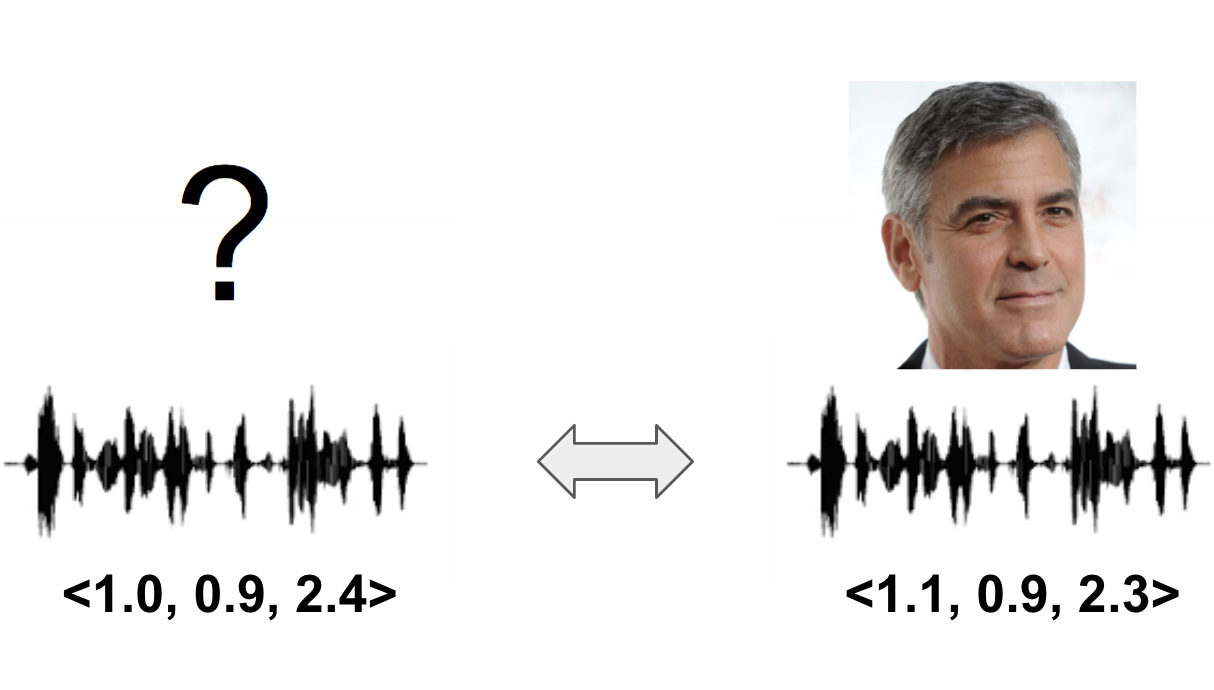
Text-independent voice vectors
Subtitle: which of the Hollywood stars is most similar to my voice?
- Authors: Dabi Ahn(andabi412@gmail.com), Noah Jung, Jujin Lee and Kyubyong Park
- Demo: Check out who your voice is like!
Prologue
Everyone has their own voice. The same voice will not exist from different people, but some people have similar voices while others do not. This project aims to find individual voice vectors using VoxCeleb dataset, which contains 1,251 Hollywood stars' 145,379 utterances. The voice vectors are text-independent, meaning that any pair of utterances from same speaker has similar voice vectors. Also the closer the vector distance is, the more voices are similar.
Architectures
The architecture is based on a classification model. The utterance inputted is classified as one of the Hollywood stars. The objective function is simply a cross entropy between speaker labels from ground truth and predictions. Eventually, the last layer's activation becomes the speaker's embedding.
The model architecture is structured as follows.
- memory cell
- CBHG module from Tacotron captures hidden features from sequential data.
- embedding
- memory cell's last output is projected by the size of embedding vector.
- softmax
- embedding is logits for each classes.

Training
- VoxCeleb dataset used.
- 1,251 Hollywood stars' 145,379 utterances
- gender dist.: 690 males and 561 females
- age dist.: 136, 351, 318, 210, and 236 for 20s, 30s, 40s, 50s, and over 60s respectively.
- text-independent
- at each step, the speaker is arbitrarily selected.
