.ipynb, which operates on an aggregation of the ACLU and TTL data. There is an animated choropleth in visualize/animated_choropleth.ipynb. I have also put a lot of work into making a decent word cloud of the bills as well, which you can find here: visualize/word_freq.ipynb.
 |
 |
 |
 |
Investigation
The scripts that build the aggregate dataset from the ACLU and TTL data are found in investigate/aggregate.ipynb and investigate/categorize.ipynb. investigate/conserved_phrases investigates common large n-grams across the corpus. investigate/generate_legal_stopwords.ipynb can be used to generate or refresh the list of stopwords that is specialized for legal documents. Finally, a quick exploration of ngrams in the hate emails corpus is in investigate/hate-emails-ngrams.ipynb.
Archive
An archive of the data I retrieved from the Legiscan API can be found in archive. This is divided into bills, which contains the actual bills, and meta, which contains metadata about each piece of legislation.
Artifacts
Anything created or modified by the notebooks is in the artifacts directory.
Lib / Tasks
The lib and tasks directories contain reusable code. The goal is to pull anything reusable out of the notebooks and build composable units that can be combined into various automated pipelines. This way the different notebooks wouldn't need to be run in a particular order when new data arrives.
TL;DR
| Directory | Description | Data | Code |
|---|---|---|---|
| archive | All bills and metadata of which I am currently aware | ✓ | |
| artifacts | Various files built by the repository during the course of its operation | ✓ | ✓ |
| bills | Work directory to store contents of downloaded bills | ✓ | |
| configuration | Configuration files used to help code work correctly | ✓ | |
| datasets | Datasets retrieved and used by the code | ✓ | |
| investigate | Analyses of the data that don't necessarily produce visual results | ✓ | |
| lib | Code intended to be reused between many notebooks | ✓ | |
| obsolete | Stuff that I don't want to throw away but don't use any more | ✓ | ✓ |
| retrieval | Code whose job is to retrieve datasets or bills | ✓ | |
| static | Assets needed for documentation or literate notebook | ✓ | |
| tmp | Directory for temporary files produced by running notebooks | ✓ | |
| visualize | Notebooks that visualize the datasets in some way | ✓ |
Getting Started Developing
To get started with this project, you'll want to have poetry and Python 3.9.10 (we recommend pyenv) already installed. Clone the repository and then use poetry to install the packages used here. I recommend the poetry plugin poetry-dotenv-plugin for handling the environment variables for accessing the Legiscan API.
$ poetry install
$ poetry self add poetry-dotenv-plugin
$ cp env-template .envIf you wish to consume the Legiscan API, you'll need to sign up at https://legiscan.com/user/register. Once you do, you can create an API key. Put your username, password, and API key in the .env file; note that this file is excluded from git for security. Once your setup is done, start jupyter lab and dig in:
$ poetry run jupyter labNote that if you change your .env you'll need to respawn your jupyter lab server, as it only parses environment variables out of that file at startup.