
This repository is an open source caffe implementation of Spatio-Temporal Saliency Networks for Dynamic Saliency Prediction.
Abstract
Computational saliency models for still images have gained significant popularity in recent years. Saliency prediction from videos, on the other hand, has received relatively little interest from the community. Motivated by this, in this work, we study the use of deep learning for dynamic saliency prediction and propose the so-called spatio-temporal saliency networks. The key to our models is the architecture of two-stream networks where we investigate different fusion mechanisms to integrate spatial and temporal information. We evaluate our models on the DIEM and UCF-Sports datasets and present highly competitive results against the existing state-of-the-art models. We also carry out some experiments on a number of still images from the MIT300 dataset by exploiting the optical flow maps predicted from these images. Our results show that considering inherent motion information in this way can be helpful for static saliency estimation.
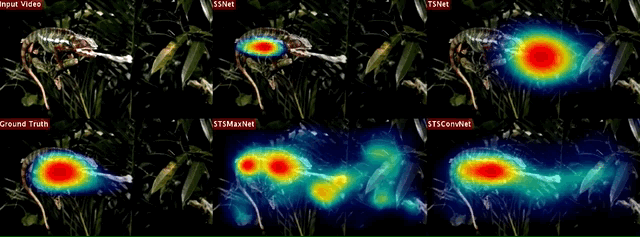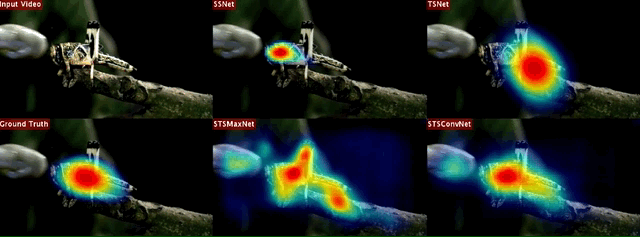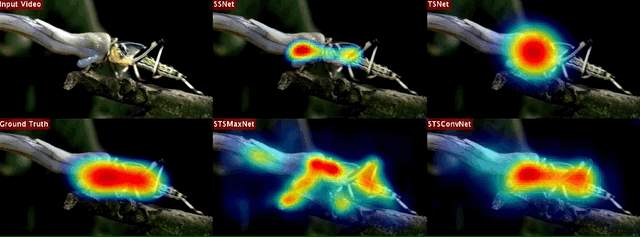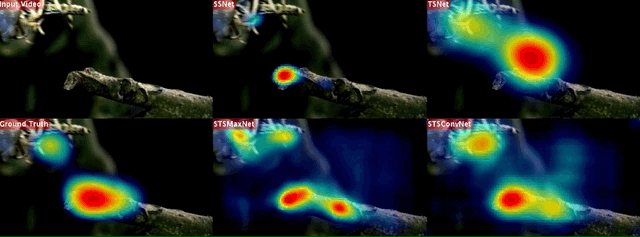
Proposed Network Architectures
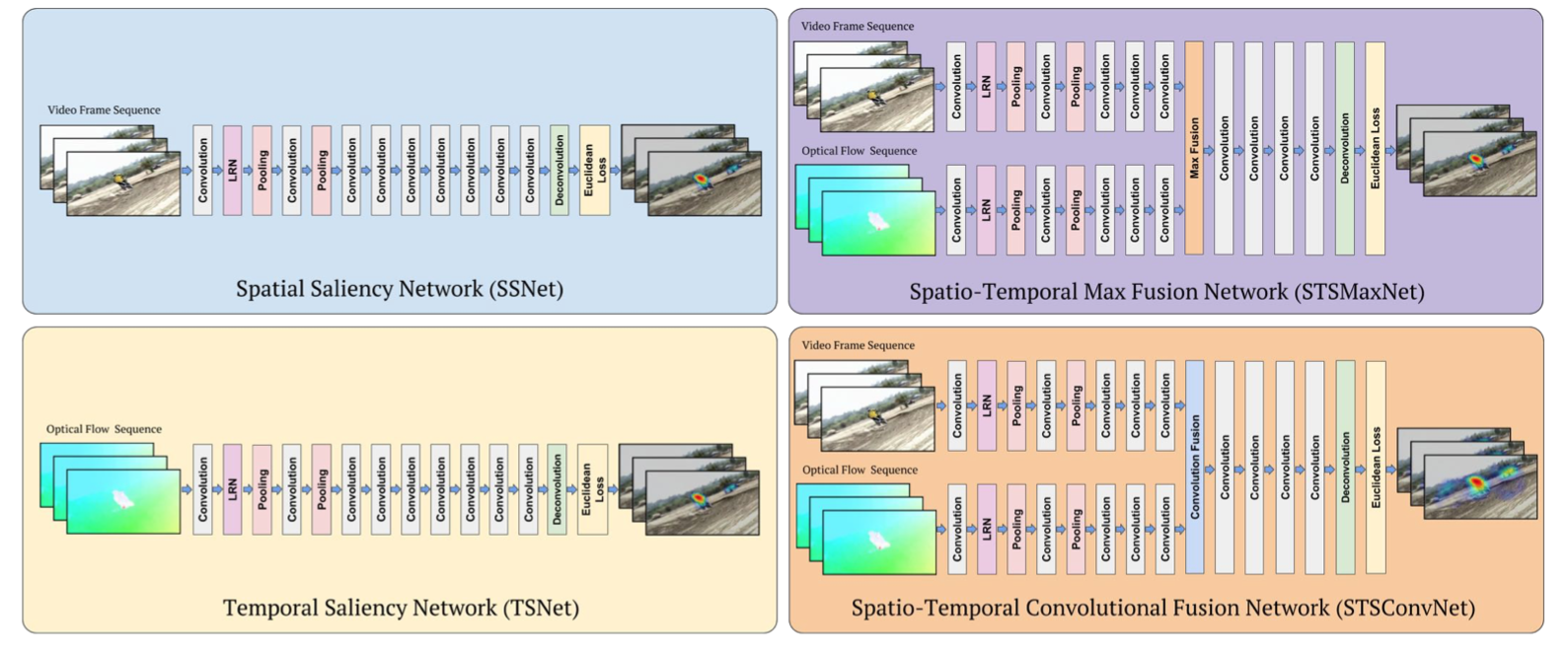
Right-on, The baseline single stream saliency networks. While SSNet utilizes only spatial (appearance) information and accepts still video frames, TSNet exploits only temporal information whose input is given in the form of optical flow images. Left-on, The proposed two-stream spatio-temporal saliency networks. STSMaxNet performs fusion by using element-wise max fusion, whereas STSConvNet employs convolutional fusion after the fifth convolution layers.