- for each speaker, the utterance inputted is randomly selected and cropped so that it does not matter to text.
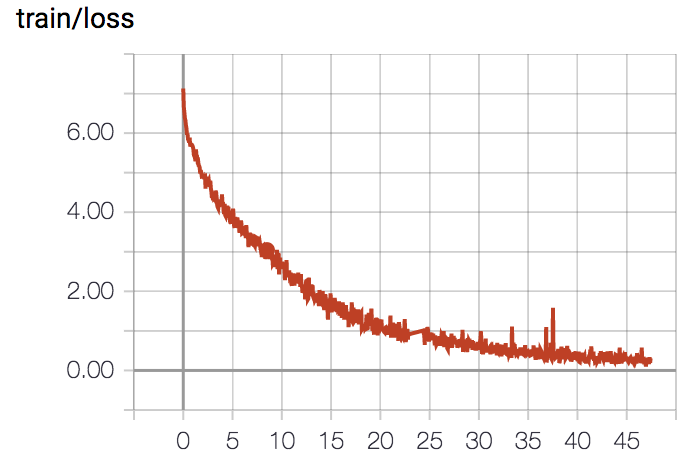
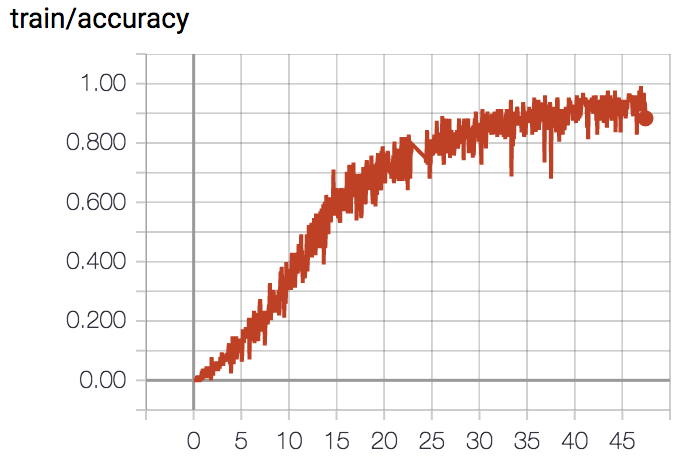
- loss and train accuracy
Embedding
- Common Voice dataset used for inference.
- hundreds of thousands of English utterances from numerous voice contributors in the world.
- evaluation accuracy
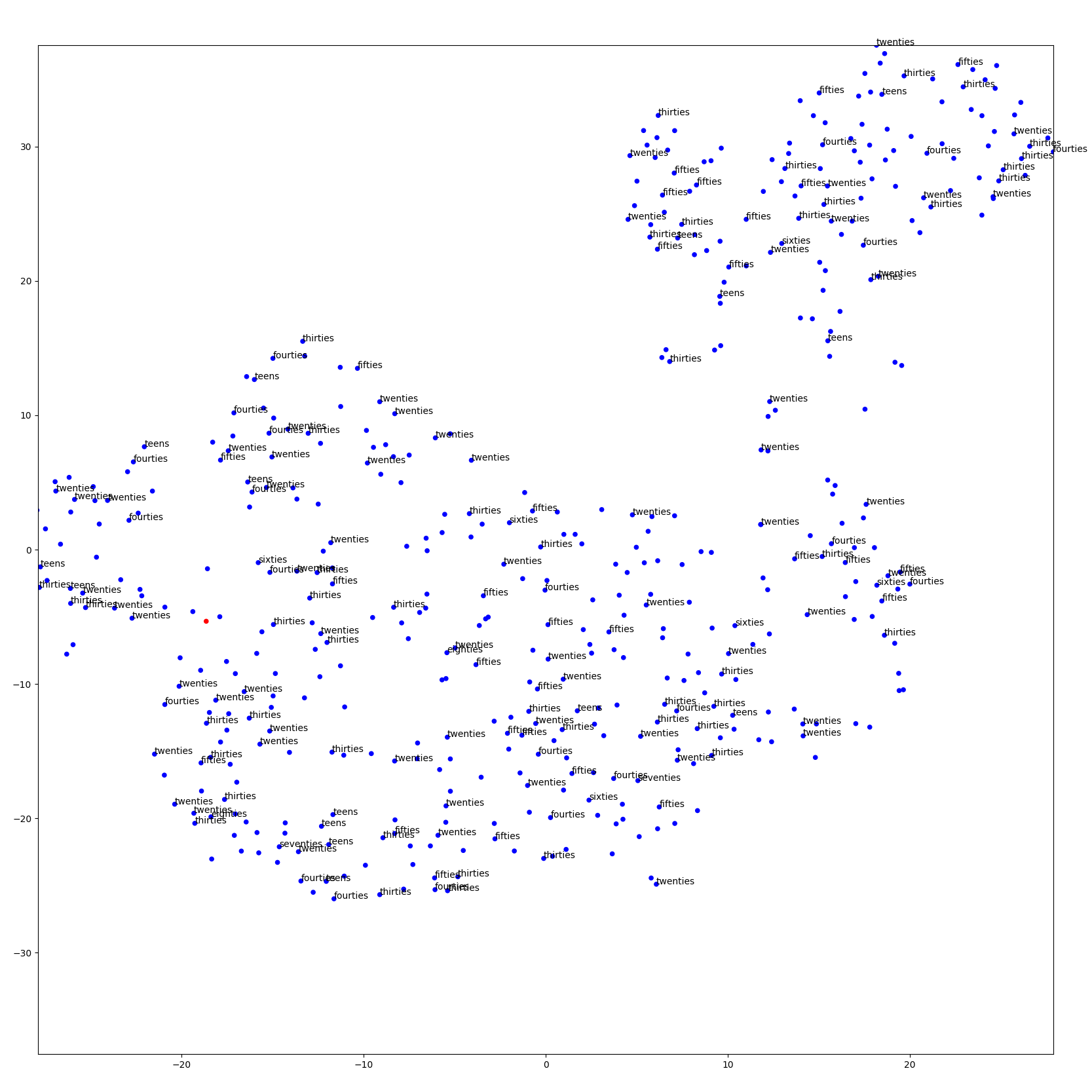
- embedding visualization using t-SNE
- voices are well clustered by gender without any supervision in training.
-
- but we could not find any tendency toward age.
-
- voices are well clustered by gender without any supervision in training.


How to run?
Requirements
- python 2.7
- tensorflow >= 1.1
- numpy >= 1.11.1
- librosa == 0.5.1
- tensorpack == 0.8.0
Settings
- configurations are set in two YAML files.
hparams/default.yamlincludes default settings for signal processing, model, training, evaluation and embedding.hparams/hparams.yamlis for customizing the default settings in each experiment case.Runnable python files
train.pyfor training.- run
python train.py some_case_name - remote mode: utilizing more cores of remote server to load data and enqueue more quickly.
- run
python train.py some_case_name -remote -port=1234in local server. - run
