[中文|English]
Naive Bayes-based Context Extension
使用朴素贝叶斯思想来扩展LLM的Context处理长度。
现在,任何LLM都可以利用NBCE成为可以处理任意长Context的模型了(只要算力足够)!
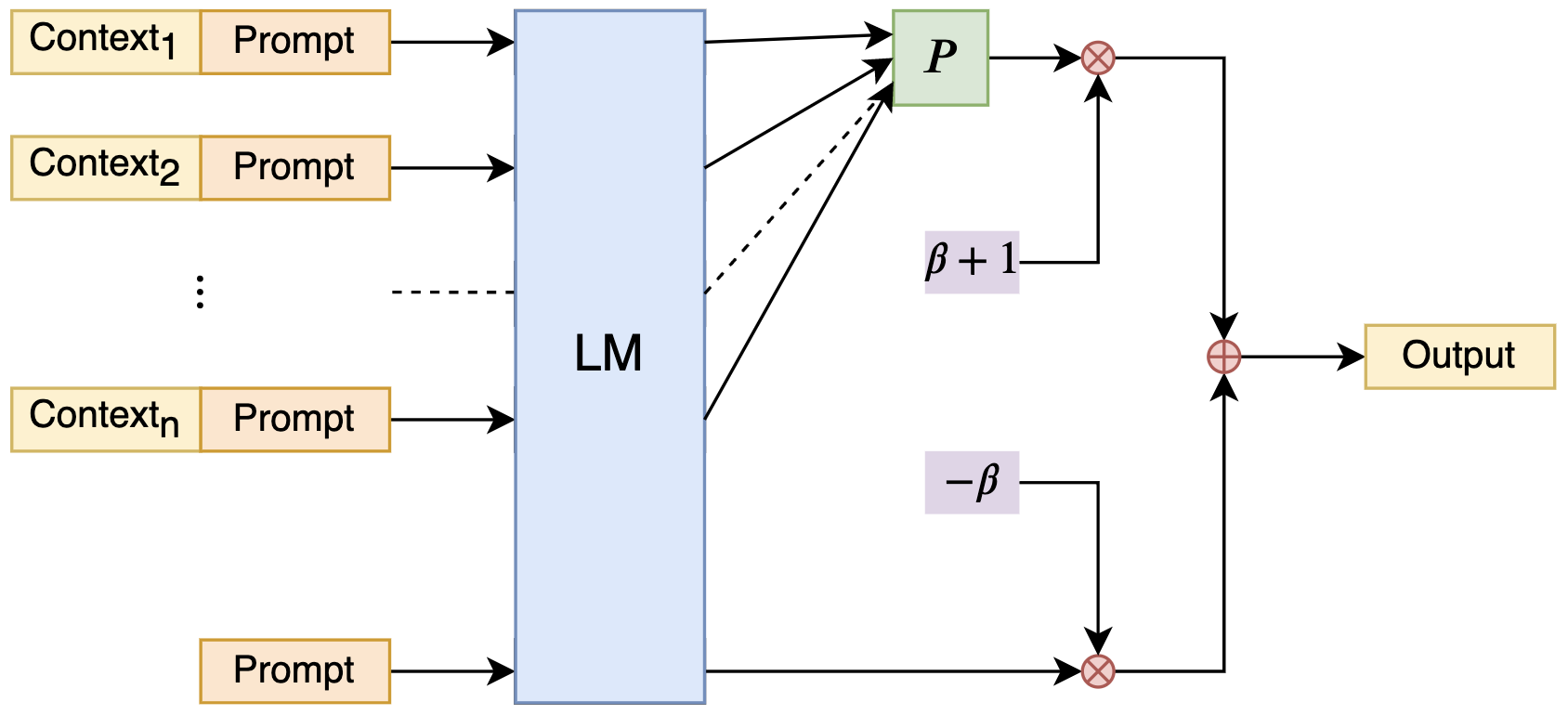
简介
基于朴素贝叶斯所启发的公式:
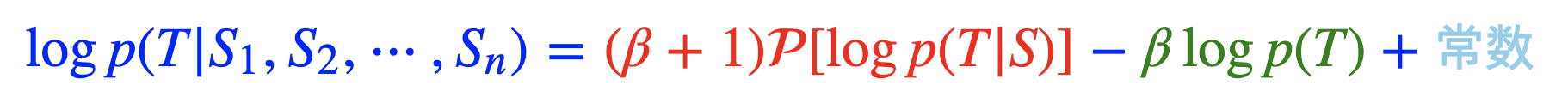
细节请看博客:https://kexue.fm/archives/9617
所给的Demo包含12段不同的Context,总长度为9000多字,连同8个问题一次性输入到模型中(测试模型训练长度为2048,参数量为7B,可以在OpenBuddy下载),模型能够逐一根据所给Context正确回答这8个问题。值得指出的是,所有的Context、问题和答案加起来,超过了1万字!另外,有朋友简单尝试了简历匹配和作文打分应用,效果也尚可,非常建议大家亲自调试一下。
最新测试结果:在8*A800下,7B模型可以处理50k的context,并能正确地做阅读理解。(没有用完所有GPU,大概消耗160G显存)
特点
- 即插即用
- 模型无关
- 不用微调
- 线性效率
- 实现简单
- 效果尚可
- 可解释性
引用
@misc{nbce2023,
title={Naive Bayes-based Context Extension},
author={Jianlin Su},
year={2023},
howpublished={\url{https://github.com/bojone/NBCE}},
}交流
QQ交流群:808623966,微信群请加机器人微信号spaces_ac_cn