llm-benchmarks
Benchmarking LLM Inference Speeds
(NEW) Dashboard
I now have a dashboard up and running to track the results of these benchmarks. I am using a combination of Docker with various frameworks (vLLM, Transformers, Text-Generation-Inference, llama-cpp) to automate the benchmarks and then upload the results to the dashboard. Most frameworks fetch the models from the HuggingFace Hub most downloaded or trending and cache them to my server storage which allows them to be loaded on-demand. The exception is the llama-cpp/GGUF framework that requires specially compiled model formats unique to the framework.
Dashboard is built in React and Node and utilizes MongoDB to store results.
Summary
A collection of benchmarks for various open-source models to get an idea of the relation between different models and the inference speeds we could hope to see. There are a few things to be aware of here:
This is likely on the lower-end of what to expect. I have performed no optimizations with software or hardware, just using HugginFace Transformers along with BitsAndBytes 4-bit/8-bit model loading.
Inference speeds scale with the log of the output token count. Speeds quickly drop with the first couple hundred tokens before leveling out around 1,000 (as far as I have tested so far). Also confusingly
Details
I used a few different methods to get complete results. First round was performed using OpenAI libraries in Python to make n calls and average those results. Next I wanted to test locally starting with my 3090. Using HuggingFace I was able to obtain model weights and load them into the Transformers library for inference. I force the generation to use varying token counts from ~50-1000 to get an idea of the speed differences. Next I rented some A10/A100/H100 instances from Lambda Cloud to test enterprise style GPUs. After a bit of fiddling with CUDA I was able to get some results quickly.
Results (Update 2023-06-18)
After looking at some other libraries I am realizing that the HuggingFace Transformers implementation of quantization using BitsandBytes is horribly ineficient. Here are some comparisons against GGML built with cuBLAS.
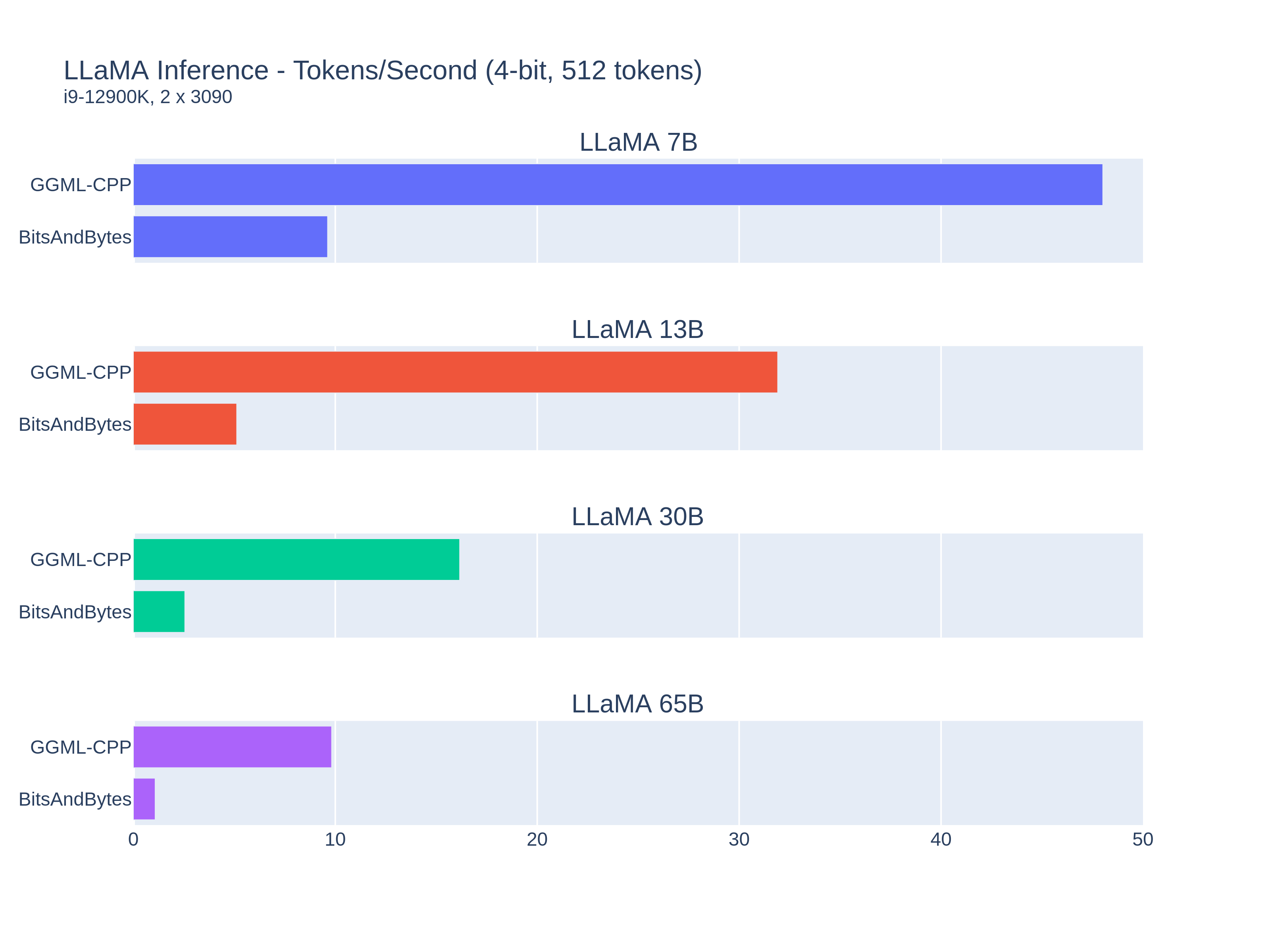
Results
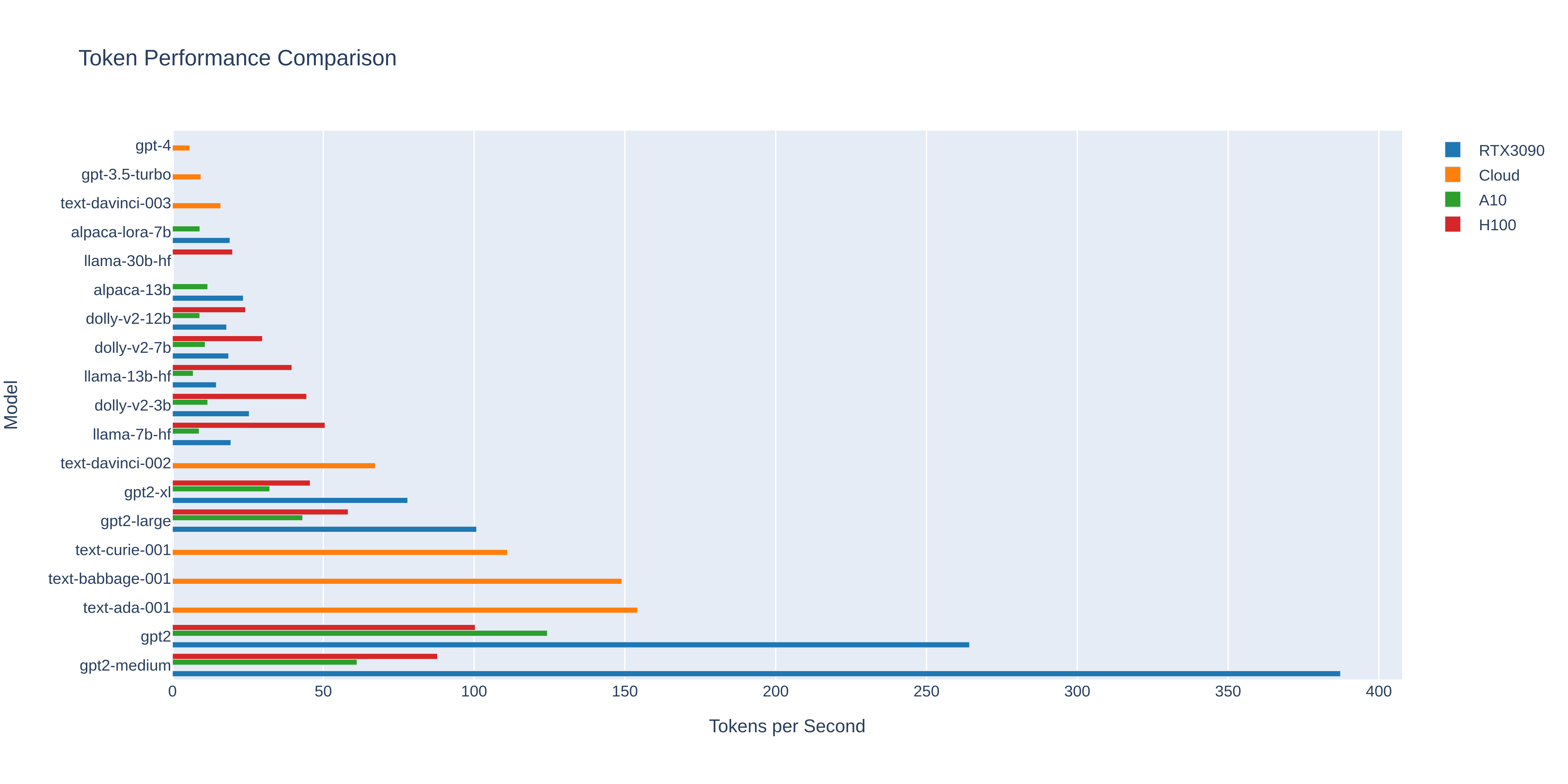
After running many tests with multiple GPUs and model sizes, results indicate that even the slowest performing combinations still handily beat GPT-4 and almost always match or beat GPT-3.5, sometimes significantly. The A10 performed poorly which surprised me given the larger tensor core count, I suspect something relating to the memory bandwidth. The H100 is much faster than anything else but costs ~$2.40 each hour to run. I will continue trying with other configurations as they are available online. A100 is equivalent or slower than a 3090 (weird right? User error?).