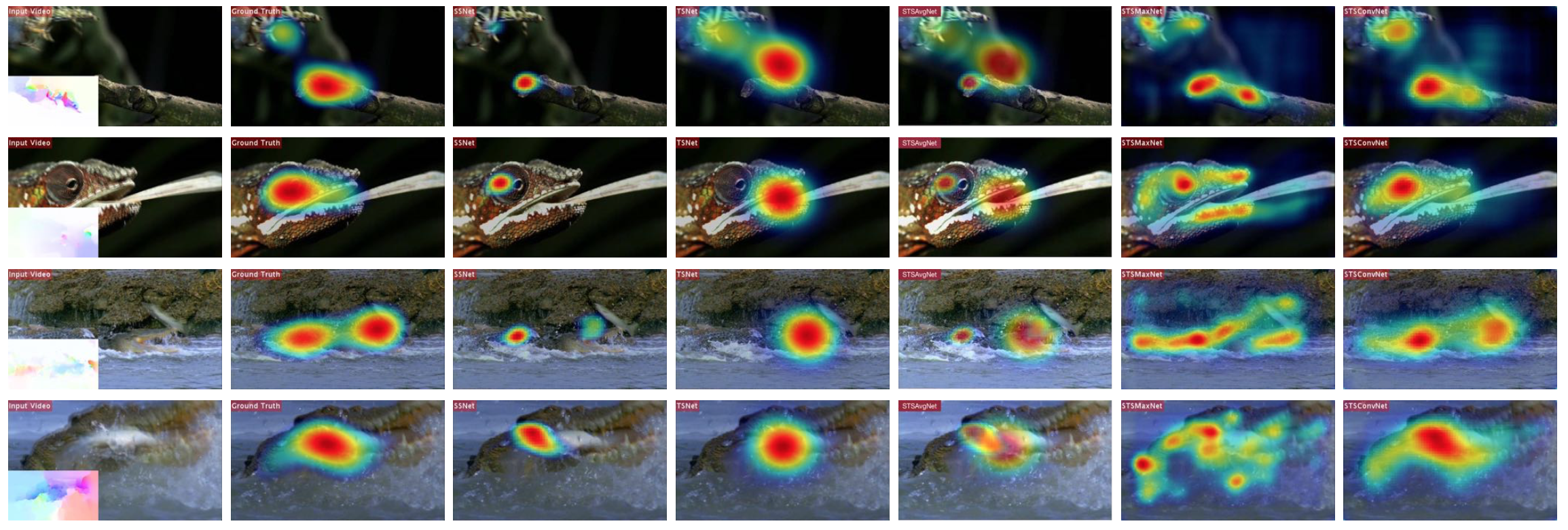
Results
Using instructions
./models/ : Pretrained caffe models (\w data augmentation) on DIEM dataset.
./prototxt/ : Caffe prototxt network architectures.
./scripts/ : Python scripts to generate saliency maps and to train networks.
Citation
 |
Paper accepted in IEEE Transactions on Multimedia |
|---|
Please cite our paper in your publications if it helps your research:
@ARTICLE{8119879,
author={C. Bak and A. Kocak and E. Erdem and A. Erdem},
journal={IEEE Transactions on Multimedia},
title={Spatio-Temporal Saliency Networks for Dynamic Saliency Prediction},
year={2017},
volume={PP},
number={99},
pages={1-1},
keywords={Computational modeling;Dynamics;Feature extraction;Predictive models;Videos;Visualization;deep learning;dynamic saliency},
doi={10.1109/TMM.2017.2777665},
ISSN={1520-9210},
month={},}
Authors
 |
 |
 |
 |
|---|---|---|---|
| Cagdas Bak | Aysun Kocak | Erkut Erdem | Aykut Erdem |
Contact
If you have any question, send an e-mail at cagdasbak@hotmail.com