python remote_dataflow.py some_case_name -dest_url=tcp://local-server-host:1234 -num_thread=12in remote server.
- run
- run
eval.pyfor evaluation.- run
python eval.py some_case_name
- run
embedding.pyfor inference and getting embedding vectors.- run
python embedding.py some_case_nameVisualizations
- run
- Tensorboard
- Scalars tab: loss, train accuracy, and eval accuracy.
- Audio tab: sample audios of input speakers(wav) and predicted speakers(wav_pred)
- Text tab: prediction texts with the following form: 'input-speaker-name (meta) -> predicted-speaker-name (meta)'
- ex. sample-022653 (('female', 'fifties', 'england')) -> Max_Schneider (('M', '26', 'USA'))
- t-SNE output file
- outputs/embedding-[some_case_name].png
Future works
- One-shot learning with triplet loss.
References
- Nagrani, A., Chung, J. S., & Zisserman, A. (2017, June 27). VoxCeleb: a large-scale speaker identification dataset. arXiv.org.
- Zhang, C., & Koishida, K. (2017). End-to-End Text-Independent Speaker Verification with Triplet Loss on Short Utterances (pp. 1487–1491). Presented at the Interspeech 2017, ISCA: ISCA. http://doi.org/10.21437/Interspeech.2017-1608
- Li, C., Ma, X., Jiang, B., Li, X., Zhang, X., Liu, X., et al. (2017, May 6). Deep Speaker: an End-to-End Neural Speaker Embedding System. arXiv.org.