All Models (almost)
HEADS UP: This was performed before I managed to get consistent output token counts, so to reduce variability I just generated n outputs and averaged the results to get a final answer. Check the model specific plots at the bottom for a better idea of performance scaling.
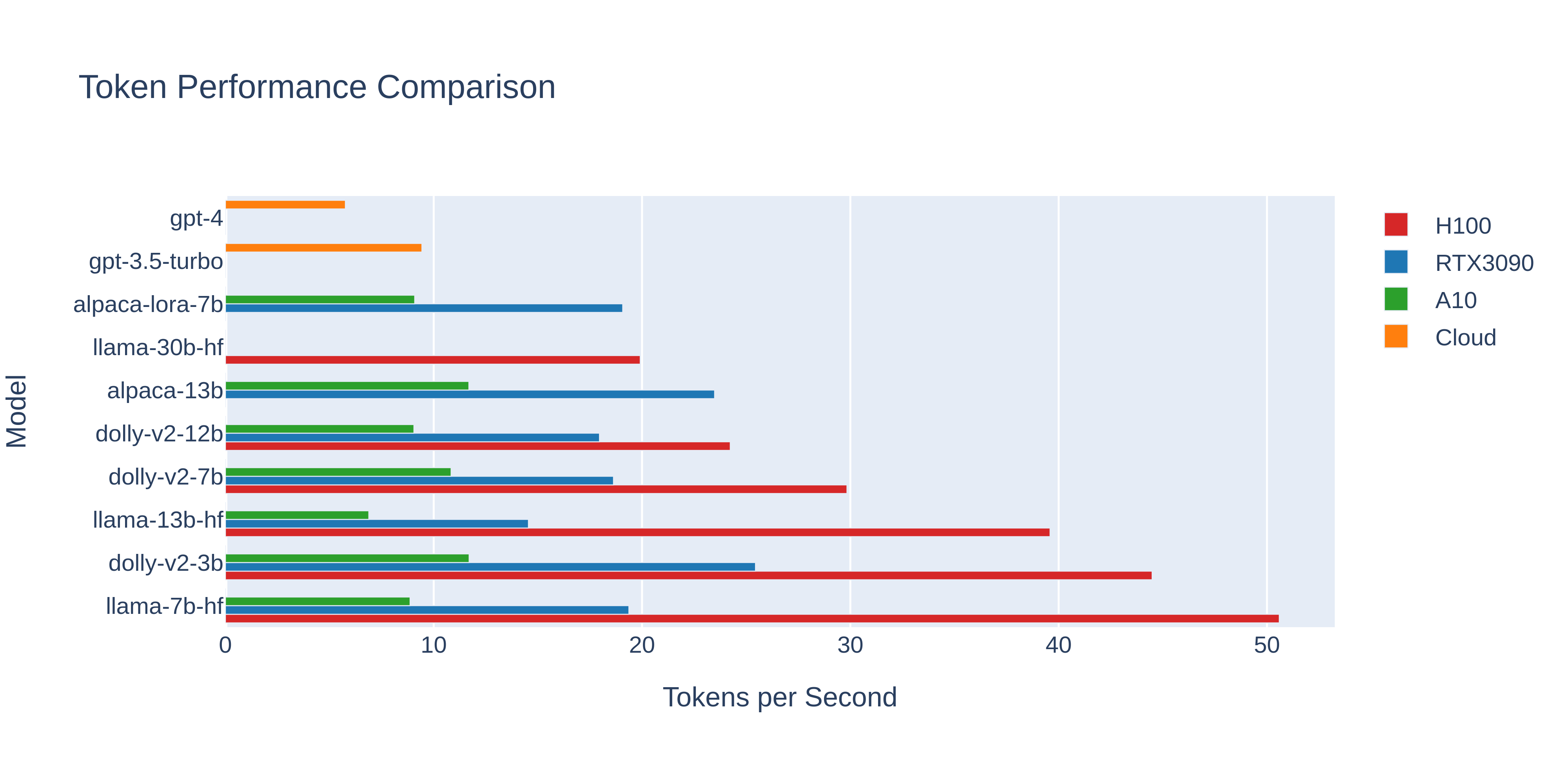
Most Relevant Models
This may be easier to read with a lot of the models we don't really care about removed.
