End-to-End-Learning-for-Self-Driving-Cars
Introduction
This is the third project of the Udactiy's Self-Driving Car Nanodegree. In this project, we trained a Convulutional Nerual Network model to learn to adjust the steering wheels to keep the car on the road. During training, the input to the model is the images aquired from three cameras behind the windshield of the simulated car. However during the test, we only rely on the images acquited from the central camera to steer the simulated car. The final test videos on the two track are here.
Software
Software requirements:
- numpy, flask-socketio, eventlet, pillow, h5py, keras, Tensorflow
- Simulator can be found at: Windows 64 bit Windows 32 bit macOS Linux
Steps to train and run the model
- Download the data here
- Train and run the model
python model.py
python drive.py model.json
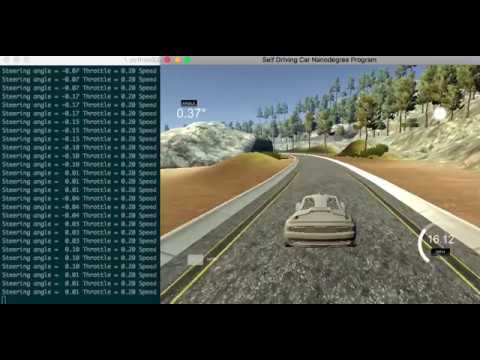
Finally open the simulator and select autonomous mode
The simulator front page

Data
The Training data can be dolownded from here. This is the training data on track one provided by Udacity. We did not collect our own data because of the difficulty of collecting data using keyborad.
Sample data from cameras:
 Statistics of the steering angles from Udacity data:
Statistics of the steering angles from Udacity data:

Augmentation/Preprocessing
From above, we can see that the training data is not banlanced, so we need augment it. I use three ways to augment/preprocess the data:
- Resize and change color space -resize the input image seize to (16,32), and change to HSV color channel. In the final architecures, We only use the S channel. I also tried used all three RGB or HSV channel but the S channel only produce the best results in my case.
- Use Left/right camera - Images from left/right camera are also used by modifiying the steering angle with 0.25. We should notice that, adding a constant angle to steering is a simplified version of shifting left and right cameras, but not the best way. But in our case, this simplificaiton is good enough.
- Flip the images - Flip the images from all three cameras to account for the situation of driving in the opposite way.This also increase our training data.
I also shuffle and split the data in to training(90%) and validation(10%) datasets. But the best way to validate and test the resultsing model is to run in on both track.
Because we resize the image size to (16,32), which largely reduced the training data size, we did not use the generator.
Model architecture
I start with the Nvidia End-to-end learning deep learning architecture. But it turns out that it is very difficult to train Nvidia models with our training data, because our data is not big enough to fully train the Nvidia model unless very heavy augmentation techquies is implemented, such as the discription here. Untill I saw the model of Mengxi Wu, he then wrote a article introducing his tiny model. I realized that I need a much smaller model compared Nvidia's, to better match my training data. Here is the model architecture which works in my case.
- Input data normorlization
- Convolution layer with 3x3 kernel and 1x1 stride
- relu activation layer
- MaxPooling with 2x2 pool size
- Convolution layer with 3x3 kernel and 1x1 stride
- relu activation layer
- MaxPooling with 2x2 pool size
- Dropout - Prevents overfitting.
- Flatten
- Dense layer with 50 neuron
- relu activation layer
- Dense layer with 1 neuron
Tuning and Hyperparameters
I have been trying to adopt SGD optimizer with learning rate 0.01, 0.001, 0.0005 and 0.0001,and also different batch size and training epoch. For batch size, I tried 64, 128 and 256; and training epoch ranging from 10 to 50. It is really a lot of work and you just have to try to see how the simulated car behave.
I found that: there is really no help to train more than 10 epochs even if the validation accuracy is keeping decrease; that Adam optimizer is better because of its adaptive learning rates; batch size 128 can do a good job.
So finnay I settled with Adam optimizer with default leraning rate 0.001, batch size 128 and traing epoch 10.