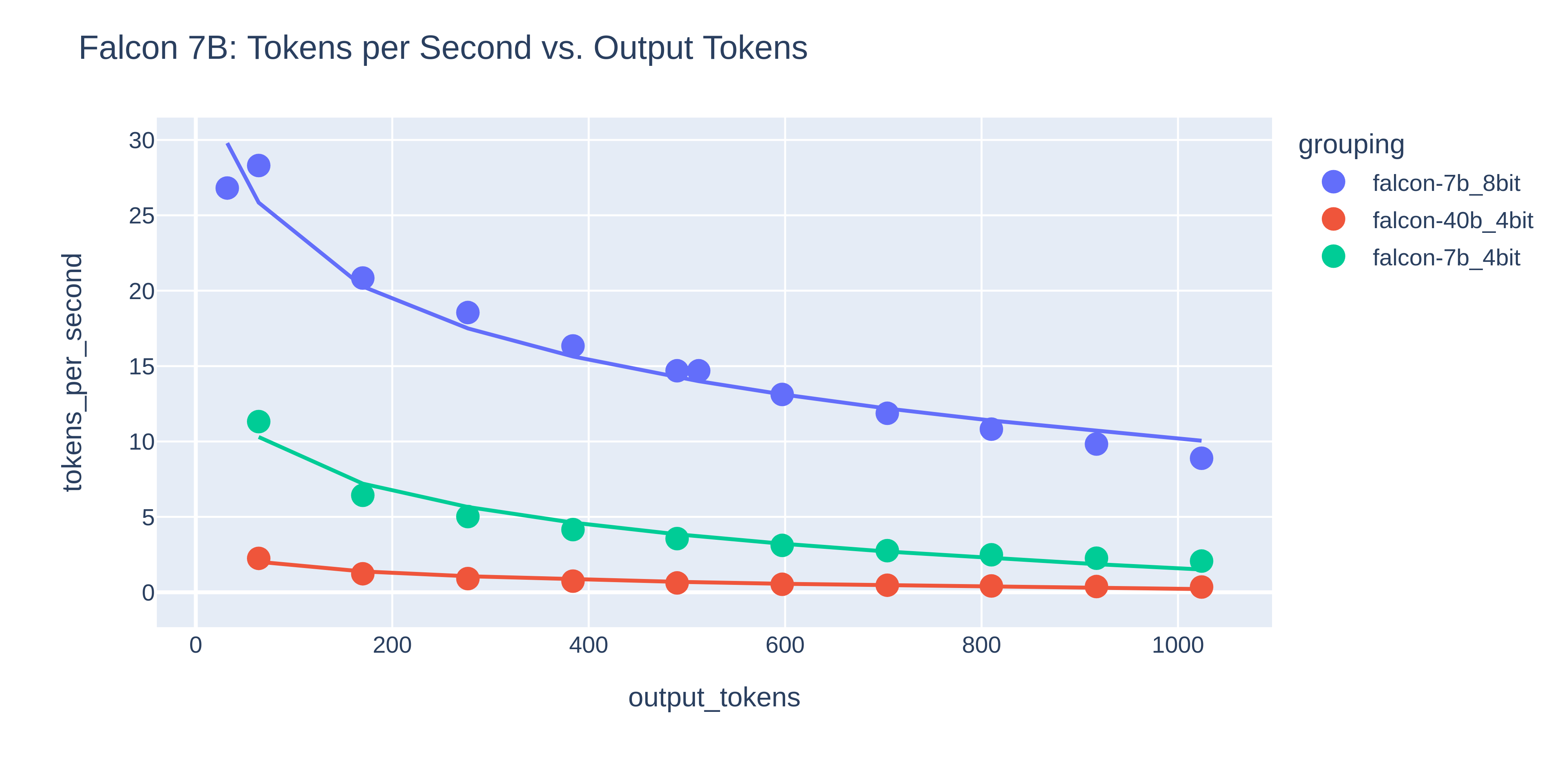
Comparing Speed with Output Tokens
This is designed to look at the effects of different sizes and inference speeds. These are my most recent tests and should be considered more accurate than the two above.
The below plots are from a 3090. I have A100 and H100 benchmarks coming soon.
LLaMA

Dolly-2

Falcon